modernisation BI
Paris, le 4 mars 2026
Auteurs : Luc Doladille et Emmanuelle Parnois
Auteurs : Luc Doladille et Emmanuelle Parnois
Le décisionnel « dans le rétroviseur » a fait son temps. Dans la plupart des organisations, la BI reste pourtant encore structurée autour d’extractions nocturnes, de chaînes ETL historiques et de dashboards générés à J+1 … alors que visualiser l’activité à postériori n’est plus suffisant. L’enjeu aujourd’hui est de rapprocher donnée, décision et action. Et c’est justement cela que le streaming apporte au SI décisionnel. On ne peut pas remettre au lendemain une fraude, une rupture de stock, une chute de marge ou problème logistique, le signal doit être envoyé dans les flux métiers au moment où il est exploitable. Tous les éditeurs de data streaming comme ceux de plateformes d’analytics agentiques partagent cette même vérité : l’IA s’alimente d’un contexte vivant, de données fraîches, traçables et gouvernées.
Terminé le batch ?
Pas tout à fait ! Le batch reste incontournables pour les usages réglementaires, les consolidations financières, les traitements historiques lourds ou les analyses peu sensibles à la latence. En revanche, il ne peut plus être seul moteur de pilotage de l’entreprise. Lorsqu’une décision métier dépend d’un événement survenu il y a quelques secondes ou quelques minutes, la fraîcheur de donnée est une variable métier essentielle pas un simple composant d’architecture data. Chez Smartpoint, spécialiste 100% Data IA, nous accompagnons nos clients depuis 20 ans dans l’évolution de leur plateforme data et nous constatons clairement un virage vers une BI streaming-first. Le flux temps réel devient un élément natif de l’architecture BI plutôt qu’un dispositif exotique réservé aux besoins les plus avancés.
Techniquement, cela repose sur la capture de l’événement à la source, via des patterns de type CDC (change data capture), des plateformes d’event streaming comme Kafka et des moteurs de traitement capables de travailler au temps de l’événement plutôt qu’au temps d’arrivée. Kafka sert désormais de plateforme d’event streaming pour alimenter des pipelines temps réel et des usages analytiques critiques. En parallèle, Apache Flink (ainsi que Structured Streaming dans l’écosystème Spark) permettent d’industrialiser un traitement continu. Flink met notamment en avant des garanties de cohérence de type exactly-once et une gestion native du temps d’événement. Le sujet n’est donc plus le simple transport de données mais la continuité du signal entre l’événement, son traitement et la décision métier.
Le schéma d’architecture le plus lisible reste souvent celui d’une architecture Kappa ou plus largement d’une approche stream-first : un même socle événementiel alimente les usages opérationnels et analytiques, au lieu de faire cohabiter des chaînes batch d’un côté et temps réel de l’autre. Le bénéfice ne tient pas seulement à la latence, il est aussi dans une urbanisation data plus simple, plus cohérente et plus durable.
Luc Doladille, Directeur Conseil, Smartpoint
De l’Operational Analytics au Live Steering
Le sujet n’est donc pas de produire un nouveau dashboard plus beau ou plus rapidement. Il s’agit de faire évoluer la BI vers l’Operational Analytics puis vers ce que l’on appelle le Live Steering, c’est à dire une donnée qui ne sert plus uniquement à constater mais à orienter directement l’exécution dans les outils métiers. Une anomalie de stock doit pouvoir déclencher une alerte d’approvisionnement, une dérive de marge doit remonter dans le CRM, un incident logistique doit influencer le TMS (transport management system) ou le WMS (Warehouse management system) et un écart dans un comportement client doit pouvoir ajuster en quasi temps réel une action marketing ou une priorité de traitement.
ThoughtSpot décrit d’ailleurs cette nouvelle génération d’analytics comme une capacité à combler l’écart entre le moment où l’on a besoin d’une réponse et celui où on l’obtient réellement, avec des insights de confiance délivrés en secondes plutôt qu’en jours.
Et cette évolution change le rôle du décisionnel. Certes, le pilotage mensuel ou hebdomadaire reste indispensable pour la trajectoire globale, la planification et l’arbitrage. Mais le pilotage temps réel, lui, gère l’exécution au quotidien. Il agit exactement là où se joue désormais la performance de l’entreprise et sa compétitivité : fraude, pricing dynamique, optimisation supply chain, disponibilité produit, qualité de service ou expérience client. La BI n’est plus une couche de restitution séparée du réel, elle devient un composant de l’action opérationnelle.
