
Outils Data
Avec le développement de l’IA, le Data Mesh s’impose comme un facilitateur pour l’entraînement de modèles et l’ingénierie de features. Analyse de Smartpoint, ESN spécialisée en data et IA, sur comment cette architecture décentralisée, en utilisant Genie de Databricks, révolutionne la gestion des données et booste l’adoption de l’IA. Nous verrons aussi l’intégration Genie Databricks dans le Data Mesh.
Qu’est-ce que le Data Mesh ?
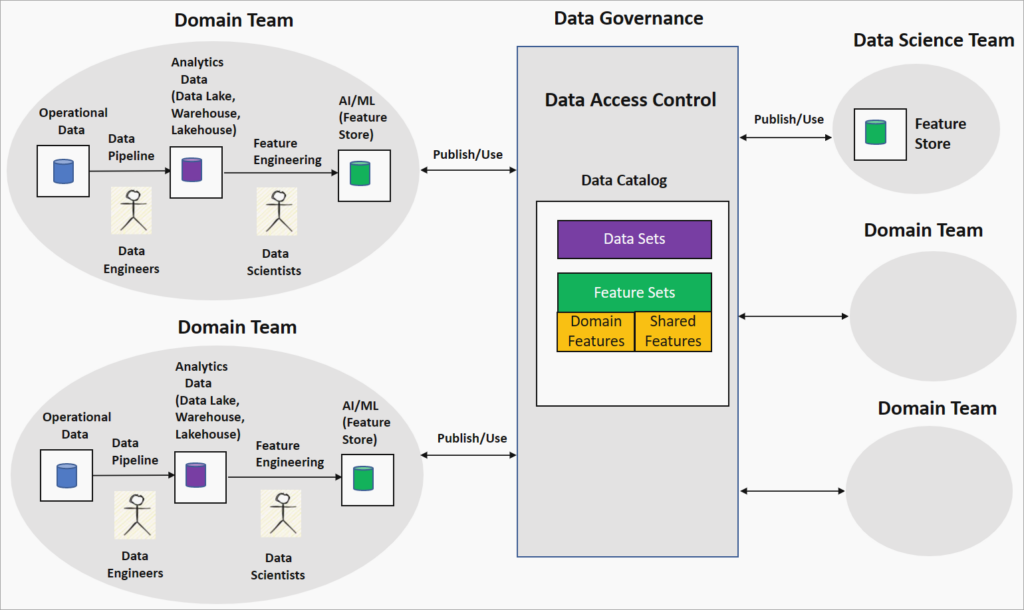
Le Data Mesh est une approche organisationnelle et architecturale qui repense la gestion des données à grande échelle pour en tirer une valeur maximale. Contrairement aux architectures Data traditionnelles basées sur des data lakes ou data warehouses, souvent centralisées et générateurs des fameux silos, le Data Mesh répartit la propriété et la gestion des données entre différents domaines métier (ventes, finance, marketing, etc.). Cette décentralisation permet aux équipes de gérer leurs données de manière autonome tout en respectant des règles de gouvernance centralisées pour garantir interopérabilité, sécurité et cohérence sémantique.
Pour approfondir : Concepts et architecture du Data Mesh
- Propriété par domaine : Chaque domaine métier prend en charge l’intégralité du cycle de vie de ses données, favorisant une expertise métier approfondie et une meilleure agilité.
- Gouvernance fédérée : Une gouvernance centralisée, appuyée par des outils comme les data catalogs, assure le respect des normes organisationnelles et réglementaires tout en laissant les domaines opérer de manière autonome. À lire : Gouvernance fédérée et architectures distribuées
- Data as a product : Les données sont traitées comme des produits, avec des principes de gestion pour les rendre « découvrables », fiables, auto-descriptifs et interopérables ; afin de maximiser leur valeur
- Plateforme en libre-service : Une infrastructure automatisée permet aux équipes de créer et maintenir leurs data products sans dépendance excessive aux équipes IT centrales.
