LnRiLWNvbnRhaW5lciAudGItY29udGFpbmVyLWlubmVye3dpZHRoOjEwMCU7bWFyZ2luOjAgYXV0b30gLndwLWJsb2NrLXRvb2xzZXQtYmxvY2tzLWNvbnRhaW5lci50Yi1jb250YWluZXJbZGF0YS10b29sc2V0LWJsb2Nrcy1jb250YWluZXI9ImY2ZTMwMDZjMmI0ZGZlNzNjNGYyMWM0Y2MyYzYzNTc5Il0geyBib3JkZXItcmFkaXVzOiAzMHB4O2JhY2tncm91bmQ6IHJnYmEoIDI0NCwgMjUwLCAyNDMsIDEgKTtwYWRkaW5nOiA4MHB4OyB9IC53cC1ibG9jay10b29sc2V0LWJsb2Nrcy1jb250YWluZXIudGItY29udGFpbmVyW2RhdGEtdG9vbHNldC1ibG9ja3MtY29udGFpbmVyPSJmNmUzMDA2YzJiNGRmZTczYzRmMjFjNGNjMmM2MzU3OSJdID4gLnRiLWNvbnRhaW5lci1pbm5lciB7IG1heC13aWR0aDogMTM0MHB4OyB9IEBtZWRpYSBvbmx5IHNjcmVlbiBhbmQgKG1heC13aWR0aDogNzgxcHgpIHsgLnRiLWNvbnRhaW5lciAudGItY29udGFpbmVyLWlubmVye3dpZHRoOjEwMCU7bWFyZ2luOjAgYXV0b30gLndwLWJsb2NrLXRvb2xzZXQtYmxvY2tzLWNvbnRhaW5lci50Yi1jb250YWluZXJbZGF0YS10b29sc2V0LWJsb2Nrcy1jb250YWluZXI9ImY2ZTMwMDZjMmI0ZGZlNzNjNGYyMWM0Y2MyYzYzNTc5Il0geyBwYWRkaW5nOiA0MHB4OyB9ICB9IEBtZWRpYSBvbmx5IHNjcmVlbiBhbmQgKG1heC13aWR0aDogNTk5cHgpIHsgLnRiLWNvbnRhaW5lciAudGItY29udGFpbmVyLWlubmVye3dpZHRoOjEwMCU7bWFyZ2luOjAgYXV0b30gLndwLWJsb2NrLXRvb2xzZXQtYmxvY2tzLWNvbnRhaW5lci50Yi1jb250YWluZXJbZGF0YS10b29sc2V0LWJsb2Nrcy1jb250YWluZXI9ImY2ZTMwMDZjMmI0ZGZlNzNjNGYyMWM0Y2MyYzYzNTc5Il0geyBwYWRkaW5nOiAyMHB4OyB9ICB9IA==
Dernière mise à jour : 8 octobre 2025 — Cet article a été actualisé avec les meilleures pratiques en scalabilité et évolutivité des architectures data.
L’évolutivité est la capacité d’une architecture data à absorber la croissance des volumes, des flux et de la complexité, sans sacrifice de performance. Dans un contexte où les données explosent, disposer d’un système scalable est devenu un impératif pour les entreprises modernes.
Pourquoi l’évolutivité est cruciale en architecture Data
Le volume de données dans le monde devrait atteindre 181 zettabytes d’ici 2025 selon les projections de Statista. D’ailleurs 9 entreprises sur 10 affirment que les données sont essentielles à leur succès (Source Forrester). Pourtant, la plupart des entreprises, 73 % selon Gartner, reconnaissent que leurs architectures de données actuelles ne sont pas adaptées pour répondre aux exigences futures, mettant en lumière la nécessité de systèmes data plus évolutifs.
L’explosion des volumes de données, la diversité des sources (IoT, SaaS, IA) et l’accélération des usages temps réel imposent aux entreprises de revoir leur architecture.
Une architecture data scalable n’est plus un luxe, mais un prérequis pour assurer la performance, la résilience et la soutenabilité opérationnelle du SI data.
