Paris, le 4 décembre 2025 — Smartpoint, pure-player Data & Intelligence Artificielle fondé en 2006, annonce l’obtention de l’agrément Crédit Impôt Recherche (CIR) délivré par le Ministère de l’Enseignement Supérieur et de la Recherche. Cette reconnaissance atteste de la capacité de Smartpoint à mener des travaux de R&D dans les domaines de la data, de l’IA, des LLM, de la vectorisation, de l’automatisation avancée et de l’industrialisation de plateformes Data modernes via les pratiques DataOps et LLMOps.
Elle place Smartpoint parmi les rares ESN françaises reconnues comme organisme de recherche externalisé, habilité à mener des projets éligibles au dispositif CIR pour le compte de ses clients dans un cadre scientifique évalué et validé par l’État.
Pourquoi l’agrément CIR de Smartpoint atteste de notre expertise Data & IA ?
L’agrément CIR atteste le fait que Smartpoint ne se limite pas à un rôle d’intégrateur ou de cabinet de conseil. Il reconnait la capacité de notre SmartLab à concevoir et à industrialiser des solutions data véritablement innovantes : architectures data modernes (Data Mesh, Data Fabric, Lakehouse, event-driven) conçues pour être cloud-native et AI-ready, plateformes scalables, pipelines automatisés, modèles sémantiques vectoriels, agents IA, copilotes métiers, gouvernance IA et privacy by design.
Le ministère a confirmé la solidité scientifique des travaux menés par Smartpoint, la maîtrise des méthodes expérimentales, la structuration documentaire et la capacité de Smartpoint à concevoir des solutions innovantes répondant à des problématiques techniques complexes. Les recherches engagées en data engineering, IA, optimisation des pipelines et sécurité des systèmes IA répondent aux critères du CIR.
Comment le Crédit Impôt Recherche réduit le budget de vos projets Data & IA ?
Les prestations délivrées par Smartpoint peuvent être intégrées dans la base de calcul du Crédit Impôt Recherche. Une entreprise cliente de Smartpoint peut récupérer jusqu’à 30 % du montant des dépenses de R&D sous-traitées, sous réserve d’un projet globalement éligible.
Ce mécanisme permet de réduire de manière importante les coûts relatifs aux phases d’exploration, de conception, de prototypage, d’optimisation ou de tests IA. Les entreprises peuvent ainsi multiplier les POCs, accélérer la construction de MVP et industrialiser plus rapidement leurs modèles tout en maîtrisant les budgets de la DSI.
En quoi l’expertise scientifique de Smartpoint est une valeur ajoutée pour vos travaux Data / IA ?
L’agrément reconnaît la qualité scientifique du SmartLab, laboratoire d’innovation dédié aux technologies Data & IA. Nos équipes travaillent sur l’IA générative et les modèles LLM, les pipelines DataOps et LLMOps, les architectures RAG appuyées sur des bases de données vectorielles, l’observabilité et la sécurité des systèmes IA ainsi que sur la conception d’agents autonomes. Nos clients bénéficient ainsi d’une capacité de R&D externalisée structurée, reproductible et documentée, répondant aux standards du CIR. Smartpoint accompagne également les organisations sur les volets méthodologiques et documentaires liés à la valorisation de leurs travaux.
Mehdi Gargouri, Directeur Général Smartpoint
Quels types de projets Data & IA sont finançables par le CIR ?
Un large spectre de travaux de R&D relatifs à l’exploitation et à l’ingénierie des technologies Data / IA peut être éligible au CIR, dès lors qu’ils visent à dépasser l’état de l’art et reposent sur une démarche expérimentale structurée. Smartpoint intervient dans le cadre CIR sur des projets de refonte innovante de pipelines data, de développement de services IA scalables, de vectorisation et d’enrichissement sémantique des données, de réduction de la dette technique data lorsqu’elle implique la mise au point de nouveaux procédés, de conception de frameworks IA souverains et multi‑cloud ou encore sur des travaux de recherche autour d’architectures data de nouvelle génération.
Pour exemple, nous recommandons des projets AI-Ready dès leur conception intégrant sécurité, observabilité, gouvernance, conformité au RGPD et à l’AI Act, ce qui favorise leur éligibilité car de véritables verrous technologiques existent bel et bien aujourd’hui.
Comment profiter de l’agrément CIR et optimiser les coûts de vos projets Data & IA innovants ?
Smartpoint est reconnue comme une ESN pure-player Data & IA capable de mener des travaux de recherche complexes, de transformer des problématiques technologiques en solutions concrètes et sécurisées ; et de déployer ces innovations à l’échelle. Pour les entreprises qui souhaitent accélérer leur stratégie Data & IA, collaborer avec Smartpoint, c’est conjuguer innovation, optimisation des coûts et sécurisation des investissements R&D.
Choisir un prestataire agréé CIR vous permet de financer des projets hautement technologiques, qu’il s’agisse de moderniser des pipelines, d’explorer de nouveaux modèles IA, de concevoir une architecture data IA-ready ou d’industrialiser des agents intelligents.
Avec plus de 350 consultants et experts spécialisés en architecture data, IA / ML, modernisation de plateforme Data, BI, data engineering DataOps LLMOps et gouvernance ; Smartpoint est un partenaire de référence pour les organisations qui souhaitent structurer, accélérer ou industrialiser leurs initiatives Data & IA. L’agrément CIR vient consolider cette position et offrir un cadre financier avantageux pour les projets les plus ambitieux.
Vous envisagez de lancer ou d’accélérer un projet Data ou IA ?
Smartpoint vous accompagne dans la structuration, la recherche, l’expérimentation et l’industrialisation de vos solutions tout en optimisant vos investissements grâce au CIR. Contactez-nous pour évaluer l’éligibilité de vos projets et bâtir une stratégie Data & IA innovante, performante et financièrement optimisée.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
pipeline data
Automatiser le pipeline data, le must-have en data engineering
L’automatisation des pipelines data ne sert pas uniquement à gagner du temps, même si c’est déjà énorme. Automatiser la collecte, la transformation et l’exploitation des données permet de réduire les coûts, de préparer l’industrialisation de l’IA et c’est désormais incontournable pour maîtriser la gouvernance des données.
Ce n’est plus possible en 2025 de voir des pipelines développés à la main, dupliqués, patchés, monitorés « en mode pompier » puis complètement réécris dès qu’un schéma change. C’est encore alourdir la dette technique et ralentir toute la chaine de création de valeur.
Chez Smartpoint, ESN spécialisée en Data / IA, nous recommandons de mettre en œuvre des plateformes automatisées, scalables et surtout évolutives : pipelines pilotés par les métadonnées, orchestration intelligente, tests continus, monitoring avancé. C’est la base du DataOps moderne et la base pour préparer le développement des LLMs, du RAG et des agents IA.
La plupart des organisations devraient adopter des SOAPs (service orchestration and automation platforms) d’ici 2029 pour orchestrer les data pipelins et les workloads (…) et l’automatisation libère 40% du temps des engineers pour des tâches à plus forte valeur ajoutée, réduisant ainsi les coûts opérationnels de 20-30%. D’ici 2027, Gartner prédit que 50% des décisions seront automatisées par des agents IA qui se basent sur des pipelines data fiables.
