Réduire l’impact environnemental … passe aussi par une meilleure gestion de vos données.
0 commentaires
Quelle méthode adopter pour une approche frugale de vos projets data ? Certes, il est nécessaire d’avoir un certain volume de données pour établir des estimations ou des prévisions mais au-delà d’un certain seuil, le gain apporté par une donnée supplémentaire décroit.
Accumuler des data n’est pas synonyme de création de valeur, alors que l’on a tendance à collecter et à stocker un maximum de données « au cas où » nous aurions besoin de les exploiter et de les analyser à moment donné…. C’est au contraire une aberration ! Non seulement les données perdent de manière générale de la valeur avec le temps et surtout, leur capture, leur stockage, leur circulation et leur diffusion génère des dépenses énergétiques exponentielles … d’autant plus que la Data est inexorablement copiée vers des destinations diverses et variées sans que la donnée source ne soit jamais supprimée.
Comment ne pas générer plus de données que nécessaire ? Comment réduire la consommation de ressources matérielles et énergétiques ? Voici en 5 points des pistes de développement de techniques de minimisation des coûts énergétiques de vos projets Data.
L’intérêt de la data. Avez-vous vraiment besoin de ces données et pour quels usages ? Il est important de ne pas perdre de vue l’objectif à atteindre et en quoi il justifie la collecte et l’informatisation de la donnée (utilité)
Représentativité de la donnée : en quoi cette donnée participe à un ensemble de phénomènes ? Est-ce que cette data est la plus pertinente pour représenter ce ou ces phénomènes ?
Est-ce que cette nouvelle donnée rend caduque une autre donnée déjà collectée et à quelle fréquence ?
Éviter la redondance liée aux étapes de transformation des données en mutualisant notamment les étapes de préparation via un partage des pipelines (DataOps, MLOps) pour pouvoir les réutiliser et analyser les interactions entre les projets.
Meilleur échantillonnage et sondage des données pour déterminer quel volume est réellement nécessaire pour une analyse ou la modélisation souhaitée. Souvent seule 10% des données suffisent pour obtenir les attendus ou suivre les évolutions d’un phénomène … et c’est autant de ressources informatiques économisées au niveau infrastructure !
Ecosystème Data ? État de l’art en cette rentrée 2021
0 commentaires
Smartpoint partage avec vous les principaux composants des plateformes data d’aujourd’hui selon lakeFS.
Ingestion des Data soit par lots avec Spark ou Pandas, soit par streaming avec Kafka, soit issues de systèmes opérationnels via managed SaaS ou d’autres BDD internes en utilisant des outils comme Stitch
Datalake avec principalement deux types d’architectures par stockage d’objets dans le cloud (GCP, Azure, AWS) et moteur d’analyse avec une interface SQL (Snowflake, Redshift, Databricks lakehouse, …)
Gestion des métadonnées avec des formats ouverts de tables et des métastores comme celui de Hive
Gestion du cycle de vie des données par CI/CD et des environnement dédié de développement de données
Orchestration des tâches pour les pipelines de données qui s’exécutent sur le datalake avec Airflow ou Dagster
Traitement des données avec des moteurs de calculs distribués comme Spark
Virtualisation avec des outils tels que Trino (ex PrestoSQL) ou Denodo
Analytics et Data Science en utilisant un modèle MLOps (Meta Flow développé par Netflix ou Kuberslow par Google), des workflows analytiques et des outils de discovery comme datahub (linkedIN), metacat (Netflix) ou dataportal (airbnb)
Développeurs Javascript, votre stack technologique évolue en permanence. Voici les tendances à suivre.
0 commentaires
En termes de frameworks, React reste en haut de la pile avec Angluar mais aussi VueJS et Svelte.
Il existe pléthore d’outils de gestion de projet dont les incontournables Jira, Trello, Asana et Confluence mais aussi Notion, Clubhouse ou encore Monday pour gérer le processus de développement CI/CD. Citons également Slack ou Discord pour la communication entre les équipes.
En Back-end, les plus populaires restent NodeJS, PostgreSQL en BDD SQL, MongoDB en noSQL, HaperDB pour les BDD hybrides NoSQL/SQL.
En Front-end, NextJS est parfait pour un site web statique ou Create React App pour un site Web React standard avec Redux. Tailwind vous permet d’éviter de partir de zéro pour écrire vos propres CSS pour un processus de développement encore plus rapide. Par ailleurs, Sass et Styled-components peuvent être utilisés comme alternative à Tailwind avec des capacités avancées pour la personnalisation de composants dans React.
Citons également Storybook pour la création modulaire de composants dans une bibliothèque dynamique qui peut être mise à jour et partagée au sein de l’entreprise.
