modernisation BI
Paris, le 25 février 2026 – Auteurs : Luc Doladille, Frédéric Legrand et Emmanuelle Parnois
Temps de lecture : 16 min
La BI s’est longtemps résumée à un choix d’outils : sélection de solutions de dataviz (Power BI, Tableau, Qlik) pour générer des dashboards. Pourtant, l’outil n’est pas le problème de fond, le véritable défi est l’urbanisation du SI décisionnel.
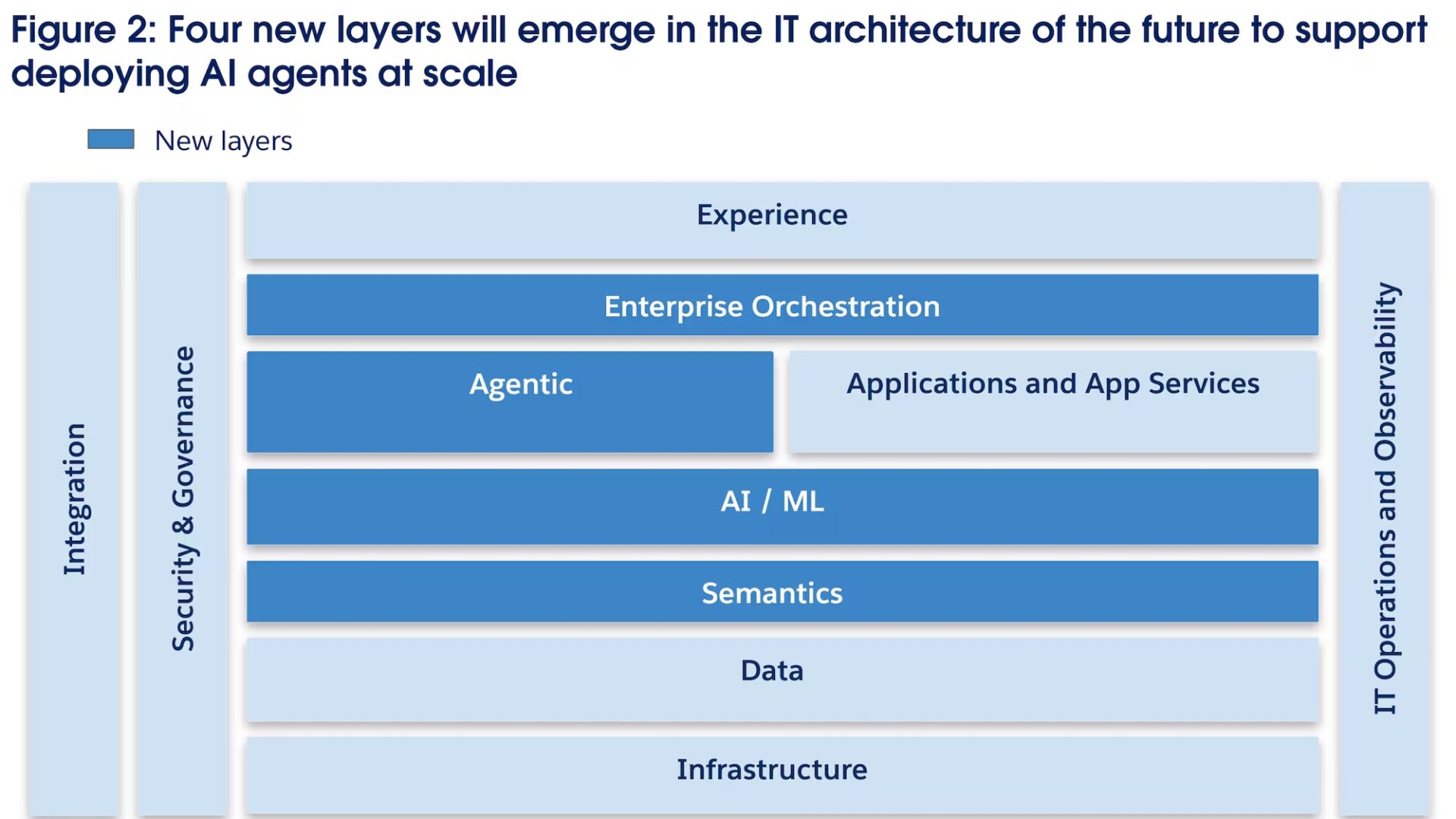
La BI doit se transformer pour devenir une architecture de services de données capable de délivrer des indicateurs fiables, traçables et surtout interopérables avec les nouveaux paradigmes de l’IA (RAG, architectures orientées agents, copilotes métiers).