Que ce soit dans le cadre d’une migration cloud, d’une intégration d’une nouvelle application ou d’une refonte de la BI, c’est toujours le même scénario qui se répète inlassablement : un pipeline par table, du code dupliqué, des mappings codés en dur, des tests plus ou moins faits et une logique de traitement très fragile.
Résultat, la dette technique ne cesse de s’alourdir et les systèmes sont de plus en plus difficiles à faire évoluer.
La plupart du temps, ces pipelines sont peu ou pas documentés. Et quand la documentation existe bel et bien, elle n’est pas maintenue. Les équipes passent l’essentiel de leur temps à corriger ou à redéployer. Le schema drift (colonnes ajoutées, renommées, supprimées ou formats modifiés entraînant des ruptures dans le pipeline) est géré dans l’urgence et chaque changement enclenche un effet domino sur les workflows.
Chaque nouveau besoin métier entraine son lot de modifications : colonnes/formats, évolution de la granularité, ingestion de données faiblement typées (c’est à dire imprévisibles, instables ou encore non normalisées) ou arrivée d’un flux d’événements. Et avec la généralisation du streaming, des bus d’événements et des architectures distribuées, ces pipelines rigides se fissurent au moindre changement. Ils ne sont tout simplement pas conçus pour absorber la variabilité pourtant devenue la norme dans les SI Data modernes.
La conséquence est toujours la même : on patch, on reteste, on recasse, on recommence. C’est un cycle infernal. On n’est plus dans le data engineering mais dans la maintenance continue et cela se fait au détriment de la qualité, de la scalabilité et de la capacité d’innovation.
Les pipelines data traditionnels ont atteint leurs limites. Pas fiables, pas scalable et impossible à gouverner dans la durée. Pourtant les données alimentent désormais l’IA générative, des copilotes métier, les agents autonomes, les exploitations temps réel, la mesure de performance ou encore de l’automatisation intelligente.
On ne peut pas construire des copilotes IA sur du code fragile ni sur des workflows artisanaux. Industrialiser l’IA, c’est d’abord industrialiser les flux de données et cela passe par l’automatisation.
Place aux pipelines data intelligents !
Les pipelines intelligents (pilotage par métadonnées, auto-scaling, intégration native avec les outils de monitoring, etc.) sont indispensables dans toutes architectures data modernes. Concrètement, il ne s’agit plus de coder pipeline par pipeline mais d’utiliser des composants dynamiques pilotés par la configuration, les métadonnées et une orchestration automatisée.
Les pipelines intelligents s’appuient sur une logique déclarative : les règles métiers, les schémas, les mappings, les contrôles qualité et même les règles d’ingestion sont définis dans des métadonnées versionnées. Le pipeline metadata-drivenne contient plus la logique métier, il l’interprète.
Une nouvelle table ? On ajoute une ligne dans la configuration. Une colonne supplémentaire ? Le système s’adapte. Un changement de format ? Aucun redeploiement n’est nécessaire. Le pipeline data devient un moteur générique, capable d’orchestrer des centaines de flux sans nuire à la stabilité ou à la qualité des données.
Cela ouvre la voir l’automatisation de l’ensemble de la chaîne data : ingestion, transformation, contrôle qualité, lineage, documentation et monitoring. Et cela fonctionne indifféremment dans des écosystème hybrides, multi-cloud ou temps réel. Et cela permet d’envisager demain des pipelines capables d’être enrichis, voire générés par l’IA.
Un pipeline Data manuel nécessitait plusieurs semaines de développement et 1 semaine de tests à chaque modification de schéma. Un pipeline intelligent s’adapte automatiquement en quelques heures et sans intervention humaine.
Luc Doladille, Directeur Conseil, Smartpoint
Les avantages d’un pipeline intelligent ? Vitesse, scalabilité, observabilité, résilience, cloud-native, IA-read
Un pipeline intelligent accélère radicalement la vitesse du delivery ! Alors que la moindre évolution demandait aux data engineers de réécrire, copier ou patcher, l’automatisation permet de livrer à une vitesse inégalée. Une nouvelle table, une variation de schéma ou l’intégration d’un nouvel applicatif ne nécessitent plus de développement spécifique : il suffit d’ajuster la configuration. Vos équipes Data ne sont plus débordées à chaque demande métier.
Cette approche apporte également une scalabilité immédiate. Là où l’on devait construire autant de pipelines que de tables, un seul pipeline paramétrable suffit. Le système s’adapte automatiquement aux formats, aux volumes, aux règles de qualité ou encore la fréquence d’ingestion, sans multiplier les scripts, ni dégrader la performance ou la maintainabilité. Les équipes passent de la « production artisanale » à une logique industrielle.
L’observabilité devient native et non plus un chantier de seconde zone. Un pipeline automatisé expose nativement ses SLA, ses logs, sa traçabilité, ses métriques de qualité et son niveau de dérive. Cela permet de piloter les flux, d’anticiper les incidents, de garantir la conformité et d’alimenter une gouvernance des données alignée avec les exigences réglementaires (Data Act, AI Act, RGPD). Le pilotage du SI data gagne en maîtrise, en transparence et en auditabilité.
Cette automatisation renforce aussi la résilience. Lorsqu’un schéma évolue, lorsqu’une colonne se rajoute, lorsqu’un format change ou qu’un flux d’évènements (event streaming) est introduit, le pipeline continue de fonctionner car il est piloté par la configuration. On ne “répare” plus, on ajuste. Résultat, un système moins fragile, moins coûteux et surtout capable d’évoluer à la vitesse de besoins par nature évolutifs.
Ce modèle est intrinsèquement cloud-native. Il s’intègre dans Databricks, Azure Data Factory, Airflow, AWS Glue, Google Cloud Dataflow ou encore Synapse. Il s’adapte aux environnements hybrides, multi-cloud ou distribués. Ce n’est pas encore une couche supplémentaire mais le socle de l’ingénierie data moderne.
Et surtout, il ouvre la voie à un futur IA-ready. Les métadonnées deviennent une source de vérité et le carburant des copilotes data et des « assistants IT ». L’automatisation des pipelines n’est pas une simple optimisation, c’est ce qui permet de passer à une ingénierie augmentée par l’IA où les systèmes pourront (bientôt) s’autoconfigurer et s’auto-adapter.
On ne modernise le SI Data en rajoutant des pipelines. L’objectif est de changer d’échelle en automatisant leur conception, leur gestion et leur gouvernance. Le data engineering devient alors une plateforme, pas un chantier ouvert permanent.
Luc Doladille, Directeur Conseil
DataOps + LLMOps : l’automatisation devient le cœur du SI
Le pipeline data n’est plus un simple outil d’ingestion, de nettoyage et de transformation. Les pipelines qui nourrissent désormais les modèles d’IA, alimentent les embeddings, structurent les data products, orchestrent les agents documentaires et outillent les copilotes métier. Ils assurent également la continuité entre données brutes, décisions en temps réel et automatisation des processus.
Aujourd’hui DataOps et LLMOps convergent. L’un se concentre sur la qualité, la fiabilité et la gouvernance. L’autre permet l’entraînement, le déploiement, le monitoring et l’amélioration continue des modèles. Ensemble, ils constituent la chaîne indispensable pour exploiter l’IA en production.