Pour les tests : Jest et Enzyme, React Testing Library et Cypress. Et enfin, Vercel, Netlify et AWS pour un CI/CD avec GitHub. Et pour terminer les applications mobile avec ReactNative et Redux, FlutterApp et Dart.
En vrac, on retrouve : 👉 les Data Insights qui finalement viennent remplacer la BI « historique » dans le sens où on cherche (toujours) à faire parler des données brutes (lesdatas) 👉 Le Data Catalog qui se rapproche du fameux dictionnaire de données 👉 Le Pipeline analytique qu’on pourrait rapprocher du Data Management avec l’ETL, le DQM puis la restitution dans des dashboards
On y aborde aussi les concepts de Data Literacy, d’analytique augmentée ou de Modern BI (terme de Gartner), d’analytique embarquée ou l’Active Intelligence.
Le monde de la Data n’en fini pas de se réinventer.
Data Lab
L’IA part à la découverte de nouvelles molécules dans l’industrie pharmaceutique.
0 commentaires
La découverte de nouvelles molécules, qui sont dotées de spécifications biochimiques bien particulières, représente toujours un processus très laborieux et coûteux dans la R&D pharmaceutique. En effet, cette découverte est traditionnellement menée par un tâtonnement au cas par cas sur un nombre astronomique de molécules candidates dont l’objectif est de trouver, ou mieux identifier, une molécule qui maximise un grand nombre de critères de natures très diverses. Même en s’appuyant sur des logiciels de simulation complexes, la démarche demeure incertaine, étant donné que, d’une part, la stabilité physico-chimique des molécules prédites numériquement n’est pas toujours assurée, et que, d’autre part, les structures moléculaires générées sont souvent difficiles à développer et à mettre en œuvre. Dans ce contexte, l’Intelligence Artificielle (IA) permet d’optimiser ce problème multiparamétrique dont les contraintes sont abordées simultanément et, par la suite, de mettre au point des modèles holistiques à forte valeur ajoutée qui ont le potentiel de générer des nouvelles molécules pratiques et rentables.
Notre projet intitulé « L’IA pour la génération contrôlée de nouvelles molécules » s’inscrit dans cette perspective de creuser les apports possibles de l’IA dans la R&D pharmaceutique. Pour y parvenir, nous avons développé un nouveau modèle de réseau neuronal récurrent contrôlé, basé sur une architecture multicouche de cellules « Long Short-Term Memory (LSTM) », pour générer des molécules présentant des propriétés pharmacologiques et physico-chimiques particulières (activité sur une protéine, solubilité, toxicité, etc.) et qui peuvent être, par exemple, utiles pour le traitement du cancer. En l’occurrence, nous avons généré des molécules actives sur les cibles suivantes :
BRAF, gène responsable de la production de la protéine B-Raf sérine/thréonine kinase B-Raf impliquée dans l’envoi des signaux qui déterminent la croissance des cellules,
ITK, gène responsable de la production de la protéine Tyrosine-protéine kinase ITK/TSK soupçonnée de jouer un rôle important dans la prolifération et la différentiation de lymphocytes T,
mTOR, enzyme de la famille des sérine/thréonine kinases qui régule la prolifération cellulaire, la croissance, la mobilité et la survie cellulaire ainsi que la biosynthèse des protéines et la transcription.
Le modèle proposé, que nous appelons « Multiplicative Conditionned LSTM-based RNN », est capable de générer de nouvelles molécules qui n’avaient jamais été observées auparavant et qui présentent une diversité proche de celle des molécules qui ont servi à l’apprentissage du modèle, tout en contrôlant leurs propriétés et les caractères actifs ou non sur chaque cible, malgré le nombre limité de données d’apprentissage disponibles.
Omar GASSARA, R&D Project Manager, Smartpoint
Les algorithmes utilisés dans le cadre de ce projet sont : (1) un réseau de neurones récurrents (en anglais « Recurrent Neural Network RNN ») profond avec une cellule d’architecture « Long Short-Term Memory », (2) « Semantically Conditionned LSTM-based RNN » et (3) « Multiplicative Conditionned LSTM-based RNN », le nouveau modèle que nous proposons.
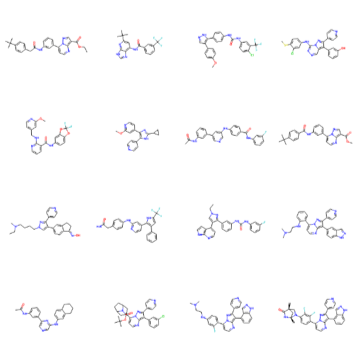
Exemple de nouvelles molécules générées présentant une activité sur le gène BRAF ; Ces représentations graphiques, dites formules topologiques, montrent la structure de chaque molécule et indiquent le nombre et le type d’atomes qui la composent, ses liaisons interatomiques et sa forme dans l’espace.