Pour les DSI et CDO, ce virage est critique. Tant que la BI demeure une simple couche de restitution déconnectée d’une gouvernance forte, les pathologies classiques persistent :
- Désalignement sémantique et KPI divergents
- Shadow BI persistant avec l’Excel de « réassurance »
- Surcharge cognitive due à l’empilement de reportings silotés
Chez Smartpoint, nos experts Data & IA observent que la valeur ne réside plus dans le dashboard, mais dans la capacité à orchestrer des Data Products via via une couche sémantique transverse et un Metrics Layer unifié.
Pourquoi les dashboards ont atteint leurs limites ?
Les dashboards BI classiques saturent en indicateurs
Le dashboard reste un outil indispensable. Le vrai problème ? C’est la place centrale qu’il occupe aujourd’hui dans la BI alors qu’il n’est « que » la couche visible de l’architecture sous jaccente.
Avec le temps, les écrans se sont empilés : trop de KPI, vues multiples, filtres complexes. La lisibilité est en chute libre et les décisions approximatives. La BI dérive inexorablement vers un enchevêtrement de reportings, loin d’une plateforme de pilotage agile basée sur des données de confiance.
Cette saturation cache un mal plus profond. Les demandes incessantes de nouveaux indicateurs sont le symptôme d’une dette BI avec des metrics non fiables ou mal alignées sur les besoins métiers.
Le syndrome de l’Excel de la « vérification finale »
Lorsque l’utilisateur final extrait les données de son dashboard pour les retraiter localeur dans un tableur Excel, ce n’est pas par habitude … c’est par défiance envers le référentiel. Cette réassurance manuelle est symptomatique de l’échec d’une stratégie BI purement visuelle qui a mis de côté la fiabilité de sa couche sémantique.
Chez Smartpoint, nous analysons ce phénomène comme une rupture de la lignée de données (Data Lineage). Si le métier ressent le besoin de vérifier le chiffre, c’est que la BI n’a pas réussi à imposer une Single Source of Truth (SSOT) et les conséquences ne sont pas neutres :
- Désynchronisation décisionnelle : Chaque tableur devient un silo de données avec ses propres règles de calcul maison créant une entropie informationnelle majeure.
- Invisibilité de la donnée : La logique métier s’échappe du SI pour se concentrer dans des macros Excel opaques rendant toute maintenance ou évolution impossible.
- Risque de conformité et de sécurité : La multiplication de ces fichiers partagés fragilise la gouvernance et expose l’entreprise à des fuites de données sensibles.
Pour éradiquer ce phénomène, la réponse n’est pas de supprimer Excel mais de recentraliser l’intelligence métier au sein d’une architecture basée sur des Data Products. En déplaçant la logique de calcul du dashboard vers un Metrics Layer unifié, on garantit que le chiffre affiché est le même, quel que soit le point de consommation (Power BI, interface métier ou agent IA).
Nos experts Data IA accompagnent cette transition au sein des organisations pour restaurer la confiance et garantir que le pilotage de l’entreprise repose bien sur une donnée certifiée et non sur des intuitions recalculées en urgence.
Une BI trop rétrospective, pas temps réel
Conçus pour ingérer l’historique, les dashboards sont parfaits en post-mortem … mais les directions métiers attendent des insights immédiats (alertes stocks, fraude, marge dynamique, pilotage logistique fin., etc.).
Le batch processing reste pertinent pour de nombreux usages consolidés mais il ne suffit plus à lui seul pour les besoins de pilotage temps réel dans un contexte de volumes massifs de données. Il est nécessaire de mettre en place une ingestion continue, du streaming via Kafka ainsi que du monitoring et de l’alerting multi-canaux. Une architecture décisionnelle moderne intègre donc un historique fiable et une réactivité temps réel avec des objectifs de fraîcheur adaptés aux cas d’usage (quasi temps réel pour la fraude, consolidation différée pour la finance, etc.).
Le dashboard est devenu le symptôme d’une obésité informationnelle. La multiplication des tableaux de bord révèle surtout une difficulté à hiérarchiser l’information. Cette dérive transforme le SI décisionnel en un labyrinthe de reportings silotés où la lisibilité est sacrifiée au profit de l’exhaustivité. Pour les directions IT, cette dette BI se traduit par une maintenance croissante sans création de valeur proportionnelle.