Sans pipelines automatisés, pas d’IA opérationnelle. Pas de modèles fiables. Pas d’agents performants. Et certainement pas de passage à l’échelle. L’automatisation est devenu un prérequis de toute architecture data & IA moderne.
Exit l’ingénieur data qui passait ses journées à coder des pipelines ou à copier/coller des script. L’automatisation n’est pas qu’une question de gain de productivité. Dans un SI moderne, fait d’architectures distribuées, de flux temps réel et d’intégration de l’IA, l’enjeu est maintenant de concevoir des systèmes capables de générer les pipelines, les adapter et les maintenir automatiquement.
Chez Smartpoint, nos data engineers conçoivent des modèles dynamiques, automatisent les mappings, mettent en place tous les mécanismes de contrôle qualité, développent des frameworks réutilisables et garantissent également la gouvernance IT. En clair, Ils interviennent sur la standardisation, la scalabilité, l’observabilité et la résilience.
Et ce changement creuse le fossé entre les DSI qui subissent et celles qui sont en capacités d’industrialiser, d’automatisent et de s’équiper d’un socle technique solide IA-ready.
Concrètement, comment mettre en place un pipeline automatisé ?
Concevoir un pipeline data automatisé ne se résume ni à installer un orchestrateur, ni à remplacer un script par un job cloud ! C’est une transformation qui se fait dans le temps de manière progressive, structurée et surtout pensée pour durer. Voici notre manière de procéder :
Avant de penser à l’automatisation, il est nécessaire d’évaluer ce qu’il est possible de faire. Nous commençons classiquement par une cartographie des flux critiques. Lors de cette étape, nous nous concentrons sur l’identification de tout ce qui est basé sur du code en dur, les pipelines qui génèrent de l’instabilité et tous les traitement qui ne sont pas documentés. Ce diagnostic nous permet de mesurer la dette technique réelle, de prioriser et de mesurer les gains que l’ont peut attendre.
Adopter des pipelines intelligents suppose qu’on ait la bonne architecture data pour les supporter : stockage unifié, data catalog centralisé, orchestration cohérente, gestion des métadonnées, versionning, (…). Il ne s’agit donc pas de rajouter « une couche » de plus mais bien de mettre en place une architecture « minimale » solide, scalable et gouvernable.
3. Le choix de la stack technologique
En fonction de votre écosystème IT, des choix que vous avez fait, des usages attendus et de votre niveau de maturité data, nous vous recommandons des outils et des technologies adaptées à votre SI (et son évolution future).
Ceci étant dit, la stack que nous déployons régulièrement chez nos clients est composée de Databricks, Delta Lake, Azure Data Factory, Airflow, Spark, Iceberg, AWS (AWS Glue et Lambda) et Google (Dataflow et Big Query).
4. Une logique déclarative pilotée par les métadonnées
C’est sur ce point qu’il y a le plus de changement car un pipeline automatisé n’est pas codé mais interprété. C’est à cette étape que l’on passe à une véritable plateforme data-engineering scalable. Le framework interprète les configurations versionnées (SQL, YAML, JSON), orchestre les traitements, gère les changements de schéma et documente l’exécution.
5. Observabilité by-design
Un pipeline automatisé expose nativement ses logs, métriques, SLA, lineage et alertes de dérive. Ces contrôles en continu permettent de piloter la disponibilité et la qualité mais aussi d’anticiper les incidents et de garantir la conformité réglementaire (RGPD, Data Act, AI Act).
6. Usages IA
Une fois ces fondamentaux en place, on est en capacités de mettre en place les pipelines IA. En effet, L’automatisation permet de rendre vraiment l’IA opérationnelle : vectorisation, ingestion temps réel, alimentation des modèles et orchestration des agents.
Pour aller plus loin
Automatiser les pipeline data, ce n’est pas que accélérer les étapes ingestion/nettoyage/transformation ou réduire les tâches manuelles, c’est tendre vers une plateforme data-engineering en capacités de gérer les changements, d’auto-documenter les traitements et d’alimenter l’IA en continu. Cela permet de passer du POC IA à la prod.
Chez Smartpoint, nous vous accompagnons dans cette transformation de votre système data : architecture modulaire, DataOps/MMLOps, pipelines pilotés par les métadonnées et copilotes IA pour optimiser et auto-adapter les flux. Vous souhaitez mettre en place une plateforme data automatisée et IA-ready ? Contactez-nous.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Qu’est ce qu’un pipeline data automatisé ?
Un pipeline data automatisé est un flux de traitement qui s’adapte aux changements de format, de volume et de source sans nécessiter de recodage manuel. Il s’appuie sur des métadonnées, une orchestration centralisée et des tests continus pour fiabiliser l’ingestion, la transformation et la mise à disposition des données.
Pourquoi automatiser les pipelines data ?
Parce que les SI Data sont maintenant distribués, hybrides et en temps réel. Automatiser les pipelines Data permet de réduire la dette technique, d’accélérer la mise en production, d’améliorer la qualité des données et de préparer l’industrialisation de l’IA (LLM, RAG, agents, embeddings…).
Qu’est qu’un pipeline metadata-driven ?
C’est un pipeline où les règles métiers, les mappings, les schémas et les mécansimes d’ingestion ne sont plus codés mais décrits dans des métadonnées versionnées (YAML, SQL, JSON). Le pipeline interprète ces règles, ce qui permet de gérer automatiquement les évolutions.
Comment gérer le schema drift ?
Le schema drift se gère via des pipelines déclaratifs capables de détecter automatiquement les changements de colonnes, types, granularité ou formats. Une approche metadata-driven évite les recodages répétitifs et réduit les ruptures sur les workflows.
Quelles technologies pour automatiser les pipelines data ?
Les stacks les plus utilisées dans les architectures Data modernes incluent Databricks (Delta Live Tables, Workflows), Airflow, Spark, Iceberg, Azure Data Factory, BigQuery, AWS Glue et Google Dataflow. Le choix dépend des workloads, du cloud et du niveau de maturité DataOps.
Quelle est la différence entre DataOps, MLOps et LLMOps ?
Le DataOps garantit la qualité et la gouvernance des données. Le MLOps gère la production des modèles de machine learning classiques. Le LLMOps étend ces pratiques aux LLMs, vectorisation et RAG. Automatiser les pipelines permet de connecter ces trois chaînes sans rupture.
Pourquoi automatiser les pipelines est indispensable pour l’IA générative ?
Parce que les modèles d’IA consomment des données en continu, parfois en streaming et nécessitent des transformations fiables, tracées et auditables. Sans pipelines automatisés, impossible de maintenir la qualité, la scalabilité et la vitesse de mise en production des modèles IA.
IA
IA responsable en entreprise, quelle gouvernance ?
0 commentaires
L’IA avance plus vite que la capacité des entreprises à la déployer à l’échelle. Multiplication de POCs et des cas d’usages, enthousiasme excessif, investissements massifs … mais la réalité n’a pas encore embrassé la fiction. Ce n’est pas une question de modèles ou d’algorithmes mais de cadre. Au-delà des expérimentations, tout l’enjeu est de garder le contrôle d’autant plus avec l’AI Act. Comment industrialiser des modèles privés ? Comment orchestrer des pipelines DataOps/LLMOps ? Comment monitorer des agents IA autonomes ? Comment sécuriser les données et se prémunir des risques IA ? Comment cadrer sans brimer l’innovation ?