Phénomène
2022, les tendances de la Data.
0 commentaires
Rituel de nouvelle année oblige, voici 6 grandes tendances Data qui devraient marquer 2022 avec pour toile de fond un cloud toujours plus omniprésent, une informatique quantique qui devrait enfin sortir des cartons, un développement soutenu des tissus de données (Data Fabrics) et de son corolaire maillage de données (Data Mesh).
Prédictions Data / IA 2022
Data Fabric, un environnement qui permet de réconcilier toutes les sources de données et Data Mesh, une approche d’architecture distribuée dynamique qui consiste à spécifier un domaine par sa création, le stockage et le catalogage des données afin qu’il soit exploitable par tous les utilisateurs d’autres domaines.
les Data Platformscloud-natives « as-a-service » qui apportent élasticité, performance et évolutivité. Elles devraient porter 95% des projets de transformation numérique des entreprise à horizon 2025 vs. 40% cette année.
L’hyper-automatisation et l’apprentissage automatique. Diminuer l’intervention humaine, pour la concentrer sur ce qui apporte le plus de valeur ajoutée, permet d’accélérer le time-to-market. Le développement de l’apprentissage automatique (ML) dans tous les processus métiers où il peut être embarqué est déjà une tendance forte qui devrait, sans surprise, s’accentuer sur toutes les tâches qui peuvent l’être. Cela permet aussi de gagner en capacités décisionnelles.
En parlant de BI (Business Intelligence), elle devrait continuer à se développer et à se démocratiser au-delà des seules grandes entreprises (PME). Plus facile d’accès, solutions moins chères aussi, elle se met de plus en plus au service du pilotage par la performance. Il en est de même de l’analyse prédictive (+ 20% sur 5 ans cf source ci-dessous)
l’ingénierie d’Intelligence Artificielle (IA) qui devrait permettre aux 10% des entreprises qui l’auront mise en pratique de générer trois fois de valeur que les 90% qui ne l’auront pas fait (toujours selon Gartner).
Small Data (vs. Big Data) dont l’objectif est de se concentrer sur la collecte et l’analyse de données vraiment utiles (et non de capter par principe massivement toute les données) … Vers une approche plus rationnelle, réfléchie, plus responsable et économe auquel nous sommes très attachés chez Smartpoint.
Quelles solutions à suivre en cette année 2022 ? Informatica, Microsoft toujours (notamment sur l’automatisation avec Power Automate), Qlik et Denodo pour n’en citer que 4 !
En clair, les années passent … mais l’enjeu reste le même. En revanche, il a gagné en criticité au fur et à mesure que les entreprises ont réalisé que les données sont une ressource stratégique, quel que soit leur secteur d’activité. Leur capture, leur gestion, leur gouvernance, leur exploitation et leur valorisation restent le défi N°1.
D’ailleurs, parmi les 12 tendances de Gartner pour 2022, 5 concernent la Data !
Top 10 des outils incontournables à l’usage des ingénieurs Data
0 commentaires
Voici une sélection de 10 outils incontournables à l’usage des ingénieurs Data !
Pour concevoir et mettre en place une infrastructure robuste et efficace, un consultant data doit maîtriser différents langages de programmation, des outils de Data Management, des data warehouses, des outils de traitement des données, d’analyse mais aussi d’ IA et de ML.
Python, la norme en terme de langage de programmation pour coder notamment des frameworks ETL, les interactions entre des API, automatiser certaines tâches, etc.
SQL pour toutes les requêtes mêmes les plus complexes
PostgreSQL, la base de données open source la plus populaire
MongoDB, la base de données NoSQL pour sa capacité à traiter également les données non structurées sur de très larges volumes
Spark pour sa capacité à capter et à traiter des flux de données en temps réel à grand échelle. De plus, il prend en charge de nombreux langages tels que Java, Scala, R et Python
Kafka, la plateforme de streaming de données open source
Redshift (Amazon), le datawarehouse dans le cloud conçu pour stocker et analyser des données sur de fortes volumétries
Snowflake, la cloud Data Platform devenue incontournable aujourd’hui
Amazon Athena, l’outil serverless de query interactif qui vous aide à analyser des données non structurées, semi-structurées et structurées stockées dans Amazon S3 (Amazon Simple Storage Service)
Airflow (Apache) pour orchestrer et planifier les pipelines de données
Innovations dans les moteurs de recommandation pour le retail & la grande distribution.