L’IA révèle les limites des dashboards
La BI augmentée et les agents IA bouleversent tout. Désormais, les queries en langage naturel deviennent la norme, tout comme les explications automatisées de KPI, les comparaisons instantanées ou les détections d’écarts. À titre d’exemples, Microsoft Fabric Copilot génère des synthèses automatiques, ThoughtSpot sort du lot en search IA, tandis que Sisense (encore peu présent en France mais à suivre de près !) déploie des agents autonomes.
L’IA exploite les données disponibles mais elle ne corrige ni leur qualité ni leurs incohérences. Sans métriques versionnées ni sémantique stable, des dashboards divergents produisent des réponses rapides… mais complètement incohérentes. Et La crise de confiance s’installe alors irrémédiablement.
Luc Doladille, Directeur Conseil, Smartpoint
L’IA n’efface pas les failles architecturales sous-jacentes. Au contraire, elle les amplifie. Et pour performer, elle exige une BI mature : data products, metrics layer headless et pilotage temps réel intégré.
L’IA ne crée pas la donnée, elle l’orchestre. Sans métriques versionnées ni sémantique immuable, déployer des agents autonomes revient à automatiser le chaos. Nos experts Data IA insistent sur ce point : pour performer, l’IA exige une BI mature reposant sur des Data Products certifiés et un Metrics Layer headless, garantissant l’alignement entre l’insight généré et la réalité business.
Comment passer du reporting à une véritable architecture décisionnelle ?
De la logique dashboard à la production de la vérité métier
Migrer vers une architecture décisionnelle nécessite de s’affranchir des débats outilocentrés pour se concentrer sur l’intégrité sémantique. Chez Smartpoint, nous considérons que le dashboard ne doit plus être une destination finale en soi mais un simple point de consommation parmi d’autres (API, agents IA, apps). Cette bascule redéfinit la modernisation du SI Data, on ne livre plus un écran, on garantit une métrique métier immuable.
Structurer la BI autour de data products analytics
Pour briser la logique de « reporting projet par projet », l’approche par Data Products est pour nous un levier de scalabilité majeur. Nos experts Data IA préconisent de concevoir le système autour d’usages concrets (marge dynamique, performance supply chain, revenus, etc.) plutôt que sur des pipelines isolés. Chaque Data Product embarque :
- Un périmètre métier certifié et une modélisation en étoile (faits/dimensions)
- Une documentation des règles de calcul et des KPIs exposés
- Des contrôles de qualité automatisés et un ownership métier/IT identifié
Chez Smartpoint, nous sommes convaincus par l’approche Architecture-first plutôt que Outil-first. Cela permet d’éradiquer durablement les datamarts obsolètes au profit d’une intelligence partagée.
Faire le choix d’un pilotage temps réel avec une approche streaming-first
Si tous les usages ne nécessitent pas un traitement instantané, certains domaines liés par exemple à la fraude, aux stocks ou à l’expérience client exigent une réactivité forte que le Batch-only ne peut pas fournir. L’architecture décisionnelle moderne est hybride, c’est la somme de flux batch pour le consolidé et des flux continus via Kafka (ou solutions équivalentes) pour la criticité temporelle. Chez Smartpoint, nous concevons des plateformes data pour exposer la donnée via Snowflake, Microsoft Fabric ou Databricks, garantissant une fraîcheur de donnée optimale pour le monitoring et l’alerting IA sans briser la cohérence des KPIs.
Converger vers la logique headless BI
Le Headless BI est une véritable rupture technologique qui libère enfin les DSI du carcan des solutions monolithiques ! Nos experts Data IA recommandent cette approche pour découpler la couche sémantique (le Metrics Layer) de la couche de restitution (Power BI, Tableau, Excel ou interfaces IA). En transformant les métriques en actifs architecturaux versionnés, gouvernés et réutilisables, on garantit une cohérence parfaite quel que soit le canal de consommation des données.
Chez Smartpoint, nous délivrons des architectures data qui ont pour intérêts d’offrir :
- Agnosticité technologique : Réduction de la dépendance éditeur (vendor lock-in)
- Fluidité des migrations : Transition pilotée des systèmes legacy (Cognos, Business Objects) vers des stacks data modernes sans perte de logique métier
- Interopérabilité multi-outils : Une règle de calcul unique pour Excel, vos dashboards et vos portails applicatifs
- Compatibilité IA native : Fourniture d’un contexte sémantique structuré indispensable aux agents autonomes et au RAG
- Résorption de la dette BI : Refonte du moteur décisionnel pour une maintenance simplifiée et une scalabilité accrue
L’objectif est moderniser le cœur du réacteur décisionnel pour en faire un levier de performance durable et un socle prêt pour l’IA de demain.
