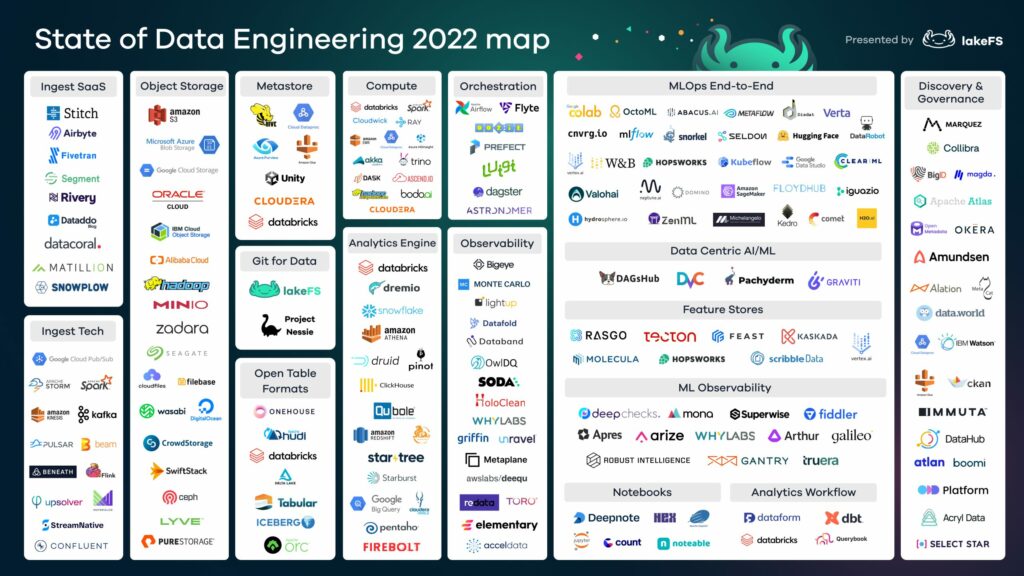
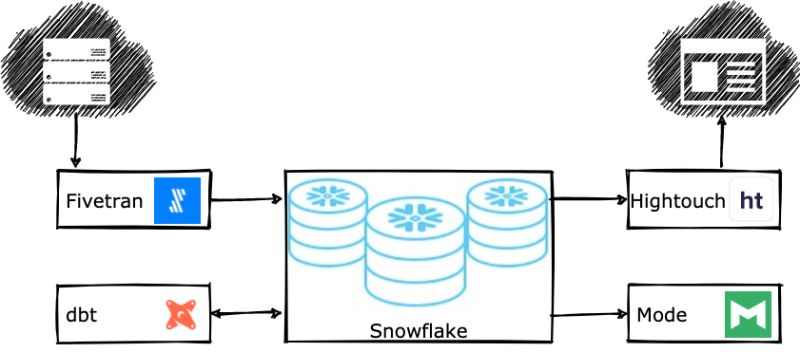
Stack technologique
Dans la data, c’est exactement comme dans le développement logiciel de produits ! Avant, il y avait des développeurs spécialisés front et d’autres back-end, d’autres chargés que de la mise en production, d’autres des tests, etc. En data, on avait aussi des DBA. Chacun avait un rôle bien précis. Mais depuis les pratiques Agile, le DevOps, le CI/CD et l’automatisation des tests se sont démocratisés en même temps que la course à l’innovation et les contraintes de time-to-market se sont accentuées.
Être ingénieur data aujourd’hui ne se résume plus à la conception de Datawarehouse, la mise en place d’ETL, le lancement de requêtes SQL et la restitution dans des tableaux de bord. Certes, il ne s’agit pas d’être spécialiste en tout mais un ingénieur data fullstack a désormais des connaissances étendues dans de nombreux domaines.
Yazid Nechi, Président de Smartpoint
Comment reconnaitre un bon ingénieur Data ?
- Il sait programmer ! Il maîtrise en effet au moins un langage de programmation et chez smartpoint, c’est plusieurs : Java, Python, Scala pour les incontournables.
- Il connait les outils du big data comme Hadoop, Hive, Spark, Pig Sqoop
- Il sait concevoir et exploiter un Data Warehouse et pour ce faire, les meilleurs outils à maîtriser sont Amazon Redshift, Google Big Query et bien entendu Snowflake. Mener des actions d’ETL étant indispensables à sa fonction, il a également des compétences en Talend, informatica entre autres.
- C’est un expert en bases de données relationnelles (SQL) qu’elles soient analytiques ou transactionnelles (OLTP, OLAP).
- Il maîtrise aussi les bases de données en NoSQL qui sont de différentes natures en fonction du modèle de données
Architecture
C’est la base, il doit comprendre comment sont organisées les données et quels sont les objectifs en termes de traitement et de gestion des données. Cela suppose aussi d’avoir une bonne culture générale sur les nouvelles méthodes de data ingestion (comme Kafka), les différentes alternatives de stockage ainsi que les normes de sécurité pour la protection des données (dont la gestion des droits et des authentifications).
SQL
C’est une compétence certes traditionnelle mais toujours indispensable !
ETL (ou ELT)
C’est la base du métier : mettre en place le pipeline de données pour capturer, transformer et charger dans le système cible. Cela demande des compétences en modélisation des données mais aussi la connaissance d’un ou plusieurs outils. Citons évidemment Talend, Informatica mais aussi des nouveaux entrants comme Fivetran ou Stitch.
Visualisation de données
C’est un incontournable même si historiquement, c’est une compétence davantage attendue chez les analystes de données mais dans le même logique de maîtrise du flux de données de bout en bout, nous encourageons nos ingénieurs data à connaître au moins un des outils comme Tableau ou plus récemment Looker ou ThoughtSpot.
Spark
C’est un must-have en ingénierie des données, Spark est le framework open source désormais incontournable en raison notamment de sa très riche bibliothèque pour le traitement par lots, le streaming, les analytics, le ML, la datascience, etc.
Connaissances en programmation
Avant SQL et un outil comme Informatica suffisait. Aujourd’hui un ingénieur data intervient dans le pipeline CI/CD et pour le maîtriser, il est nécessaire aujourd’hui d’avoir aussi des compétences en langages de programmation comme Java, Python ou encore Scala.
Expériences en développement
L’intégration et le développement continus (CI/CD) sont aujourd’hui la norme (ou presque) ainsi que le DevOps et cela vaut également pour l’ingénieur Data. Il doit avoir des connaissances en gestion de la base de code, en testing, etc. La connaissance d’outils tels que Jenkins, DataDog, Gitlab, Jira sont donc un vrai plus !
L’incontournable cloud !
Impossible aujourd’hui de passer à côté de cette compétence alors que les entreprises ont de plus en plus recours au cloud pour accéder, traiter, gérer, stocker et sécuriser leurs données. Cela permet de bénéficier de puissance de traitement et de calcul inégalé sans parler de la scalabilité. Chaque ingénieur Data se doit de connaître au moins un cloud provider comme GCP ou Azure.
Vous cherchez un Data engineer fullstack avec toutes ces compétences ? Il est surement chez Smartpoint 🤩 Vous voulez gagnez en compétences et vous investir dans de supers projets data ? Nous recrutons aussi aujourd’hui nos futurs talents !
Sources :
- Comparatif d’Airbyte entre Fivetran et Sticth : https://airbyte.com/etl-tools/fivetran-vs-stitch
- Article de Gururaj Kulkarni https://blog.devgenius.io/who-is-full-stack-data-engineer-fsde-b997ce0cafd8
- Spark https://spark.apache.org/