Nous vous proposons d’aborder les principes fondamentaux qui sous-tendent une architecture de données évolutive (et durable), des stratégies de partitionnement et de sharding à l’adoption de modèles de données flexibles et de solutions de stockage distribuées. Suivez le guide !
Principes fondamentaux d’une architecture data évolutive
Une architecture data évolutive repose sur 4 piliers techniques :
- la scalabilité élastique (horizontale et verticale),
- l’interopérabilité entre composants,
- la résilience face aux montées en charge,
- et une modularité permettant des évolutions sans refonte globale.
L’objectif est de construire un système capable de s’adapter aux usages, aux volumes et aux contextes, tout en maintenant des performances stables.
1. Services cloud et autoscaling
Cette explosion du volume de données pose un défi majeur aux entreprises, qui doivent trouver des moyens de stocker, traiter et analyser ces données de manière efficace et évolutive. Les infrastructures traditionnelles, basées sur des serveurs physiques, ne sont souvent pas adaptées. Ces infrastructures peuvent rapidement atteindre leurs limites en termes de capacité de stockage, de puissance de calcul et de bande passante. Elles sont d’ailleurs souvent difficiles à maintenir et à faire évoluer, ne serait que par le manque de ressources (compétences comme financières).
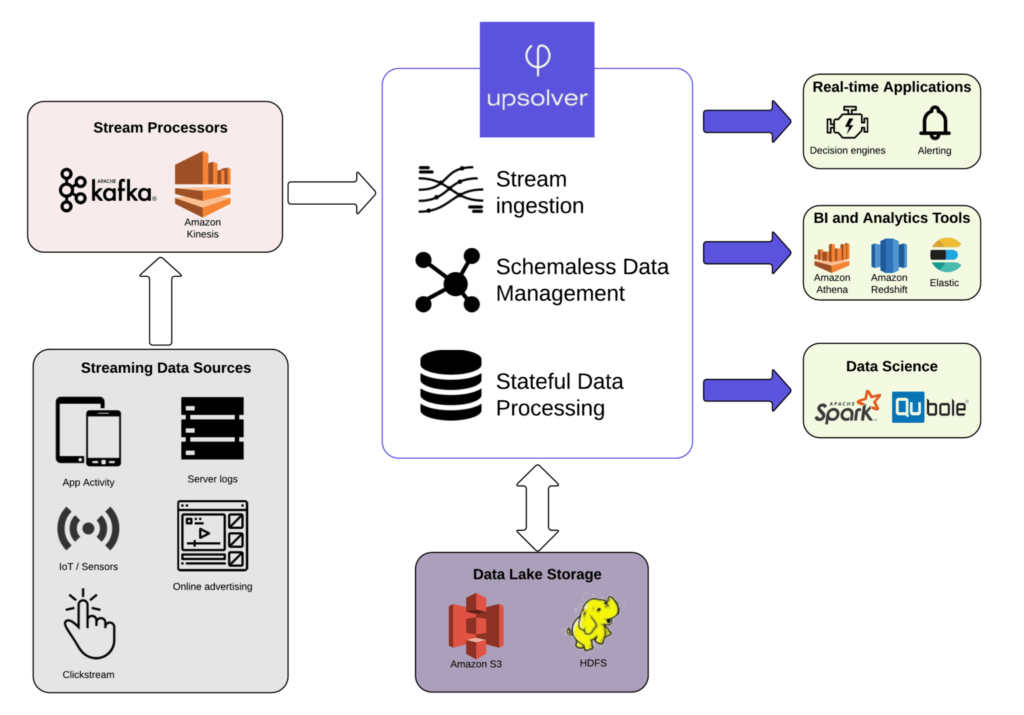
L’utilisation des services cloud s’impose comme une solution car l’un des principaux avantages est justement leur capacité de mise à l’échelle automatique, l’élasticité. Les ressources informatiques peuvent être augmentées ou diminuées en fonction des besoins, sans intervention manuelle. Une architecture data scalable permet de gérer notamment des pics de demande sans interruption de service et de payer uniquement pour les ressources utilisées réellement.
Les infrastructures cloud (AWS, Azure, GCP) offrent des mécanismes natifs d’autoscaling et de répartition dynamique des charges.
