Data Lab

Le croisement et l’analyse d’innombrables données, de type Big Data, a toujours été une problématique majeure dans la grande distribution. Depuis des années, les distributeurs collectent, enregistrent et analysent d’énormes quantités d’informations, depuis les sorties de caisses jusqu’aux stocks, en passant par les prix. De nos jours, la valorisation de ce type de données est devenue nécessaire pour les enseignes de distribution qui cherchent à fidéliser les consommateurs les moins réguliers en leurs proposant des produits répondant au mieux à leurs besoins. En effet, connaître les préférences du client, devancer ses attentes et lui proposer l’offre la plus personnalisée, pourraient l’empêcher de se tourner vers des concurrents, qui, eux, en sont capables.
Pourtant les modèles standards de filtrage collaboratif, qui sont utilisés traditionnellement dans les moteurs de recommandation, manquent souvent de précision. Ils nécessitent des calculs excessivement lourds et s’avèrent désormais incapables de tirer parti de la grande quantité de données disponibles (et exponentielle). Ainsi, les enseignes ont eu recours depuis quelques années déjà aux technologies d’intelligence artificielle dans le but de déployer de nouveaux systèmes plus intelligents dont l’architecture est davantage capable de prendre en charge et de traiter les big data. Les projets dans ce domaine se multiplient et se développent rapidement, même s’il convient de mentionner que la majorité d’entre eux sont encore au stade de pilote et font toujours objet de recherche scientifique.
L’objectif de nos travaux était de développer un nouvel algorithme de moteur de recommandation plus précis et plus rapide, basé sur le machine learning et le deep learning, afin d’optimiser l’édition des coupons dans la grande distribution pour une grande enseigne. En effet, les acteurs de la grande distribution investissent massivement dans de larges campagnes marketing mais ils n’ont jusqu’ici que quelques retours sur l’impact effectif de leurs campagnes. Pour y parvenir, nous avons expérimenté de nouveaux outils basés sur la data des consommateurs. L’idée était de faire en sorte que les coupons édités par la grande distribution soient personnalisés afin de s’adapter au mieux aux habitudes de consommation du destinataire final. Ces coupons visent à récompenser le consommateur pour sa fidélité à un ou plusieurs produits, ou encore à lui suggérer des produits susceptibles de l’intéresser en fonction de son historique d’achat… D’où l’objectif du système visé qui consiste à prédire si un consommateur ayant reçu une offre promotionnelle (un coupon) sur un produit, deviendrait un consommateur récurrent de ce dernier ou pas.
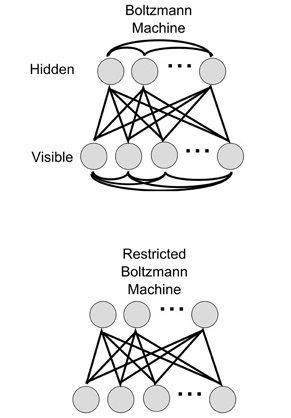
Après une analyse détaillée de l’état de l’art, nous avons construit, optimisé et évalué un modèle adapté à notre problématique en s’inspirant des travaux de recherche de R. Salakhutdinov et al. publiés en 2007 dans leur article « Restricted Boltzmann Machines for Collaborative Filtering ». L’adaptation de ce modèle à notre besoin n’était pas triviale étant donné que ce dernier nécessite une notation explicite des produits par les consommateurs, ce qui n’était pas le cas dans les données dont nous disposions. Pour résoudre ce problème, nous avons remplacé cette note des produits par un indice de consommation calculé par une procédure inspirée de la méthode de pondération « Term Frequency-Inverse Document Frequency (TF-IDF) ».
Par ailleurs, l’apprentissage de notre modèle a été effectué, d’une part, sur les données brutes de transactions effectuées par le consommateur et, d’autre part, sur l’historique de comportement de certains consommateurs suite à la réception des offres promotionnelles, c’est-à-dire, l’indication selon laquelle le consommateur est revenu consommer le produit en question ou pas.
Nous avons finalement proposé une nouvelle approche de filtrage collaboratif adaptée à la problématique de la grande distribution en utilisant les Machines de Boltzmann Restreintes. Nous avons entrainé le modèle proposé sur des données de transactions variées et représentatives du comportement des différents consommateurs d’une grande enseigne. Les résultats obtenus à la phase d’évaluation sur des données de test ont très encourageants et prometteurs, en les comparant à ceux des méthodes standards. Ce projet a donné lieu à de nouveaux travaux qui consistent à enrichir davantage ce modèle en le combinant avec d’autres approches par factorisation de matrice ou par recherche de similarité pour améliorer encore les performances. Nous prévoyons maintenant de réaliser un projet pilote pour cerner la valeur ajoutée de notre système.
Omar GASSARA, R&D Project Manager – Data Science, Smartpoint