Smartpoint, ESN spécialisée Data / IA, vous donne les clés pour déployer l’IA de manière responsable et conforme, à l’echelle.
Pourquoi l’industrialisation de l’IA en entreprise n’est pas encore au rendez-vous ?
88 % des POCs IA échouent à passer en production (…) En moyenne, sur 33 POCs IA lancés par une entreprise, seuls 4 passent en production. » source CIO
Clairement, l’IA est à l’ordre du jour de tous les comités de direction ! Certains projets connaissent même de l’ « IA washing » pour débloquer plus facilement des budgets. Mais dans les faits, l’écrasante majorité des projets IA ne part pas en production. On est loin d’aborder le sujet du ROI… Aujourd’hui, le problème n’est pas de développer le bon modèle. Il doit fonctionner dans la durée en exploitant des données fiables et de confiance. Il doit être sécurisé, traçable, gouverné et évidemment conforme avec toutes les exigences règlementaires en vigueur.
1. l’infrastructure IA, le talon d’Achille
Sans une architecture data moderne, unifiée et observable ; les LLMs privés et les agents IA ne peuvent pas fonctionner.
Luc Doladille, Directeur Conseil, Smartpoint
On n’en parle pas suffisamment mais sans architecture data moderne bien dimensionnée, unifiée et observable, c’est impossible de mettre en œuvre des LLMs privés et des agents IA métier qui nécessitent un fonctionnement en continu. Et cela demande aussi de composer avec des plateformes data héritées (systèmes legacy et dettes techniques) et des environnements cloud hybrides.
Pour passer à l’échelle, il faut bien souvent moderniser l’architecture data et concevoir des pipelines solides c’est-à-dire automatisés, monitorés et traçables.
2. l’importance des LLMOps
L’IA n’est pas un projet Data classique qui se contentait de batch nocturnes !
L’IA nécessite un monitoing continu et temps réel pour anticiper les principaux risques que sont l’exposition de données sensibles, les biais, les dérives et autres hallucinations. Et c’est encore plus critique avec les modèles génératifs qui évoluent en fonctions des interactions avec les utilisateurs.
C’est là que les LLMOps interviennent, ils sont les garants de la performance, de la sécurité et du comportement des modèles pendant tout leur cycle de vie : versionning, traçabilité, auditabilité, boucles de feedback, correction des dérives et amélioration des prompts. Un modèle statique, c’est un modèle déjà dépassé.
Chez Smartpoint, nos LLMOps utilisent des plateformes dédiées pour détecter les anomalies en temps réel (Weights & Biases, MLflow,EvidentlyAI) mais ils s’appuient aussi sur des mécanismes de validation humaine et la formation continue des équipes pour les sensibiliser à la gestion des risques.
Pour exemple, dans le cas d’un chatbot métier, sans LLMOps, une dérive dans les réponses, comme une hallucination sur un prix ou une réglementation, peut passer inaperçue alors que l’impact en terme de perte de confiance client est direct. Avec un monitoring temps réel via EvidentlyAI, l’équipe est alertée dès les premiers signes de déviation. Cela permet de corriger immédiatement les prompts ou le modèle.
La gouvernance IA, ce n’est pas une gouvernance des données classique. Elle nécessite une supervision en continue et des contrôles particulièrement rigoureux car les risques sont de taille. Il faut déjà définir les règles d’usages métiers et de conformité :
Accessibles : Diffusés sous forme de charte ou de guide pratique (Pas de plagiat, respect des droits d’auteur, transparence sur les sources utilisées).
Opérationnels : Intégrés dans les processus métiers (validation des prompts par un comité éthique avant déploiement).
Concrets : Illustrés par des cas d’usage autorisés ou ceux interdits (par exemple, les agents IA ne peuvent pas générer de contrats sans validation humaine, pas d’utilisation de données sensibles sans consentement explicite).
Par ailleurs, tous les projets IA ne comportent pas les mêmes risques. Nous recommandons, comme nos pairs ESN spécialisées en Data et IA, de mettre en place une matrice de scoring pour les catégoriser. Pour cela, il existe des frameworks comme le NIST AI Risk Management Framework qui tend à s’imposer comme référence internationale ou ISO/IEC 42001. Il est nécessaire également de mettre en place un comité de gouvernance IA qui rassemble juriste, DPO, data scientists et représentants métiers pour valider les projets en fonction de leur score de criticité.
Risque élevé : Modèles impactant la santé, les ressources humaines ou la conformité réglementaire
Risque modéré : Modèles métiers avec un impact indirect comme les chatbots clients ou les outils d’analyse de données.
Risque faible : Projets expérimentaux ou internes
Pour mettre en place une gouvernance IA efficace, nous recommandons chez Smartpoint d’automatiser les contrôles avec un monitoring temps réel avec des outils comme MLFlow pour les prompts ou EvidentlyAI pour détecter les biais.
Il est nécessaire également de définir des KPI et de les suivre comme par exemple le taux de détection des biais, le nombre d’audits passés et réussis ou encore le temps moyen de correction. Il faut également tester et retester pour d’assurer de la résilience des modèles.
En revanche, ce qui ne change pas, c’est l’incarnation de la gouvernance par les équipes et cela est encore plus vrai dans le cas de l’IA où on apprend en marchant. Les équipes doivent être sensibilisées aux bonnes pratiques et aux risques. Communiquer de manière transparente est également nécessaire sur les usages que l’on fait de l’IA … d’autant plus que les salariés sont globalement très inquiets quant à la pérennité de leurs postes.
Un exemple inspirant
Après les licenciements massifs annoncés chez Amazon en octobre 2025 (liés à l’automatisation), plusieurs entreprises ont communiqué sur leur approche humain-centrique de l’IA, mettant en avant la requalification des équipes plutôt que leur remplacement. Résultat ? Une image employeur renforcée et une meilleure adoption des outils IA en interne.
Les risques de non-conformité : RGPD, Data Act et AI Act
L’IA est encadrée par des réglementations strictes en Europe. Vous êtes tenus de les respecter sous peine de sanctions financières lourdes, d’atteinte à votre réputation mais aussi le risque d’interdiction d’exploitation.
RGPD
Toute IA utilisant des données personnelles (chatbots, outils RH, recommandations) doit respecter :
Minimisation des données (ne collecter que l’essentiel).
Transparence (informer les utilisateurs).
Droit à l’oubli (suppression des données sur demande).
Risque : Amendes jusqu’à 4 % du chiffre d’affaires mondial (ex. : 746 M€ pour Amazon en 2021).
Data Act (2023)
Il vise à garantir l’accès aux données et l’interopérabilité :
Les utilisateurs doivent pouvoir récupérer leurs données (ex. : historiques de chatbot).
Les plateformes IA doivent permettre la migration des données vers d’autres services.
Interdiction des pratiques déloyales (verrouillage des données par un fournisseur cloud par exemple).
Risque : Sanctions jusqu’à 2 % du chiffre d’affaires mondial.
AI Act (2025)
L’objectif est classer les IA selon leur niveau de risque et de prendre des mesures en fonction :
Risque inacceptable (ex. : notation sociale) → Interdits (amende : 35 M€ ou 7 % du CA).
Risque limité (ex. : chatbots) → Information des utilisateurs.
Risque : Amendes jusqu’à 35 M€ ou 7 % du CA pour non-conformité.