Ces principes cassent les silos et accélèrent la livraison de valeur métier, rendant le Data Mesh particulièrement adapté à l’ère de l’IA.
Le Data Mesh et IA
Avec la montée en puissance de l’IA, le Data Mesh agit comme un catalyseur : il facilite l’entraînement des modèles (deep-learning, machine learning) et l’optimisation des features. En décentralisant la gestion des données, il permet aux domaines de développer leurs propres modèles IA/ML en s’appuyant sur des data products spécifiques à leur métier. Par exemple, dans un environnement Azure, le Data Mesh facilite la transition d’un data lake centralisé vers des domaines décentralisés, optimisant l’ingénierie des features pour des cas d’usage métier précis.
Source: Operationalize Data Mesh for AI/ML Domain-Driven Feature Engineering
Pourquoi le Data Mesh est un socle pour l’IA ?
Alors que l’intelligence artificielle (IA), le machine learning et l’IA générative redéfinissent les stratégies data-driven, le Data Mesh s’impose comme une architecture des données incontournable. En brisant les silos des data lakes traditionnels, cette approche décentralisée favorise une gouvernance fédérée, une propriété par domaine et des data products interopérables, créant un socle robuste pour l’IA à grande échelle.
- Fluidité des échanges de données : Les domaines partagent des données cohérentes et bien structurées, éliminant les incohérences qui ralentissent les modèles IA.
- Fondation pour l’IA générative : Le Data Mesh, combiné à l’IA générative, forme un tandem dynamique pour gérer les données à grande échelle, rendant les données accessibles et exploitables pour des insights rapides. Comme le souligne une analyse récente, cette synergie accélère la production de valeur dans des environnements complexes. À lire sur ce sujet : Data Mesh and Generative AI: The Dynamic Duo for Data Management at Scale
- Démocratisation de l’IA : Selon notre expérience chez Smartpoint auprès des entreprises, très peu déploient l’IA générative à grande échelle. Selon nos architectes Data, le Data Mesh dynamise son adoption en rendant les données accessibles aux équipes non techniques.
Genie de Databricks 2025 : Solution innovante IA pour data mesh
Genie de Databricks est une interface innovante d’AI/BI qui permet aux utilisateurs métier d’interagir avec leurs données via le langage naturel, générant des insights et des data visualisations instantanés. Contrairement aux outils BI classiques, Genie agit comme un analyste IA évolutif, capable d’apprendre des retours utilisateurs, d’affiner ses réponses et d’intégrer des instructions expertes pour des analyses précises. Et Genie respecte l’EU AI Act via Unity Catalog pour audits et traçabilité !
Lancé en juin 2025, Genie s’appuie sur la Data Intelligence Platform de Databricks et Unity Catalog pour une gouvernance intégrée. Ses principales fonctionnalités incluent :
- Questions-réponses en langage naturel : Posez des questions comme « Pourquoi les ventes ont-elles baissé la semaine dernière ? » pour obtenir des réponses sous forme textuelle, tabulaire ou visuelle.
- Raisonnement agentique : Genie résout les ambiguïtés et s’améliore grâce aux interactions.
- Instructions expertes : Intégrez des requêtes SQL, des définitions de métriques ou des exemples pour des résultats précis.
- Suivi et optimisation : Surveillez l’usage, évaluez la précision et intégrez des retours pour une amélioration continue.
- Intégrations : Importation de fichiers (Excel, CSV), API pour des outils comme Slack, et mode Deep Research (en preview) pour des analyses complexes.
Pour en savoir plus sur Genie de Databricks : AI/BI Genie is now Generally Available – AI/BI Genie de Databricks
Intégration de Genie dans une architecture Data Mesh
Genie s’intègre parfaitement au Data Mesh en transformant les data products statiques en interfaces dynamiques et intelligentes. Sur Databricks, il agit comme un catalyseur en s’alignant sur les principes de propriété par domaine et de Data as a product.