En s’appuyant sur du stockage distribué (S3, Blob), des bases managées (BigQuery, Cosmos DB) ou du compute élastique (Databricks, EMR), les entreprises peuvent absorber des pics de charge sans redéployer.
Le bon choix entre cloud public, privé, hybride ou multi-cloud dépend de vos contraintes de conformité, performance et coûts. L’approche FinOps devient ici essentielle.
- Stockage de données : Les services cloud comme Amazon S3 ou Azure Blob Storage permettent de stocker de grandes quantités de données de manière évolutive et sécurisée
- Bases de données : Les bases de données cloud comme Amazon DynamoDB ou Azure Cosmos DB offrent une évolutivité horizontale, elles peuvent donc être étendues en ajoutant de nouveaux serveurs.
- Traitement de données : Les services cloud comme Amazon EMR ou Azure Databricks permettent de traiter des volumes de données massifs en parallèle
Selon nos experts chez Smartpoint, vous devez prendre en considération plusieurs facteurs pour avoir une architecture data scalable optimale.
Avez-vous besoin de scalabilité horizontale ou verticale ?
- Scalabilité horizontale (scale-out) : Lorsque vous êtes amené à gérer rapidement des pics de demandes, cela permet d’augmenter la capacité en ajoutant des instances supplémentaires. Particulièrement évolutive, elle est en revanche généralement plus coûteuse.
- Scalabilité verticale (scale-up) : Lorsque vos charges de travail sont prédictibles, cela vous permet d’augmenter la puissance d’une seule instance de calcul (CPU, mémoire) pour booster les performances sans ajouter d’instances supplémentaires. C’est une approche qui peut être moins coûteuse à court terme et moins complexe à gérer, mais elle est limitée par les capacités maximales du matériel utilisé.
- Modèle hybride : Cette méthode associe la scalabilité horizontale et verticale, offrant ainsi une flexibilité et une adaptabilité optimales. Vous pouvez par exemple ajouter des serveurs supplémentaires pour gérer l’augmentation des charges de travail (scale-out) tout en boostant la capacité de traitement des serveurs existants (scale-up) pour des performances accrues. Cette stratégie peut offrir le meilleur des deux mondes, permettant de répondre efficacement aux fluctuations imprévisibles de la demande tout en optimisant l’utilisation des ressources pour les charges de travail stables et prévisibles.
Quel modèle de cloud est le plus adapté à votre entreprise ?
- Cloud privé : Contrôle total, sécurité renforcée … mais moins flexible et plus coûteux.
- Cloud public : Flexibilité, évolutivité et moins cher … mais moins de contrôle et de sécurité.
- Cloud hybride : Combinez les avantages du public et du privé pour un équilibre entre flexibilité et sécurité.
- Multi-cloud : Utilisez plusieurs fournisseurs de cloud pour la redondance mais …. aussi éviter la dépendance.
Smartpoint préconise l’adoption d’une approche FinOps pour le choix et la gestion de votre cloud, afin d’assurer une évolutivité optimale et une maîtrise des coûts. Cela vous permet de :
- Comprendre et maîtriser vos dépenses cloud en suivant une approche proactive de gestion des coûts.
- Identifier et éliminer les gaspillages en analysant vos modèles d’utilisation et en optimisant vos configurations.
- Choisir le bon cloud et les bons services en fonction de vos besoins spécifiques et de votre budget.
- Négocier des tarifs avantageux avec les fournisseurs de cloud.
- Mettre en place des processus d’approbation et de gouvernance pour garantir une utilisation responsable du cloud.