Et si on adoptait directement des modèles IA souverains ?
L’IA souveraine devient un vrai sujet chez nos clients et cela a également un enjeu stratégique face aux solutions américaines hégémoniques (américaine et désormais aussi chinoise). Et des alternatives européennes existent pour garantir une meilleure maîtrise des données.
Pourquoi choisir des modèles IA souverains ?
Les modèles IA souverains respectent les exigences européennes (RGPD, AI Act) et ils permettent d’éviter les risques liés aux transferts de données hors UE. Par exemple, Mistral AI assure que les données d’entraînement et d’usage restent protégées et gouvernées dans l’espace européen. À lire sur ce sujet « Mistral AI, nouveau champion européen de l’intelligence artificielle« .
Mistral AI est signataire du Code de Bonnes Pratiques pour l’IA à usage général, adopté en août 2025, et ses modèles sont nativement alignés avec le RGPD et le AI Act européen. Mistral veut reconquérir une souveraineté numérique perdue. Contrairement aux modèles américains, souvent adaptés après coup aux exigences locales, Mistral a pris le pari de la conformité dès la conception. […] En février 2025, Mistral annonce la construction de son propre datacenter, en Essonne, sur plusieurs milliers de mètres carrés. […] Une réponse claire aux hyperscalers américains. Déjà, des acteurs comme Orange, BNP Paribas, la SNCF, Veolia, Thales ou Schneider Electric ont signé.
Avec un LLM souverain, vos données restent sur le territoire européen. Cela limite les risques de fuites, de cyberattaques ou encore le risque (lock-in) de verrouillage par un fournisseur tiers qui refuserait de restituer vos données ou qui change sa politique de gestion de la confidentialité.
Les modèles européens comme Mistral AI ou Aleph Alpha ont aujourd’hui un niveau de performance comparable aux acteurs américains et ils ont surtout un intérêt de taille : ils sont optimisés pour les usages européens en termes de langue, de conformité et de souveraineté.
Ceci étant dit, l’écosystème IA porté par OpenAI, Anthropic et les hyperscalers a encore une véritable longueur d’avance (bibliothèque et outils, pack développeur, etc.) …
Choisir des modèles souverains peut demander dans les faits plus d’intégration technique (pipelines DataOps/LlmOps, développement de connecteurs, orchestration, observabilité) mais nous pensons chez Smartpoint, ESN spécialisée en Data / IA, que l’investissement initial le vaut. La liberté n’a pas de prix !. En revanche, ceux de non-conformité règlementaire en ont un !
Mistral AI (France)
Modèles open-source et privés adaptés aux environnements d’entreprise
Hébergement en Europe, compatible RGPD et AI Act
Déploiement flexible : on-premise, cloud souverain (OVH/Outscale) ou cloud privé
Modèles optimisés pour les chatbots métier, la recherche documentaire, l’analyse de données sensibles et les agents IA privés
Aleph Alpha (Allemagne) :
Modèles conçus pour l’explicabilité (XAI), indispensable en environnement hautement réglementé (Santé, finance)
Gouvernance avancée, gestion du risque, réduction des biais
Intégration facilitée avec les architectures data existantes
Alignement natif avec les exigences AI Act
Comment Smartpoint accompagne ses clients
Chez Smartpoint, ESN française spécialisée Data & IA, nous accompagnons les entreprises de la conception à la mise en production de l’IA. Notre approche repose sur la modernisation du SI, l’engineering avancé (DataOps / LLMOps / Platform Engineering) et une gouvernance IA responsable.
Concrètement, nos architectes, nos experts et nos consultants s’attachent à :
construire des architectures data et IA prêtes pour l’échelle, performantes et observables,
déployer des pipelines Data/LLMOps sécurisés et traçables,
intégrer des modèles souverains ou hybrides selon les besoins métier,
mettre en place un cadre de gouvernance IA conforme « by design » aux règlementations
industrialiser des cas d’usage concrets, mesurables et pérennes (assistants métiers, copilotes développeurs, agents privés).
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
En résumé
Pourquoi les projets d’IA échouent en entreprise ?
Principalement en raison d’un SI non adapté, de données non gouvernées, d’un manque de LLMOps, d’un cadre IA insuffisant et d’une maturité organisationnelle limitée.
Comment mettre en production des modèles IA ?
En modernisant l’architecture data, en déployant des pipelines LLMOps/observabilité, en cadrant l’usage, en assurant la conformité RGPD/AI Act et en industrialisant les workflows IA.
Pourquoi choisir des modèles IA souverains ?
Pour protéger les données, éviter le Cloud Act, maîtriser les coûts/risques et garantir conformité AI Act et souveraineté numérique.
Outils Data
Data Mesh & l’IA : Zoom sur Genie de Databricks pour accélérer l’innovation data driven
0 commentaires
Avec le développement de l’IA, le Data Mesh s’impose comme un facilitateur pour l’entraînement de modèles et l’ingénierie de features. Analyse de Smartpoint, ESN spécialisée en data et IA, sur comment cette architecture décentralisée, en utilisant Genie de Databricks, révolutionne la gestion des données et booste l’adoption de l’IA. Nous verrons aussi l’intégration Genie Databricks dans le Data Mesh.
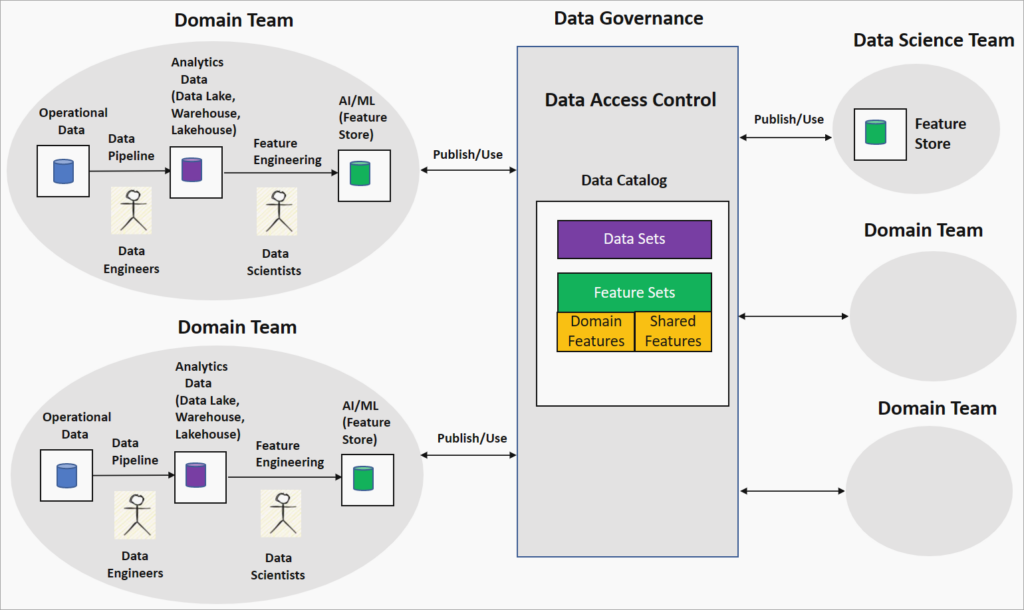
Qu’est-ce que le Data Mesh ?