Trajectoire de modernisation, du reporting à l’architecture décisionnelle
La modernisation de votre BI ne passe pas par un simple lift-and-shift technologique. Nos experts Data IA recommandent une approche incrémentale et pilotable, centrée sur la résorption de la dette technique et l’agilité métier.
1. Inventaire des data assets et cartographie de la dette BI
Cette première phase d’audit couvre l’ensemble de la chaîne de valeur décisionnelle :
- Typologie des assets : Identification des dashboards actifs vs. dormants, des datamarts redondants et des pipelines ETL/ELT critiques.
- Gouvernance et sémantique : Cartographie des couches sémantiques hétérogènes (BO, Cognos, Power BI) et des KPI critiques avec leurs différentes variantes.
- Flux et dépendances : Analyse des systèmes d’ingestion (batch vs temps réel) et des adhérences métiers/techniques.
Cet inventaire permet d’objectiver la dette BI en mettant en lumière les doublons, les coûts de run invisibles, les actifs intouchables non documentés et les risques de rupture de continuité de service. Chez Smartpoint, nous considérons que cette visibilité est un préalable indispensable à toute stratégie de désendettement technologique et de modernisation de votre plateforme BI.
2. Construire une Metrics Layer unifiée et versionnée
La seconde étape consiste à extraire l’intelligence métier des outils de restitution pour la centraliser dans une metrics layer souveraine. Tout l’enjeu est de passer à ce stade d’une logique de calcul pas toujours très claire à une vraie discipline d’architecture data rigoureuse.
Une metrics layer moderne, telle que conçue par nos experts Data IA, est :
- Documentée et testée pour garantir la fiabilité intrinsèque de la donnée
- Versionnée et traçable en s’appuyant sur des approches déclaratives (YAML, dbt, modèles sémantiques versionnés) selon la stack data cible (Snowflake, Fabric, Databricks)
- Et alignée pour assurer une cohérence absolue entre les règles métier et leur exécution technique.
Chez Smartpoint, nous pensons que l’outil technologique utilisé est secondaire. C’est la discipline imposée par l’architecture Data et la centralisation des métriques qui garantissent la pérennité du SI Décisionnel et sa capacité à supporter les futurs cas d’usage de l’IA.
3. Industrialiser le SI décisionnel avec les Data Products et l’IA-Readiness
La finalité d’une bonne trajectoire de modernisation ne consiste pas à livrer un projet mais à établir un mode de production industriel. Le Data Product est le noyau où chaque domaine métier devient responsable de ses actifs informationnels, exposés via des interfaces normalisées. Cette approche transforme le SI décisionnel en une plateforme de services data prête à alimenter les architectures de Generative BI.
Et pour que cela soit efficient, la plateforme doit répondre à 3 impératifs :
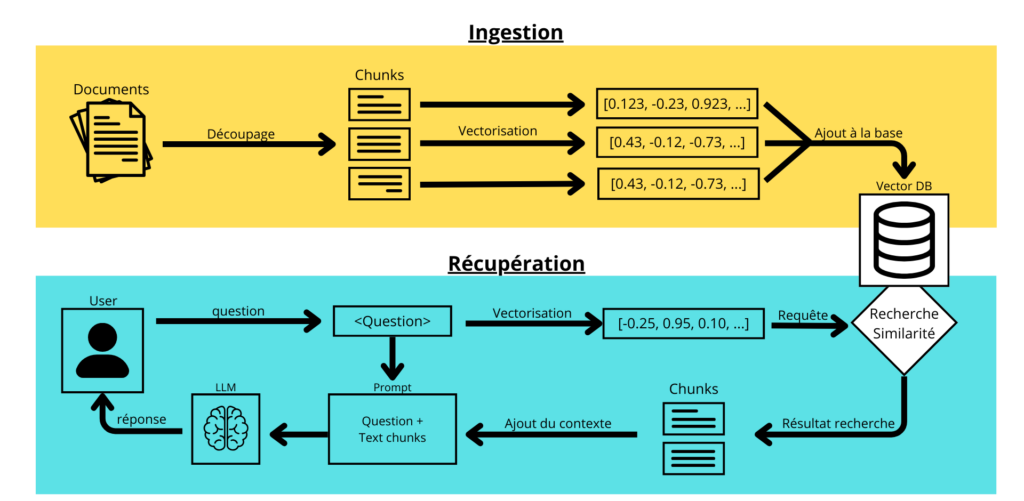
- L’interopérabilité sémantique : Garantir que le Metrics Layer centralisé alimente indifféremment les LLM via des techniques de RAG (Retrieval-Augmented Generation) et les outils de dataviz traditionnels éliminant ainsi toute dissonance cognitive entre l’IA et l’humain.