2. Bases de données distribuées et répartition de charge
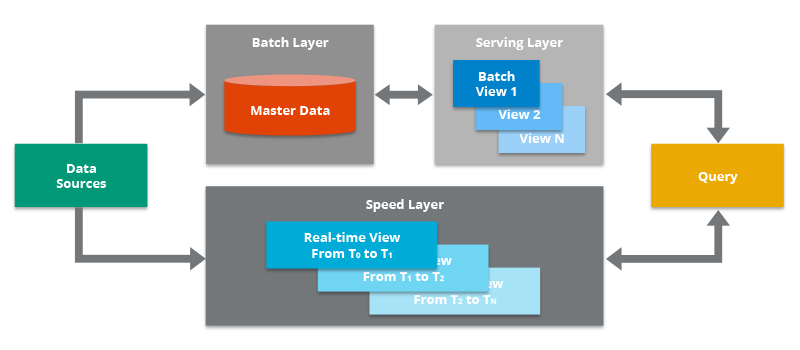
Les bases de données distribuées sont conçues pour stocker et gérer de grandes quantités de données sur plusieurs serveurs physiques ou virtuels. Elles peuvent être mises à l’échelle horizontalement en ajoutant de nouveaux serveurs au cluster, ce qui permet d’améliorer les performances et la disponibilité. Cette architecture data scalable permet de répartir les données et le traitement sur plusieurs machines ; et cela a de nombreux avantages.
L’échelonnabilité horizontale de cette architecture permet d’ajouter des serveurs au cluster afin d’augmenter la capacité de stockage et la puissance de calcul, sans avoir à remplacer le matériel existant. Cela vous permet d’ajouter des ressources au fur et à mesure de vos besoins sans interruption de service. Vous pouvez gérer des pics de demandes sans ralentissement ni risques de pannes système.
Quant à la haute disponibilité, elle est au cœur de la conception des systèmes distribués. Cela signifie qu’elles peuvent continuer à fonctionner même si un ou plusieurs serveurs du cluster tombent en panne, les autres membres du cluster prennent le relais pour assurer la continuité du service. Les données sont répliquées sur plusieurs serveurs, ce qui garantit qu’elles sont toujours accessibles, même en cas de panne. C’est un avantage majeur pour les entreprises qui ont besoin d’un accès continu à leurs données 24/7. Cela minime les risques de perte de données critiques.
Les bases de données distribuées offrent également plus de performances. Cela est dû au fait que les données et le traitement sont répartis sur plusieurs serveurs. Cela permet de paralléliser les requêtes, elles sont donc traitées plus rapidement. Elles permettent de gérer de gros volumes de données complexes, même en temps réel. L’expérience utilisateur est améliorée car les temps de réponse et les latentes sont réduits.
Enfin, les bases de données distribuées sont très flexibles. Elles peuvent être déployées sur site, dans le cloud ou les deux. Cela vous permet de choisir la solution qui répond le mieux à vos besoins. De plus, elles peuvent être personnalisées pour répondre aux besoins spécifiques.
- Apache Cassandra : Une base de données NoSQL flexible et évolutive, idéale pour les applications Big Data.
- MongoDB : Une base de données NoSQL document-oriented, adaptée aux applications web et aux données semi-structurées.
- Apache HBase : Une base de données NoSQL basée sur des colonnes, conçue pour les applications de traitement de données volumineuses.
En bref, les bases distribuées (MongoDB, Cassandra, Apache HBase, Snowflake, BigQuery) permettent :
- un partitionnement automatique des datasets,
- une réplication géographique des données,
- et une parallélisation massive des requêtes.
Ces architectures sont idéales pour traiter des volumes en croissance tout en assurant disponibilité et tolérance aux pannes.
Les différents types de bases de données distribuées
Il existe différents types de bases de données distribuées, tels que les bases de données relationnelles distribuées (RDBMS distribués), les bases de données NoSQL et les bases de données en mémoire. Chaque type de base de données distribuée offre des avantages et des inconvénients différents, et il est important de choisir le type de base de données le plus adapté à vos besoins.
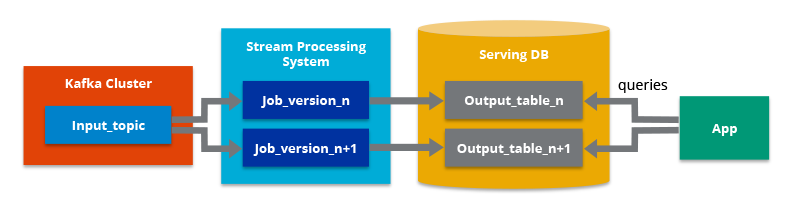
3. Microservices et découplage d’architecture
En architecture de données, l’adoption d’une approche basée sur les microservices est une avancée majeure vers l’évolutivité et l’élasticité. Cette stratégie décompose les applications en services granulaires et autonomes, souvent centrés sur des fonctionnalités métier spécifiques, permettant une évolution et une mise à l’échelle plus souples et indépendantes.