- Propriété par domaine : Chaque domaine configure ses propres Genie Spaces sur ses tables Unity Catalog, intégrant une logique métier spécifique (ex. : définitions d’année fiscale pour la finance). Ces espaces sont gérés par les équipes métier avec des instructions et des exemples pour une compréhension sémantique optimale.
- Données comme « produit interactif » : Genie enrichit les data products avec des métadonnées (lignage, descriptions), garantissant des réponses fiables et traçables. Il transforme les tables Delta Lake en produits « découvrables » et auto-descriptifs, renforçant leur valeur métier.
- Modèle Hub-and-Spoke ou harmonisé : Dans une architecture Data Mesh sur Databricks, les domaines opèrent dans des workspaces dédiés, avec un hub central pour la gouvernance. Genie peut être déployé par domaine (ex. : Genie Ventes, Genie Supply Chain) et orchestré via un Master Genie pour des analyses inter-domaines, formant un « Genie Mesh » multi-agent.
Lire l’article Comment intégrer Genie (Databricks AI/BI) dans votre architecture Data Mesh : How to Fit Genie (Databricks AI/BI) in Your Data Mesh
Exemple : Un domaine Marketing peut exposer un Genie Space pour ses données de campagnes publicitaires, tandis qu’un Master Genie agrège des insights cross-domaines pour des analyses globales, comme la performance globale des initiatives marketing et commerciales.
Avantages et limites
Avantages
- Démocratisation : Accès en libre-service aux insights IA, réduisant la dépendance aux équipes data centrales.
- Gouvernance renforcée : Intégration avec Unity Catalog pour une sécurité et un lignage fédérés.
- Scalabilité : Prise en charge de grands volumes de données sans réplication, accélérant les décisions métier.
- Innovation IA : Facilite l’entraînement et l’utilisation d’agents IA sur des données décentralisées.
Limites
- Complexité initiale : Configurer les Genie Spaces nécessite une expertise en métadonnées et instructions métier.
- Adoption : Former les utilisateurs métier à interagir avec l’IA peut représenter un défi.
- Précision : Bien que Genie réduise les erreurs (hallucinations), des benchmarks réguliers sont nécessaires pour garantir la fiabilité.
À lire : My Take on Databricks Genie (AI/BI): A Double-Edged Sword for Data Professionals
Cas d’usage concrets
- Retail : Un Genie Supply Chain anticipe les ruptures de stock, intégré à un Master Genie pour corréler avec les données de ventes.
- Santé : Premier Inc. utilise Genie pour des analyses rapides sans codage, améliorant la prise de décision.
- Finance : Analyse des pipelines de ventes en langage naturel, comme chez HP ou 7-Eleven, pour des insights instantanés.
Alternatives à Genie : Solutions recommandées par Smartpoint
Chez Smartpoint, nous accompagnons nos clients dans le choix d’outils AI/BI adaptés à leur maturité data et leur architecture de données (comme le Data Mesh). Si Genie de Databricks est particulièrement adapté aux environnements Lakehouse ouverts, d’autres solutions offrent des complémentarités intéressantes pour une IA générative décentralisée. Voici deux alternatives intéressantes selon nos experts Data/IA dans une architecture data mesh :
Snowflake Cortex AI (via l’acquisition d’Applica)
Snowflake propose une plateforme unifiée pour la gestion des données et l’IA générative, particulièrement adaptée aux environnements multi-cloud. Grâce à l’acquisition d’Applica en septembre 2022, Snowflake a intégré Document AI, un modèle de langage multimodal (LLM) qui extrait des insights profonds de documents non structurés (PDF, images, etc.), les rendant exploitables pour des apps IA personnalisées. Idéal pour les domaines traitant de données hybrides (structurées/non structurées), avec une gouvernance fédérée via Snowflake Horizon Catalog. Recommandé pour les entreprises en transition vers l’IA scalable, sans migration lourde.