- Le cycle de vie DevOps appliqué à la Data : Automatiser les tests de régression sur les KPIs et le déploiement continu (CI/CD) des modèles de données pour réduire le Time-to-Market des nouveaux indicateurs. À lire sur ce sujet « Voici venu le temps des DataOps« .
- Le pilotage par la valeur (FinOps & Data Usage) : Monitorer l’adoption réelle des produits de données pour décommissionner les actifs obsolètes et optimiser la consommation des ressources cloud (Snowflake, Fabric ou Databricks).
4. Consolider l’architecture par une gouvernance industrialisée
La dernière étape de la trajectoire, et souvent sous-estimée, consiste à industrialiser la gouvernance pour transformer le SI Data en un environnement auto-porteur et auditable. Chez Smartpoint, nous considérons que la gouvernance des données ne doit plus être un goulot d’étranglement, mais une infrastructure invisible qui sécurise chaque interaction avec la donnée.
Pour garantir cette pérennité, nos experts en gouvernance des données déploient des cadres de gouvernance qui s’appuient sur :
- Une sécurité granulaire et dynamique : Mise en œuvre de politiques de RLS / CLS (Row-Level Security / Column-Level Security) et gestion fine des rôles (RBAC) pour garantir que l’accès à la donnée soit strictement proportionné à l’usage métier.
- Une traçabilité et observabilité bout-en-bout : Maîtrise du lineage fonctionnel et technique pour cartographier le parcours de la donnée, du système source jusqu’à l’insight IA, couplée à un monitoring de fraîcheur en temps réel.
- L’auditabilité et l’observabilité des pipelines : Automatisation de la surveillance des flux pour détecter les dérives (data drift) et garantir l’auditabilité permanente des usages, condition sine qua non pour l’IA régulée (préparation Data Act).
Le rôle de la sémantique et de la couche métrique
La couche sémantique constitue probablement la brique la plus stratégique (et la plus souvent négligée) de l’urbanisation des données. Elle est le liant entre l’infrastructure technique (ERP, CRM, WMS, logs) et les concepts métiers manipulés au quotidien par les directions opérationnelles.
Traduire la complexité en langage métier actionnable
La couche sémantique ne fait pas que stocker les données, elle traduit une complexité technique brute en objets décisionnels utilisables et gouvernables. Qu’il s’agisse de définir une marge nette, un taux de churn ou un retard de livraison, cette couche garantit que chaque acteur de l’entreprise parle la même langue. Sans ce socle, chaque outil de dataviz recrée sa propre logique et on aboutit à de multiples indicateurs divergents où personne n’est d’accord sur la réalité des chiffres…
Standardiser via un dictionnaire partagé et des règles d’agrégation
Pour nos experts Data IA, la sémantique doit évoluer d’un simple dictionnaire de données passif à un véritable système d’exécution de la cohérence. Et cela demande une rigueur architecturale qui apporte une valeur ajoutée immédiate grâce à :
- L’explicabilité des règles d’agrégation : Garantir que les dimensions (temps, géographie, Business Unit) sont appliquées de manière immuable sur l’ensemble de la stack.
- La gouvernance du changement et versioning : Assurer la traçabilité des évolutions de calcul pour maintenir un data lineage impeccable.
- L’unification des environnements hybrides : Réconcilier, au sein d’une même vérité, la BI legacy (Cognos, SAP Business Objects), les plateformes cloud modernes (Snowflake, Fabric) et les nouveaux usages liés à l’IA générative.
Chez Smartpoint, nous sommes convaincus que cette standardisation répond à l’instabilité sémantique qui empêche le déploiement des agents autonomes.
Décommissionnement ou migration Cognos, Business Objects, Talend : penser système, pas brique
Le remplacement d’une brique historique telle que Cognos, Business Objects ou Talend est un cas d’école de la dette BI ! L’erreur est de moderniser l’outil en surface sans repenser l’architecture data globale, ce qui ne fait que déplacer les problèmes vers une nouvelle technologie. Pour nos experts Data IA, cela va au-delà de la simple migration technique.