Le Data Mesh est une approche organisationnelle et architecturale qui repense la gestion des données à grande échelle pour en tirer une valeur maximale. Contrairement aux architectures Data traditionnelles basées sur des data lakes ou data warehouses, souvent centralisées et générateurs des fameux silos, le Data Mesh répartit la propriété et la gestion des données entre différents domaines métier (ventes, finance, marketing, etc.). Cette décentralisation permet aux équipes de gérer leurs données de manière autonome tout en respectant des règles de gouvernance centralisées pour garantir interopérabilité, sécurité et cohérence sémantique.
Propriété par domaine : Chaque domaine métier prend en charge l’intégralité du cycle de vie de ses données, favorisant une expertise métier approfondie et une meilleure agilité.
Gouvernance fédérée : Une gouvernance centralisée, appuyée par des outils comme les data catalogs, assure le respect des normes organisationnelles et réglementaires tout en laissant les domaines opérer de manière autonome. À lire :Gouvernance fédérée et architectures distribuées
Data as a product : Les données sont traitées comme des produits, avec des principes de gestion pour les rendre « découvrables », fiables, auto-descriptifs et interopérables ; afin de maximiser leur valeur
Plateforme en libre-service : Une infrastructure automatisée permet aux équipes de créer et maintenir leurs data products sans dépendance excessive aux équipes IT centrales.
Ces principes cassent les silos et accélèrent la livraison de valeur métier, rendant le Data Mesh particulièrement adapté à l’ère de l’IA.
Le Data Mesh et IA
Avec la montée en puissance de l’IA, le Data Mesh agit comme un catalyseur : il facilite l’entraînement des modèles (deep-learning, machine learning) et l’optimisation des features. En décentralisant la gestion des données, il permet aux domaines de développer leurs propres modèles IA/ML en s’appuyant sur des data products spécifiques à leur métier. Par exemple, dans un environnement Azure, le Data Mesh facilite la transition d’un data lake centralisé vers des domaines décentralisés, optimisant l’ingénierie des features pour des cas d’usage métier précis.
Alors que l’intelligence artificielle (IA), le machine learning et l’IA générative redéfinissent les stratégies data-driven, le Data Mesh s’impose comme une architecture des données incontournable. En brisant les silos des data lakes traditionnels, cette approche décentralisée favorise une gouvernance fédérée, une propriété par domaine et des data products interopérables, créant un socle robuste pour l’IA à grande échelle.
Fluidité des échanges de données : Les domaines partagent des données cohérentes et bien structurées, éliminant les incohérences qui ralentissent les modèles IA.
Fondation pour l’IA générative : Le Data Mesh, combiné à l’IA générative, forme un tandem dynamique pour gérer les données à grande échelle, rendant les données accessibles et exploitables pour des insights rapides. Comme le souligne une analyse récente, cette synergie accélère la production de valeur dans des environnements complexes. À lire sur ce sujet : Data Mesh and Generative AI: The Dynamic Duo for Data Management at Scale
Démocratisation de l’IA : Selon notre expérience chez Smartpoint auprès des entreprises, très peu déploient l’IA générative à grande échelle. Selon nos architectes Data, le Data Mesh dynamise son adoption en rendant les données accessibles aux équipes non techniques.
Genie de Databricks 2025 : Solution innovante IA pour data mesh
Genie de Databricks est une interface innovante d’AI/BI qui permet aux utilisateurs métier d’interagir avec leurs données via le langage naturel, générant des insights et des data visualisations instantanés. Contrairement aux outils BI classiques, Genie agit comme un analyste IA évolutif, capable d’apprendre des retours utilisateurs, d’affiner ses réponses et d’intégrer des instructions expertes pour des analyses précises. Et Genie respecte l’EU AI Act via Unity Catalog pour audits et traçabilité !
Lancé en juin 2025, Genie s’appuie sur la Data Intelligence Platform de Databricks et Unity Catalog pour une gouvernance intégrée. Ses principales fonctionnalités incluent :
Questions-réponses en langage naturel : Posez des questions comme « Pourquoi les ventes ont-elles baissé la semaine dernière ? » pour obtenir des réponses sous forme textuelle, tabulaire ou visuelle.
Raisonnement agentique : Genie résout les ambiguïtés et s’améliore grâce aux interactions.
Instructions expertes : Intégrez des requêtes SQL, des définitions de métriques ou des exemples pour des résultats précis.
Suivi et optimisation : Surveillez l’usage, évaluez la précision et intégrez des retours pour une amélioration continue.
Intégrations : Importation de fichiers (Excel, CSV), API pour des outils comme Slack, et mode Deep Research (en preview) pour des analyses complexes.
Intégration de Genie dans une architecture Data Mesh
Genie s’intègre parfaitement au Data Mesh en transformant les data products statiques en interfaces dynamiques et intelligentes. Sur Databricks, il agit comme un catalyseur en s’alignant sur les principes de propriété par domaine et de Data as a product.
Propriété par domaine : Chaque domaine configure ses propres Genie Spaces sur ses tables Unity Catalog, intégrant une logique métier spécifique (ex. : définitions d’année fiscale pour la finance). Ces espaces sont gérés par les équipes métier avec des instructions et des exemples pour une compréhension sémantique optimale.
Données comme « produit interactif » : Genie enrichit les data products avec des métadonnées (lignage, descriptions), garantissant des réponses fiables et traçables. Il transforme les tables Delta Lake en produits « découvrables » et auto-descriptifs, renforçant leur valeur métier.
Modèle Hub-and-Spoke ou harmonisé : Dans une architecture Data Mesh sur Databricks, les domaines opèrent dans des workspaces dédiés, avec un hub central pour la gouvernance. Genie peut être déployé par domaine (ex. : Genie Ventes, Genie Supply Chain) et orchestré via un Master Genie pour des analyses inter-domaines, formant un « Genie Mesh » multi-agent.
Exemple : Un domaine Marketing peut exposer un Genie Space pour ses données de campagnes publicitaires, tandis qu’un Master Genie agrège des insights cross-domaines pour des analyses globales, comme la performance globale des initiatives marketing et commerciales.
Avantages et limites
Avantages
Démocratisation : Accès en libre-service aux insights IA, réduisant la dépendance aux équipes data centrales.
Gouvernance renforcée : Intégration avec Unity Catalog pour une sécurité et un lignage fédérés.
Scalabilité : Prise en charge de grands volumes de données sans réplication, accélérant les décisions métier.
Innovation IA : Facilite l’entraînement et l’utilisation d’agents IA sur des données décentralisées.
Limites
Complexité initiale : Configurer les Genie Spaces nécessite une expertise en métadonnées et instructions métier.
Adoption : Former les utilisateurs métier à interagir avec l’IA peut représenter un défi.
Précision : Bien que Genie réduise les erreurs (hallucinations), des benchmarks réguliers sont nécessaires pour garantir la fiabilité.
Retail : Un Genie Supply Chain anticipe les ruptures de stock, intégré à un Master Genie pour corréler avec les données de ventes.
Santé : Premier Inc. utilise Genie pour des analyses rapides sans codage, améliorant la prise de décision.
Finance : Analyse des pipelines de ventes en langage naturel, comme chez HP ou 7-Eleven, pour des insights instantanés.