Les microservices renforcent l’évolutivité en autorisant l’augmentation ou la réduction de la capacité de chaque composant de l’architecture de manière individuelle, en fonction de la demande. Un service particulièrement sollicité peut ainsi être modifié sans impacter les autres parties du système.
Prenons l’exemple d’une application de e-commerce confrontée à une augmentation du trafic client. Le service de gestion du panier d’achat peut évoluer séparément pour gérer la charge supplémentaire, sans affecter les autres services afférents.
En matière d’élasticité, les microservices permettent des mises à jour et des améliorations continues sans nécessiter le redéploiement de l’ensemble de l’application. Cette approche permet plus de réactivité aux évolutions marché ou aux exigences utilisateurs.
Un service de recommandation de produits peut, par exemple, être mis à jour avec de nouveaux algorithmes d’intelligence artificielle pour fournir des suggestions plus précises aux clients, sans perturber les services de facturation ou de logistique.
L’architecture microservices favorise également l’adoption de technologies et de pratiques innovantes telles que les conteneurs et l’orchestration avec des outils comme Kubernetes. Ces outils permettent de gérer le déploiement, la mise à l’échelle et la gestion des applications conteneurisées. Par conséquent, les microservices favorisent non seulement l’évolutivité et la flexibilité des opérations de données mais aussi encouragent une culture d’innovation continue et d’amélioration des performances.
Les architectures microservices permettent une évolution indépendante de chaque composant (ex. ingestion, transformation, restitution).
Chaque service peut être scalé individuellement sans impacter l’ensemble. Couplés aux conteneurs (Docker) et orchestrateurs (Kubernetes), les microservices permettent une mise à l’échelle continue, une résilience renforcée et une plus grande agilité de delivery. Les micro-services ont aujourd’hui fait leurs preuves pour construire des architectures de données évolutives et flexibles, capables de s’adapter rapidement et efficacement aux besoins changeants des entreprises et de leurs clients. Cette approche recommandée par Smartpoint permet de répondre aux exigences croissantes en matière de traitement et d’analyse de données, tout en garantissant la résilience et la disponibilité des systèmes.
4. Quels autres facteurs prendre en compte pour améliorer la scalabilité des architectures data ?
Les données structurées offrent plus de flexibilité. Pour garantir l’évolutivité de votre architecture data, penser la structuration de vos données est primordial. Vous devez organiser les données de manière à faciliter leur accès, leur analyse et leur gestion. Une architecture de données bien conçue permet un partitionnement adaptif des données et l’utilisation de stratégies de sharding efficaces. Exploiter ces techniques pour diviser de grands ensembles de données en segments plus petits permet d’améliorer la gestion, les performances et la scalabilité. La réplication et la redondance des données assurent plus de tolérance aux pannes, et préservenr l’intégrité des données en cas de défaillance matérielle.
L’automatisation et l’orchestration sont également des incontournables dans les infrastructures data modernes. Tirer parti des fonctionnalités d’auto-scaling de l’infrastructure cloud permet d’ajuster automatiquement les ressources en fonction de la charge de travail, garantissant ainsi des performances optimales et permet également de réduire les dépenses.
Par ailleurs, un suivi en temps réel est indispensable pour une gestion proactive de la performance des applications et services. Des outils de surveillance tels que ceux proposés par les fournisseurs de cloud ou des solutions tierces sont cruciaux pour prendre des décisions basées sur les données et garantir l’efficacité de votre infrastructure.
Les avancées proposées par les outils d’analyse prédictive et de machine learning sont devenus également indispensables pour anticiper les tendances et besoins à venir. Ces technologies permettent une adaptation proactive de l’architecture des données.
Enfin, une architecture évolutive réouvre le débat entre les bases de données relationnelles et NoSQL. Nous vous conseillons les bases de données NoSQL pour leur flexibilité dans la gestion de données non structurées ou semi-structurées et leur capacité à évoluer horizontalement. Les bases de données NewSQL sont un compromis intéressant entre les avantages de scalabilité de NoSQL et les propriétés ACID des bases de données relationnelles.