En savoir plus : Snowflake Document AI
Microsoft Power BI Copilot
Intégré à l’écosystème Microsoft, Power BI Copilot transforme l’analyse BI en conversation naturelle, permettant aux utilisateurs métier de poser des questions en langage courant pour générer tableaux, visualisations et résumés automatisés. Il assiste aussi les développeurs dans la création de rapports narratifs et l’optimisation de modèles sémantiques via des suggestions IA. Parfait pour les organisations Azure-centric, avec une intégration fluide aux domaines décentralisés (via Fabric). Il démocratise l’IA en réduisant le besoin de codage, idéal pour une adoption rapide par les équipes non techniques.
En savoir plus : Copilot in Power BI
| Critère | Genie de Databricks | Cortex AI de Snowflake | Power BI Copilot |
| Fonctionnalités clés | Interface conversationnelle en langage naturel pour Q&R sur données (insights textuels, tabulaires, visuels). Raisonnement agentique, instructions expertes (SQL/métriques), surveillance des feedbacks. Focus sur l’analyse prédictive et l’IA générative intégrée (Mosaic AI). Idéal pour data scientists et analystes. | Suite AI pour services financiers/entreprises : extraction d’insights de documents non structurés (Document AI), agents de data science (nettoyage, feature engineering), Cortex Analyst pour requêtes SQL en NL. Intègre LLMs comme Claude 3.5 Sonnet. Fort sur l’analyse multimodale (images, PDF). | Assistant IA pour rapports BI : génération de visualisations, résumés et DAX via NL. Aide à la création de rapports narratifs et à l’exploration de datasets. Intègre Copilot Studio pour agents personnalisés. Plus orienté BI visuelle que pure analyse data. |
| Intégration Data Mesh | Excellente : Aligné sur les principes (propriété par domaine via Genie Spaces sur Unity Catalog). Supporte hubs-and-spoke pour gouvernance fédérée, lignage end-to-end et autonomie des domaines. Facilite les « Genie Mesh » multi-agents pour analyses cross-domaines. | Bonne : Horizon Catalog pour gouvernance unifiée (métadonnées, permissions RBAC). Intègre avec domaines décentralisés via Snowpark, mais plus centralisé. Adapté pour data products interopérables, avec focus sur silos brisés multi-cloud. | Moyenne : Intégration via Microsoft Fabric pour domaines Azure-centric. Supporte gouvernance fédérée (Purview), mais moins natif pour Data Mesh décentralisé. Bon pour équipes métier, mais nécessite plus de customisation pour inter-domaines. |
| Tarification | Inclus dans la plateforme Data Intelligence (pay-as-you-go sur DBUs, ~0,07-0,55 €/DBU selon cluster). Pas de surcoût pour Genie ; scalabilité élastique. Coûts variables selon usage (ex. : 1-5 €/heure pour clusters AI). | Inclus dans Snowflake (crédits par seconde de compute, ~2-5 €/crédit). Cortex Analyst gratuit pour usages basiques ; surcoût pour LLMs avancés (~0,01-0,10 €/1k tokens). Modèle prévisible, mais potentiellement élevé pour gros volumes. | Inclus dans Power BI Premium (~10-20 €/utilisateur/mois) ou Fabric (~0,36 €/capacité/heure). Surcoût pour Copilot Studio (~200 €/utilisateur/mois). Abordable pour PME, mais lié à l’écosystème Microsoft. |
| Conformité EU France AI Act / Data Act | Haute : Unity Catalog pour traçabilité et gouvernance (lignage, audits). Supporte AI Pact volontaire ; tests contre biais/hallucinations. Respecte Data Act via portabilité (Delta Lake open-source) et résidence EU. Intégration OneTrust pour mapping automatique aux normes (NIST, ISO 42001). | Haute : Horizon pour sécurité/compliance (RBAC, pas d’entraînement sur données clients). Cortex pour Finserv respecte régulations sectorielles ; aligné AI Act (risques inacceptables prohibés). Data Act via interopérabilité multi-cloud et portabilité (Iceberg). Focus sur privacy-by-design. | Très haute : Engagement Microsoft pour conformité totale (principes : fairness, privacy, accountability). Outils comme Purview pour audits RGPD/AI Act ; monitoring continu des biais. Data Act via portabilité Fabric et résidence Azure EU. Exemptions open-source pour bas risques. |