Alerting intelligent et Agentic BI, et le signal devient action
Chez Smartpoint, nos experts Data et IA recommandent l’Agentic BI. À ne pas confondre avec le chatbot analytique qui attend une question … l’agent analytics surveille en continu l’environnement de données, il détecte les variations significatives, il propose une décision et peut l’exécuter selon le niveau de gouvernance autorisé. ThoughtSpot de son côté définit l’Agentic Analytics comme une approche où les agents IA ne se contentent plus de faire remonter un insight. Ils surveillent les flux, détectent les anomalies, décident et agissent selon les objectifs métier. Et bien entendu, cette autonomie n’exclut pas la supervision humaine. Au contraire, elle la repositionne aux bons endroits, là où le risque ou l’impact la rendent indispensable.
Chez Smartpoint, nous avons structuré notre démarche autour d’un cycle très simple, inspiré de l’OODA Loop et appliqué à l’analytique temps réel : observer, analyser, décider, agir.
La fin du dashboard statique, on passe à des interfaces éphémères
Autre évolution structurante, le dashboard n’est plus forcément figé selon un formalisme prédéfini. Les nouvelles approche d’Agentic BI Dashboard promettent un monde où l’interface analytique est dynamique, éphémère et générée à la volée selon l’intention de l’utilisateur métier. En clair, au lieu de maintenir une usine de tableaux de bord statiques, on laisse un agent IA comprendre la question, aller chercher les bonnes sources, exécuter les traitements nécessaires, puis composer le rendu visuel adapté. Évidemment, ce n’est pas absolument pas la réalité au sein des DSI mais Qlik a déjà fait des annonces en ce sens avec Qlik Answers comme Tableau Next et ThoughtSpot.
Il faut aussi noter, dans cette tendance de fond, la montée en puissance du Model Context Protocol (MCP). Il ne remplacera ni la gouvernance, ni la modélisation, mais il standardise la connexion entre les applications IA, les sources de données et les outils. Présenté comme un protocole ouvert , le “port USB-C” de l’IA », il facilite l’accès à des systèmes externes sans multiplier les connecteurs spécifiques. Le MCP ne porte pas, à lui seul, la BI du futur. En revanche, c’est un accélérateur concret pour des interfaces analytiques conversationnelles capables d’interroger SQL, API, fichiers ou moteurs de calcul sans empiler des couches de code ad hoc.
En tant que pure player data IA, chez Smartpoint nous pensons qu’il faut prendre du recul face aux promesses de l’agentic analytics. Un agent analytique crédible n’a pas vocation à raisonner « au jugé » sur des calculs sensibles. Nos ingénieurs Data IA se concentrent au contraire sur l’exécution de code, par exemple en Python, pour fiabiliser les traitements et sécuriser les résultats, plutôt que de déléguer le raisonnement numérique au seul modèle. Sur des sujets aussi critiques que la marge, la fraude ou la performance commerciale, cette exigence méthodologique change tout côté DSI.