La scalabilité ne repose donc pas que sur l’infrastructure, c’est aussi des choix de conception :
- Structuration des données : modèles flexibles (NoSQL, JSON, colonnes)
- Partitionnement logique : diviser les datasets selon critères métier ou temporels
- Sharding horizontal : distribution automatique des volumes entre nœuds
- Réduction des points de contention dans les traitements ou requêtes
- Optimisation des modèles de requêtage (pushdown, vectorisation, cache)
Les meilleures pratiques pour une architecture data évolutive
À faire :
- Concevoir pour l’évolutivité dès l’amont (modèles, pipelines, stockage)
- Tester régulièrement la charge et les limites (stress tests)
- Documenter les points de défaillance et les métriques critiques
- Gouverner l’usage cloud pour éviter les dérives (FinOps)
À éviter :
- Empilement d’outils sans orchestration
- Centralisation excessive
- Ignorer la sécurité et la résilience dans les plans de scalabilité
Vers une architecture data durable : roadmap et recommandations
La construction d’une architecture de données véritablement évolutive et durable commence par une évaluation précise de votre maturité actuelle, tant sur le plan architectural que sur la gouvernance ou la volumétrie des données traitées. Ce diagnostic initial permet de cadrer vos besoins métiers à court et moyen terme, tout en projetant leur évolution sur un horizon de deux à trois ans.
À partir de cette analyse, nous identifions une architecture cible modulaire, cloud native et adaptée à votre contexte (métier et IT), en capitalisant sur les standards ouverts, l’interopérabilité et la scalabilité. Les premières étapes du projet se concentrent sur les gains rapides, qu’il s’agisse de migrations ciblées, de refactoring applicatif ou d’une meilleure structuration de la gouvernance data.
Notre approche de déploiement privilégie l’agilité avec des PoC opérationnels, des services découplés et une scalabilité progressive et maîtrisée. Cette dynamique se poursuit dans le temps par un suivi régulier des performances, des KPI de succès et des ajustements continus en fonction des évolutions techniques ou métier.
Pourquoi faire confiance à Smartpoint pour une architecture data scalable ?
En tant qu’ESN spécialisée dans la data BI, Smartpoint met à votre service une expertise éprouvée en architecture data, cloud, BI moderne et ingénierie de la scalabilité. Dès les premières phases de cadrage, nos consultants conçoivent des architectures pensées pour durer, capables d’accompagner votre croissance sans rupture.
Nous mobilisons nos expertises sur les écosystèmes cloud et big data (Azure, Snowflake, GCP, Databricks…) pour sélectionner les briques technologiques les plus pertinentes. Notre accompagnement va au-delà de la mise en œuvre technique, en intégrant des logiques de FinOps pour optimiser vos coûts cloud et une gouvernance de la donnée solide et industrialisée. Grâce à nos équipes agiles basées en France mais aussi dans notre CDS de Tunis, nous proposons un modèle de delivery souple, réactif et maîtrisé, alliant proximité, expertise et performance opérationnelle.
Vous vous demandez si votre architecture de données est prête pour l’avenir ? Contactez l’équipe de Smartpoint dès aujourd’hui pour une évaluation gratuite et découvrez comment nous pouvons vous aider à optimiser votre infrastructure pour plus d’évolutivité et d’élasticité.
Pour aller plus loin :
Évolutivité des architectures data ?
Pourquoi l’évolutivité est-elle un enjeu prioritaire pour les DSI ? Les volumes de données doublent tous les 18 mois. Une architecture scalable évite la dette technique et garantit la continuité métier.
Quels outils choisir pour scaler une architecture ? Snowflake, BigQuery, Databricks, Kubernetes, Kafka, MongoDB… selon vos cas d’usage.
Comment mesurer la scalabilité d’un système data ? Temps de réponse, latence, débit des requêtes, montée en charge simulée, disponibilité sous contrainte.
Quelle différence entre évolutivité et élasticité ? L’évolutivité permet de croître sans perte de performance. L’élasticité permet d’ajuster dynamiquement les ressources à la demande.