| Forces pour le marché français | Flexibilité pour ESN comme Smartpoint : idéal pour implémentations custom Data Mesh/IA en multi-cloud (AWS/Azure/GCP). Scalable pour startups tech parisiennes. | Simplicité pour secteurs réglementés (banque, santé) : souveraineté data multi-cloud, adapté aux contraintes CNIL. Bon pour portabilité Data Act. | Intégration native Azure (régions FR) : parfait pour entreprises Microsoft-centric (SME/GE). Facilite adoption rapide avec formation RGPD intégrée. |
| Limites | Courbe d’apprentissage pour non-data engineers ; coûts variables sur gros clusters. | Moins mature pour ML avancé (dépend d’intégrations tierces). | Limité à écosystème Microsoft ; moins flexible pour Data Mesh pur. |
Ces solutions, comme Genie, s’alignent sur les principes du Data Mesh en favorisant l’autonomie des domaines et l’interopérabilité pour une architecture data moderne. Chez Smartpoint, nous évaluons ensemble la meilleure stack Data dans votre cas spécifique en conformité aux réglementations EU. Un POC gratuit pour tester l’intégration ? Contactez-nous.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels,
Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Vos questions sur le Data Mesh et IA Générative
Qu’est-ce que le Data Mesh ?
Le Data Mesh est une architecture de données décentralisée qui répartit la propriété des données entre les domaines métier. Contrairement aux data lakes centralisés, il favorise l’autonomie des équipes via des data products interopérables, soutenus par une gouvernance fédérée. En France, il accélère l’innovation data-driven en cassant les silos, tout en respectant l’AI Act et le Data Act pour la traçabilité et la portabilité des données. Smartpoint accompagne les entreprises dans leur transition vers cette architecture scalable.
Qu’est-ce qu’une gouvernance fédérée ?
La gouvernance fédérée conjugue autonomie des domaines et normes centralisées. Dans un Data Mesh, chaque domaine gère ses données (qualité, accès) mais un data catalog (ex. : Unity Catalog) harmonise sécurité, lignage et conformité (RGPD, Data Act). Cela garantit l’intéropérabilité et réduit les risques réglementaires essentiels en France soumis à l’ AI Act. Smartpoint déploie des solutions comme Databricks ou Snowflake pour une gouvernance robuste avec audits CNIL-ready.
Comment intégrer Genie Databricks dans un Data Mesh ?
Genie de Databricks transforme les data products en interfaces IA conversationnelles. Chaque domaine configure des Genie Spaces sur Unity Catalog, intégrant une logique métier (ex. : métriques financières). Un Master Genie orchestre les analyses inter-domaines, formant un « Genie Mesh ». En France, cette intégration respecte l’EU AI Act (traçabilité, audits) et accélère les insights pour les PME. Smartpoint propose des POC pour tester Genie dans une architecture Data Mesh.
Quelles solutions IA générative en France ?
En 2025, plusieurs solutions IA générative s’intègrent au Data Mesh pour les entreprises françaises :
Genie de Databricks : Interface AI/BI pour analyses en langage naturel, conforme EU AI Act via Unity Catalog. Idéal pour multi-cloud.
Snowflake Cortex AI : Performant dans l’extraction de données non structurées (Document AI), avec conformité Data Act via Horizon Catalog.
Microsoft Power BI Copilot : Génère rapports BI via Azure, avec audits RGPD via Purview. Parfait pour entreprises Microsoft-centric. Smartpoint recommande des solutions avec résidence EU (ex. : régions Azure FR) pour répondre aux exigences CNIL.