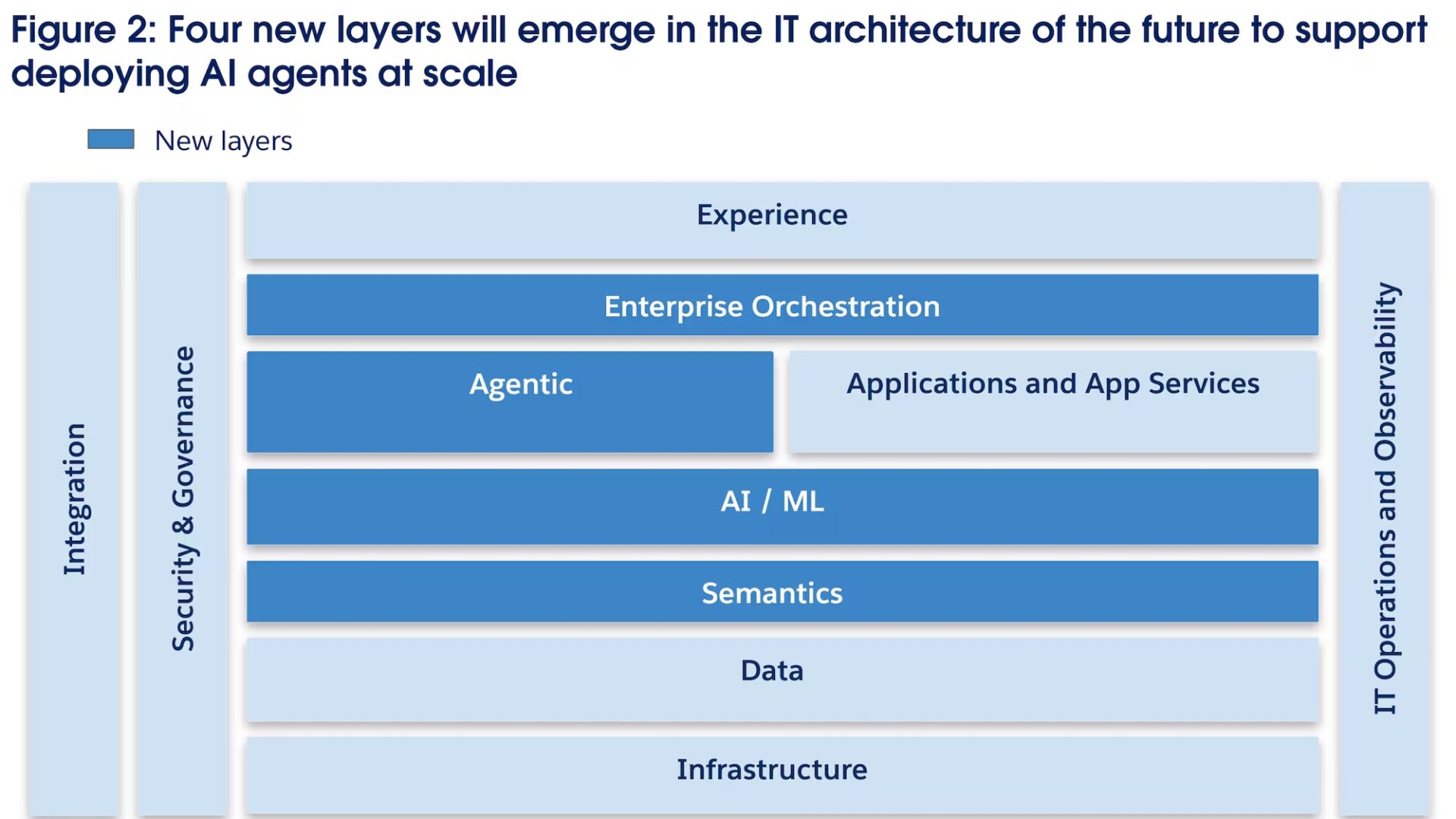
Quel système data pour un décisionnel temps réel ? Architecture et outils
Selon nos architectes Data IA, l’architecture BI temps réel s’organise autour de quatre couches.
1. Ingestion et transport d’événements
La première est celle de l’ingestion et du transport événementiel. Kafka reste la référence pour nos équipes Data IA avec tout son écosystème de connecteurs, de CDC et de patterns event-driven. Les plateformes managées sont de plus en plus fréquentes parce que les équipes veulent consacrer moins d’énergie à l’exploitation de clusters et davantage à la qualité, à la gouvernance et aux data products.
2. Traitement in-flight
La deuxième couche est celle du traitement in-flight. Flink, PyFlink, Spark Structured Streaming et les capacités temps réel de Databricks permettent de filtrer, enrichir, agréger et corréler les événements avant leur exposition analytique. C’est essentiel pour un SI décisionnel moderne qui ne se résume pas à sa vitesse mais aussi en sa capacité à combiner faible latence, tolérance aux pannes, gestion du temps d’événement et garanties de traitement cohérentes.
3. Serving layer analytique faible latence
La troisième couche est celle de la serving layer analytique faible latence. Sur ce terrain, ClickHouse et StarRocks s’imposent dans de nombreux scénarios de requêtes sub-secondes, de dashboards à forte concurrence et de workloads orientés agents. ClickHouse se positionne comme une base analytique open source pour le real-time analytics, tandis que StarRocks met en avant des requêtes multi-tables à latence sub-seconde et une capacité à servir des agents IA à forte concurrence (Voir comparatif dans les sources).