Tout l’enjeu est de découpler définitivement la logique métier des outils de restitution pour préparer nativement la compatibilité avec les futurs usages de l’IA. C’est précisément là que l’approche Architecture-first fait toute la différence : au lieu de transférer une dette technologique vers le cloud, nous mettons en place les processus nécessaires pour la résorber progressivement. En adoptant cette vision systémique, la modernisation des systèmes décisionnels permet d’activer une transformation durable plutôt qu’un éternel recommencement technologique.
La BI de 2026 est un système de pilotage
Le temps de l’accumulation de Dashboards est terminé. La priorité est d’adopter une architecture Data orientée services et dans l’intégrité de votre couche sémantique. Tout l’enjeu est de briser le cycle de la dette technique pour instaurer une culture de la donnée certifiée, fluide et nativement compatible avec les exigences de l’IA.
Nos experts Data IA vous accompagnent dans cette trajectoire, de l’audit de votre patrimoine existant à l’implémentation de Data Products scalables et de Metrics Layers souveraines. Ne laissez plus l’obsolescence de vos outils legacy freiner le business.
Prêt à transformer votre SI Décisionnel en moteur d’innovation ? Nos experts Data IA vous accompagnent dans la modernisation de votre architecture data :
- Audit 360° de votre dette BI : Cartographie de vos assets, identification des silos et évaluation des coûts de run invisibles.
- Design d’architecture IA-Ready : Définition de votre trajectoire vers le Headless BI et le streaming-first.
- Migration sécurisée de vos solutions legacy : Transition pilotée de vos environnements Cognos, Business Objects ou Talend vers les standards de 2026.
Contactez nos experts pour un premier échange.
Pour aller plus loin :
- Modernisation de la BI et du SI Data : réduire la dette de la plateforme décisionnelle pour alimenter l’IA : https://www.smartpoint.fr/modernisation-bi-dette-si-decisionnel/
- Qu’est-ce qu’une couche sémantique ? https://www.ibm.com/fr-fr/think/topics/semantic-layer
- Q’est ce qu’in data product https://www.datagalaxy.com/fr/blog/data-product-definition/
Vos questions, nos réponses :
Pourquoi les dashboards BI son remis en cause 2026 ?
Parce qu’ils restent souvent centrés sur la restitution et non sur la cohérence des métriques. Sans couche sémantique unifiée ni metrics layer, les dashboards multiplient les KPI divergents et alimentent la shadow BI.
Qu’est-ce qu’une architecture décisionnelle BI moderne ?
Une architecture décisionnelle est un système structuré qui combine plateforme data, orchestration, couche sémantique, metrics layer et canaux de consommation (BI, API, IA) pour produire une vérité métier fiable et gouvernée.
Qu’est-ce qu’une metrics layer et à quoi ça sert ?
Une metrics layer est une couche métrique centralisée qui standardise les définitions de KPI (chiffre d’affaires, marge, churn, stock, etc.). Elle permet de partager les mêmes règles de calcul entre les outils BI, les exports Excel, les applications métiers et les usages IA.
Pourquoi la couche sémantique est-elle essentielle dans la modernisation BI ?
La couche sémantique traduit les données techniques (ERP, CRM, WMS, logs) en concepts métier exploitables. Elle garantit que les indicateurs sont compris et calculés de façon homogène, ce qui est indispensable pour réduire la dette BI et fiabiliser le pilotage.
Qu’est-ce que le headless BI ?
Le headless BI consiste à découpler la logique métier (couche sémantique et metrics layer) de la couche de restitution (dashboards, Excel, portails, agents IA). Cette approche réduit la dépendance aux outils, facilite les migrations BI et améliore l’interopérabilité.
Comment passer d’un reporting classique à une architecture décisionnelle moderne ?
La trajectoire la plus efficace est incrémentale : inventaire des data assets, cartographie de la dette BI, unification des KPI critiques via une metrics layer, structuration en data products analytics, puis industrialisation de la gouvernance (RLS/CLS, lineage, observabilité).
Faut-il abandonner le batch pour passer au temps réel ?
Toujours pas ! Une architecture décisionnelle moderne combine batch et streaming. Le batch reste pertinent pour les usages consolidés, tandis que le streaming-first répond aux besoins de pilotage temps réel (fraude, stock, alerting, expérience client).
Pourquoi la modernisation BI est-elle un prérequis pour l’IA ?
Parce que les copilotes analytiques, la BI augmentée et les agents IA s’appuient sur des métriques stables et une sémantique fiable. Si la plateforme décisionnelle est fragmentée, l’IA accélère l’accès à des données incohérentes au lieu d’améliorer la décision.