Alternatives à Genie : Solutions recommandées par Smartpoint
Chez Smartpoint, nous accompagnons nos clients dans le choix d’outils AI/BI adaptés à leur maturité data et leur architecture de données (comme le Data Mesh). Si Genie de Databricks est particulièrement adapté aux environnements Lakehouse ouverts, d’autres solutions offrent des complémentarités intéressantes pour une IA générative décentralisée. Voici deux alternatives intéressantes selon nos experts Data/IA dans une architecture data mesh :
Snowflake Cortex AI (via l’acquisition d’Applica)
Snowflake propose une plateforme unifiée pour la gestion des données et l’IA générative, particulièrement adaptée aux environnements multi-cloud. Grâce à l’acquisition d’Applica en septembre 2022, Snowflake a intégré Document AI, un modèle de langage multimodal (LLM) qui extrait des insights profonds de documents non structurés (PDF, images, etc.), les rendant exploitables pour des apps IA personnalisées. Idéal pour les domaines traitant de données hybrides (structurées/non structurées), avec une gouvernance fédérée via Snowflake Horizon Catalog. Recommandé pour les entreprises en transition vers l’IA scalable, sans migration lourde.
Intégré à l’écosystème Microsoft, Power BI Copilot transforme l’analyse BI en conversation naturelle, permettant aux utilisateurs métier de poser des questions en langage courant pour générer tableaux, visualisations et résumés automatisés. Il assiste aussi les développeurs dans la création de rapports narratifs et l’optimisation de modèles sémantiques via des suggestions IA. Parfait pour les organisations Azure-centric, avec une intégration fluide aux domaines décentralisés (via Fabric). Il démocratise l’IA en réduisant le besoin de codage, idéal pour une adoption rapide par les équipes non techniques.
Interface conversationnelle en langage naturel pour Q&R sur données (insights textuels, tabulaires, visuels). Raisonnement agentique, instructions expertes (SQL/métriques), surveillance des feedbacks. Focus sur l’analyse prédictive et l’IA générative intégrée (Mosaic AI). Idéal pour data scientists et analystes.
Suite AI pour services financiers/entreprises : extraction d’insights de documents non structurés (Document AI), agents de data science (nettoyage, feature engineering), Cortex Analyst pour requêtes SQL en NL. Intègre LLMs comme Claude 3.5 Sonnet. Fort sur l’analyse multimodale (images, PDF).
Assistant IA pour rapports BI : génération de visualisations, résumés et DAX via NL. Aide à la création de rapports narratifs et à l’exploration de datasets. Intègre Copilot Studio pour agents personnalisés. Plus orienté BI visuelle que pure analyse data.
Intégration Data Mesh
Excellente : Aligné sur les principes (propriété par domaine via Genie Spaces sur Unity Catalog). Supporte hubs-and-spoke pour gouvernance fédérée, lignage end-to-end et autonomie des domaines. Facilite les « Genie Mesh » multi-agents pour analyses cross-domaines.
Bonne : Horizon Catalog pour gouvernance unifiée (métadonnées, permissions RBAC). Intègre avec domaines décentralisés via Snowpark, mais plus centralisé. Adapté pour data products interopérables, avec focus sur silos brisés multi-cloud.
Moyenne : Intégration via Microsoft Fabric pour domaines Azure-centric. Supporte gouvernance fédérée (Purview), mais moins natif pour Data Mesh décentralisé. Bon pour équipes métier, mais nécessite plus de customisation pour inter-domaines.
Tarification
Inclus dans la plateforme Data Intelligence (pay-as-you-go sur DBUs, ~0,07-0,55 €/DBU selon cluster). Pas de surcoût pour Genie ; scalabilité élastique. Coûts variables selon usage (ex. : 1-5 €/heure pour clusters AI).
Inclus dans Snowflake (crédits par seconde de compute, ~2-5 €/crédit). Cortex Analyst gratuit pour usages basiques ; surcoût pour LLMs avancés (~0,01-0,10 €/1k tokens). Modèle prévisible, mais potentiellement élevé pour gros volumes.
Inclus dans Power BI Premium (~10-20 €/utilisateur/mois) ou Fabric (~0,36 €/capacité/heure). Surcoût pour Copilot Studio (~200 €/utilisateur/mois). Abordable pour PME, mais lié à l’écosystème Microsoft.
Conformité EU France AI Act / Data Act
Haute : Unity Catalog pour traçabilité et gouvernance (lignage, audits). Supporte AI Pact volontaire ; tests contre biais/hallucinations. Respecte Data Act via portabilité (Delta Lake open-source) et résidence EU. Intégration OneTrust pour mapping automatique aux normes (NIST, ISO 42001).
Haute : Horizon pour sécurité/compliance (RBAC, pas d’entraînement sur données clients). Cortex pour Finserv respecte régulations sectorielles ; aligné AI Act (risques inacceptables prohibés). Data Act via interopérabilité multi-cloud et portabilité (Iceberg). Focus sur privacy-by-design.
Très haute : Engagement Microsoft pour conformité totale (principes : fairness, privacy, accountability). Outils comme Purview pour audits RGPD/AI Act ; monitoring continu des biais. Data Act via portabilité Fabric et résidence Azure EU. Exemptions open-source pour bas risques.
Forces pour le marché français
Flexibilité pour ESN comme Smartpoint : idéal pour implémentations custom Data Mesh/IA en multi-cloud (AWS/Azure/GCP). Scalable pour startups tech parisiennes.
Simplicité pour secteurs réglementés (banque, santé) : souveraineté data multi-cloud, adapté aux contraintes CNIL. Bon pour portabilité Data Act.
Intégration native Azure (régions FR) : parfait pour entreprises Microsoft-centric (SME/GE). Facilite adoption rapide avec formation RGPD intégrée.
Limites
Courbe d’apprentissage pour non-data engineers ; coûts variables sur gros clusters.
Moins mature pour ML avancé (dépend d’intégrations tierces).
Limité à écosystème Microsoft ; moins flexible pour Data Mesh pur.
Ces solutions, comme Genie, s’alignent sur les principes du Data Mesh en favorisant l’autonomie des domaines et l’interopérabilité pour une architecture data moderne. Chez Smartpoint, nous évaluons ensemble la meilleure stack Data dans votre cas spécifique en conformité aux réglementations EU. Un POC gratuit pour tester l’intégration ? Contactez-nous.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Vos questions sur le Data Mesh et IA Générative
Qu’est-ce que le Data Mesh ?
Le Data Mesh est une architecture de données décentralisée qui répartit la propriété des données entre les domaines métier. Contrairement aux data lakes centralisés, il favorise l’autonomie des équipes via des data products interopérables, soutenus par une gouvernance fédérée. En France, il accélère l’innovation data-driven en cassant les silos, tout en respectant l’AI Act et le Data Act pour la traçabilité et la portabilité des données. Smartpoint accompagne les entreprises dans leur transition vers cette architecture scalable.
Qu’est-ce qu’une gouvernance fédérée ?
La gouvernance fédérée conjugue autonomie des domaines et normes centralisées. Dans un Data Mesh, chaque domaine gère ses données (qualité, accès) mais un data catalog (ex. : Unity Catalog) harmonise sécurité, lignage et conformité (RGPD, Data Act). Cela garantit l’intéropérabilité et réduit les risques réglementaires essentiels en France soumis à l’ AI Act. Smartpoint déploie des solutions comme Databricks ou Snowflake pour une gouvernance robuste avec audits CNIL-ready.
