Non classé

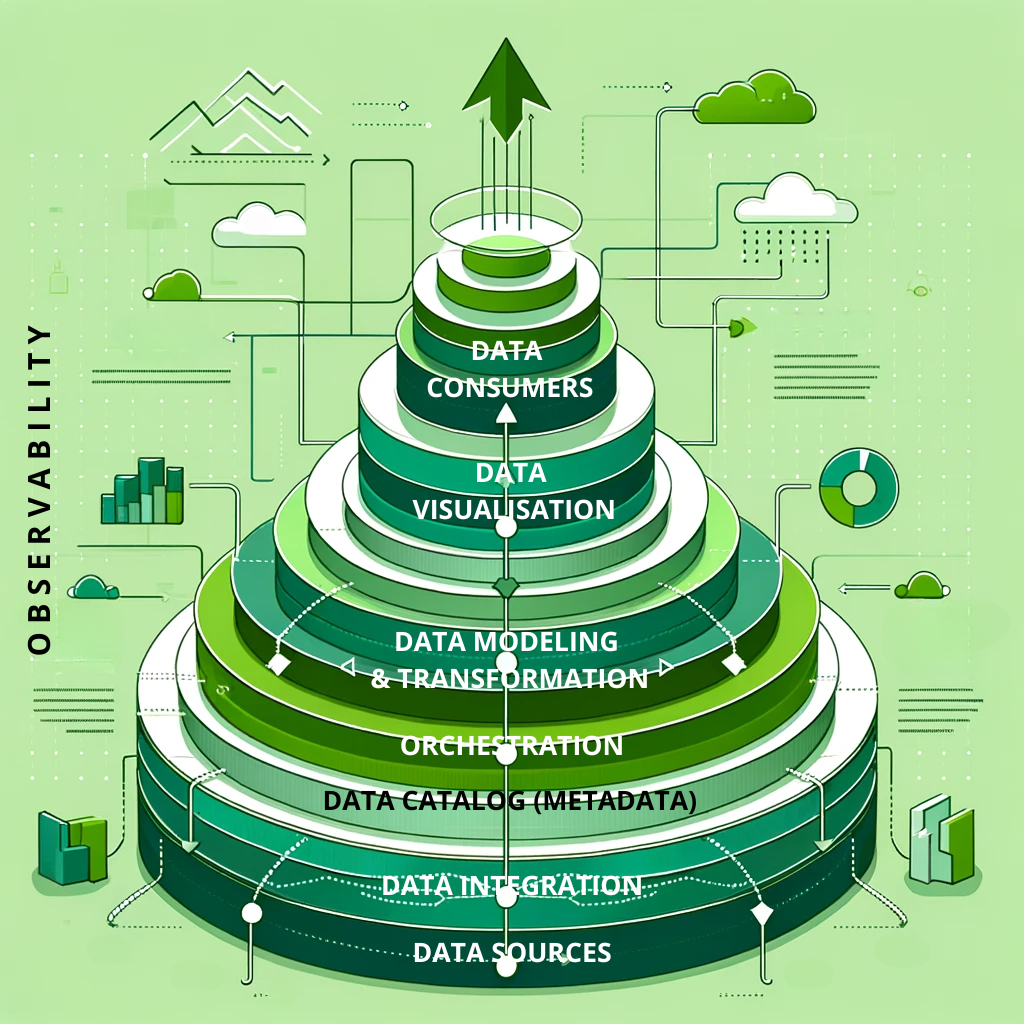
La data fabric permet aux entreprises d’intégrer, de gérer, d’exploiter et d’analyser un volume toujours plus important de données issues de multiples sources (datalakes, applications, bases de données traditionnelles, plateformes cloud, etc.) en temps réel, en utilisant la puissance de l’IA et du ML pour automatiser notamment le traitement des données mais aussi le génération d’insights.
Elle permet surtout de rapprocher les consommateurs de données avec ceux qui sont en charge de son ingénierie !
Comment est ce que la Data Fabric améliore la gouvernance des données ? C’est dans le concept même de cette architecture. Rappelons en effet que les données sont traitées comme un produit et sont d’ailleurs nommées « Data Product ». Chaque data product est conçu comme la plus petite entité cohérente possible afin de favoriser la ré-usabilité des données dans différentes contextes ou usages de consommation.
Les données sont un actif développé, testé et mis à disposition d’utilisateurs qui les consomment. Chaque Data Product est sous la responsabilité d’une équipe propriétaire indépendante qui connait le domaine. Elle se porte garante de sa création, de son intégrité, de sa qualité, de son accessibilité, du delivery et de sa durabilité.
Les données sont créées via l’utilisation de modèles standardisés selon des normes de qualité. Elles sont donc testées pour s’assurer de leur fiabilité et de leur interopérabilité.
La Data Fabric vous permet d’avoir une vue d’ensemble unifiée de toute l’infrastructure data car toutes les données sont lisibles au même endroit. Les données sont interconnectées, fédérées et sécurisées.
Cette approche permet enfin de lutter efficacement sur les silos, de réduire les doublons de données, d’éliminer des cohérences et la sous-exploitation des données collectées. C’est également une meilleure optimisation du stockage et des ressources nécessaires au traitement.
Les utilisateurs ont également un accès facilité à des données temps réel, ce qui leur permet de tester, d’explorer, de découvrir des tendances, d’itérer plus rapidement et donc d’innover ou de réagir plus vite.
Réalisé avec DALL-E
Quels sont les principaux challenges pour intégrer votre Data Fabric ?
- Complexité du Data Legacy qui ne permet pas l’interopérabilité et manque de flexibilité (et d’évolutivité)
- Interopérabilité et standardisation alors que les entreprises ont de multiples outils et utilisent aujourd’hui plusieurs plateformes
- Qualité des données et cela suppose souvent un chantier de nettoyage, redressement et normalisation qui peut être long
- Intégration de sources diverses, disparates et généralement en silos
- Gouvernance nécessaire et souvent complexe (gestion des métadonnées, compliance, sécurité, etc.) dans un environnement par nature distribué et dynamique
- Manque de compétences en interne car c’est une approche best-of-breed
- Résistance au changement
- Maintenance continue dans la durée
Vous souhaitez mettre en place votre data fabric, nous réalisons avec vous votre projet pilote pour démontrer son efficacité. Contactez-nous.