4. Plateformes unifiées cloud et data/AI
La quatrième couche est celle des plateformes unifiées cloud et data/AI. Microsoft Fabric pousse une logique de Real-Time Intelligence couvrant l’ingestion, la transformation, le stockage, l’analytique, la visualisation, l’IA et les actions temps réel. BigQuery est recommandé pour une analytique à grande échelle proche du temps réel. Snowflake, avec Unistore, est pour nos experts Data IA la solution lorsque l’on veut rapprocher le transactionnel et l’analytique dans une même plateforme. Globalement, tous les éditeurs convergent vers des architectures moins fragmentées où le décisionnel ne vit plus à plusieurs jours de distance de l’opérationnel !
De la corrélation à la causalité : pourquoi un agent seul ne suffit pas
Dans les secteurs régulés, il y a une problématique incontournable, celle de la validation.
Un bon agent de pilotage ne doit pas seulement corréler un signal et proposer une action. Il doit aussi pouvoir expliquer, sourcer, justifier et dans certains cas, se faire contredire. C’est là que les architectures multi-agents sont particulièrement adaptées avec un agent d’accès à la donnée et à la sémantique, un agent d’analyse ou de simulation, puis un agent de validation chargé de vérifier les seuils, les droits, les incohérences ou la nécessité d’une approbation humaine. L’enjeu est de rendre le pilotage automatisé certes, mais aussi auditable.
Une trajectoire de modernisation BI en 3 mois ?
En tant qu’expert en Data IA, nous prônons une approche incrémentale qui permet d’amorcer la trajectoire sans refaire le SI Décisionnel.
J1 à J30 : cadrer le data product temps réel
Identifier un cas d’usage où la fraîcheur de donnée a un impact business immédiat : fraude, stock, supply chain, pricing, relation client. Cartographier les sources, définir les KPI et les encoder dans une semantic layer gouvernée.
J31 à J60 : lancer le pilote streaming
Brancher un premier flux live, exposer un data product exploitable, mesurer la latence, la qualité, l’adoption et la capacité d’action dans le système cible. L’objectif n’est pas de faire du temps réel partout, mais de prouver la valeur sur un périmètre précis.
J61 à J90 : industrialiser l’alerting et préparer la sortie du legacy
Mettre en place des alertes intelligentes, les workflows d’escalade, l’observabilité des flux et les premières règles d’automatisation. Puis construire la roadmap de décomissionnement progressif des dashboards et des suites legacy qui génèrent plus de valeur.
En 2026, la BI n’est plus seulement un système de reporting. Elle devient une capacité de pilotage opérationnel, branchée sur le réel, nourrie par des flux continus, gouvernée par une couche sémantique stable et de plus en plus capable d’agir. Les organisations qui sauront passer d’une information stockée à une information vivante auront clairement une longueur d’avance avec moins de latence entre le signal, sa compréhension et la décision. Et, en matière de modernisation BI, c’est là qu’on arrête de piloter dans le rétroviseur !
Plus d’informations ? Besoins d’accompagnement ou de conseils ? Laissez-nous un message, nos experts Data-IA reviennent vers vous dans la journée.
Pour aller plus loin :
- De Power BI à data products, l’architecture BI temps réel de 2026 (Smartpoint)
- Agentic Analytics Explained : AI That Acts on Your Data (ThoughtSpot)
- Data BI Solutions: 2026 Architecture Guide and 90-day Plan (ThoughtSpot)
- John Boyd, The OODA Loop, and Near Real-Time Analytics (TIBCO)
- Modernisation de la BI et du SI Data : réduire la dette de la plateforme décisionnelle pour alimenter l’IA
- 2026, l’année où le data streaming va révolutionner l’IA (InformatiqueNews, Niki Hubaut)
- Agentic BI Dashboard: The End of Static Reporting (Arun Kumar)
- What is Real-Time Analytics? A Complete Guide Click house (2026)
- From Static Models to Agentic Analytics (Ari Joury, PhD)
- Bye, old-school BI, Make better decisions, faster, with agentic analytics. (Tableau)