0 commentaires
Le croisement et l’analyse d’innombrables données, de type Big Data, a toujours été une problématique majeure dans la grande distribution. Depuis des années, les distributeurs collectent, enregistrent et analysent d’énormes quantités d’informations, depuis les sorties de caisses jusqu’aux stocks, en passant par les prix. De nos jours, la valorisation de ce type de données est devenue nécessaire pour les enseignes de distribution qui cherchent à fidéliser les consommateurs les moins réguliers en leurs proposant des produits répondant au mieux à leurs besoins. En effet, connaître les préférences du client, devancer ses attentes et lui proposer l’offre la plus personnalisée, pourraient l’empêcher de se tourner vers des concurrents, qui, eux, en sont capables.
Pourtant les modèles standards de filtrage collaboratif, qui sont utilisés traditionnellement dans les moteurs de recommandation, manquent souvent de précision. Ils nécessitent des calculs excessivement lourds et s’avèrent désormais incapables de tirer parti de la grande quantité de données disponibles (et exponentielle). Ainsi, les enseignes ont eu recours depuis quelques années déjà aux technologies d’intelligence artificielle dans le but de déployer de nouveaux systèmes plus intelligents dont l’architecture est davantage capable de prendre en charge et de traiter les big data. Les projets dans ce domaine se multiplient et se développent rapidement, même s’il convient de mentionner que la majorité d’entre eux sont encore au stade de pilote et font toujours objet de recherche scientifique.
L’objectif de nos travaux était de développer un nouvel algorithme de moteur de recommandation plus précis et plus rapide, basé sur le machine learning et le deep learning, afin d’optimiser l’édition des coupons dans la grande distribution pour une grande enseigne. En effet, les acteurs de la grande distribution investissent massivement dans de larges campagnes marketing mais ils n’ont jusqu’ici que quelques retours sur l’impact effectif de leurs campagnes. Pour y parvenir, nous avons expérimenté de nouveaux outils basés sur la data des consommateurs. L’idée était de faire en sorte que les coupons édités par la grande distribution soient personnalisés afin de s’adapter au mieux aux habitudes de consommation du destinataire final. Ces coupons visent à récompenser le consommateur pour sa fidélité à un ou plusieurs produits, ou encore à lui suggérer des produits susceptibles de l’intéresser en fonction de son historique d’achat… D’où l’objectif du système visé qui consiste à prédire si un consommateur ayant reçu une offre promotionnelle (un coupon) sur un produit, deviendrait un consommateur récurrent de ce dernier ou pas.
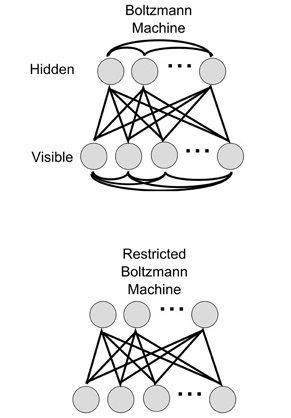
Après une analyse détaillée de l’état de l’art, nous avons construit, optimisé et évalué un modèle adapté à notre problématique en s’inspirant des travaux de recherche de R. Salakhutdinov et al. publiés en 2007 dans leur article « Restricted Boltzmann Machines for Collaborative Filtering ». L’adaptation de ce modèle à notre besoin n’était pas triviale étant donné que ce dernier nécessite une notation explicite des produits par les consommateurs, ce qui n’était pas le cas dans les données dont nous disposions. Pour résoudre ce problème, nous avons remplacé cette note des produits par un indice de consommation calculé par une procédure inspirée de la méthode de pondération « Term Frequency-Inverse Document Frequency (TF-IDF) ».
Par ailleurs, l’apprentissage de notre modèle a été effectué, d’une part, sur les données brutes de transactions effectuées par le consommateur et, d’autre part, sur l’historique de comportement de certains consommateurs suite à la réception des offres promotionnelles, c’est-à-dire, l’indication selon laquelle le consommateur est revenu consommer le produit en question ou pas.
Nous avons finalement proposé une nouvelle approche de filtrage collaboratif adaptée à la problématique de la grande distribution en utilisant les Machines de Boltzmann Restreintes. Nous avons entrainé le modèle proposé sur des données de transactions variées et représentatives du comportement des différents consommateurs d’une grande enseigne. Les résultats obtenus à la phase d’évaluation sur des données de test ont très encourageants et prometteurs, en les comparant à ceux des méthodes standards. Ce projet a donné lieu à de nouveaux travaux qui consistent à enrichir davantage ce modèle en le combinant avec d’autres approches par factorisation de matrice ou par recherche de similarité pour améliorer encore les performances. Nous prévoyons maintenant de réaliser un projet pilote pour cerner la valeur ajoutée de notre système.
Omar GASSARA, R&D Project Manager – Data Science, Smartpoint
Différence entre une machine de Boltzmann et une machine de Boltzmann restreinte.