Comment intégrer Genie Databricks dans un Data Mesh ?
Genie de Databricks transforme les data products en interfaces IA conversationnelles. Chaque domaine configure des Genie Spaces sur Unity Catalog, intégrant une logique métier (ex. : métriques financières). Un Master Genie orchestre les analyses inter-domaines, formant un « Genie Mesh ». En France, cette intégration respecte l’EU AI Act (traçabilité, audits) et accélère les insights pour les PME. Smartpoint propose des POC pour tester Genie dans une architecture Data Mesh.
Quelles solutions IA générative en France ?
En 2025, plusieurs solutions IA générative s’intègrent au Data Mesh pour les entreprises françaises : Genie de Databricks : Interface AI/BI pour analyses en langage naturel, conforme EU AI Act via Unity Catalog. Idéal pour multi-cloud. Snowflake Cortex AI : Performant dans l’extraction de données non structurées (Document AI), avec conformité Data Act via Horizon Catalog. Microsoft Power BI Copilot : Génère rapports BI via Azure, avec audits RGPD via Purview. Parfait pour entreprises Microsoft-centric. Smartpoint recommande des solutions avec résidence EU (ex. : régions Azure FR) pour répondre aux exigences CNIL.
Réussir sa gouvernance des données à l’ère du cloud distribué
0 commentaires
Les architectures décisionnelles traditionnelles (SID legacy) ont indéniablement atteint leurs limites. Les équipes data doivent désormais orchestrer des flux massifs, issus de sources toujours plus nombreuses, dans des environnements hybrides ou multi-cloud tout en garantissant des temps de traitement toujours plus courts.
À cette complexité technique s’ajoute une pression réglementaire croissante : au-delà du RGPD, les textes européens comme le Data Act et l’AI Act imposent une traçabilité complète des données, de leur origine à leur usage en passant par chaque étape de transformation.
Dans ce contexte, la gouvernance des données ne peut plus être une surcouche. Elle doit devenir un composant central de l’architecture data moderne : intégrée, automatisée, et alignée sur les usages métiers comme sur les exigences de conformité.
Comment réussir cette bascule vers une gouvernance data fédérée, adaptée aux environnements cloud distribués et aux impératifs de souveraineté ? Smartpoint, ESN experte en IA et en ingénierie de la donnée, vous livre ici sa lecture des fondations d’une gouvernance data moderne à l’ère du multi-cloud.
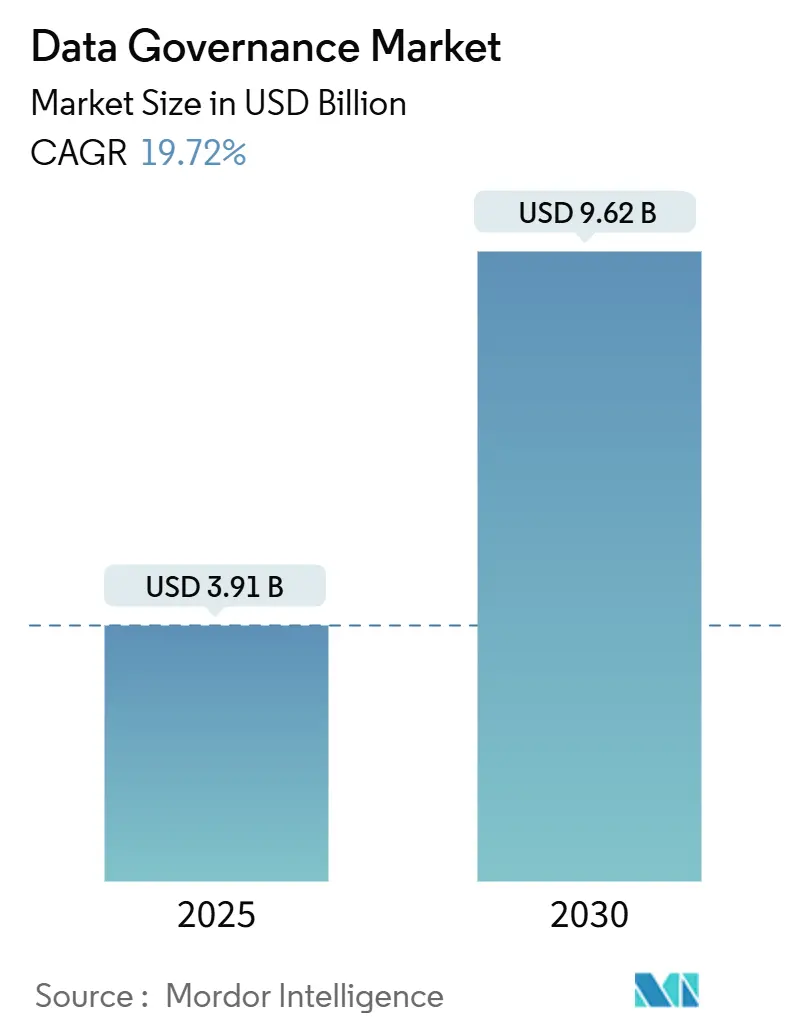
Selon Mordor Intelligence, le marché de la gouvernance des données va plus que doubler entre 2025 et 2030. Ce chiffre illustre une réalité : la gouvernance data n’est plus une fonction de contrôle, mais un levier structurant de performance et de conformité dans des environnements multi-cloud, découplés et de plus en plus régulés.
Du modèle centralisé à l’architecture fédérée
Historiquement, la gouvernance des données reposait sur un modèle centralisé avec un SI décisionnel unique piloté par l’IT, où les données étaient collectées, transformées, contrôlées et diffusées depuis un data warehouse ou un data lake administré de manière verticale.
Ce modèle a clairement des avantages comme l’unification des règles, la maîtrise des flux et une supervision centralisée… mais il n’est plus applicable :
Les données ne sont plus stockées au même endroit, ni produites par les mêmes équipes
Alors que la culture data infuse les métiers, les besoins fusent avec une exigence forte de time-to-data
La gouvernance ne peut plus suivre car elle reste trop en amont, trop IT-centrix, trop lente.
Pour les architectes data comme pour les responsables BI, adopter une architecture data distribuée pilotée par les domaines mais orchestrée à l’échelle de l’organisation s’impose.
Luc Doladille, Directeur Conseil, Smartpoint
Dans ce modèle inspiré des principes du Data Mesh, chaque domaine métier devient producteur responsable de ses propres jeux de données avec des engagements pris sur la qualité, la documentation, les SLA et la traçabilité.
La gouvernance data n’a pas disparu, elle change de forme. Elle devient fédérée, c’est-à-dire partagée, encadrée par des standards, supportée par des outils transverses (data catalog, politiques de sécurité, plateforme self-service) maiss exécutée dans les domaines producteurs, au plus près des pipelines et des usage
2. Les fondations d’une gouvernance data moderne à l’ère du multi-cloud
Une gouvernance des données efficace dans un environnement distribué ne repose plus sur des contrôles centralisés mais sur un ensemble de composants coordonnés, capables de garantir à la fois agilité, conformité et qualité de la donnée. Dans un écosystème multi-cloud, hybride où les données sont produites par des domaines métiers autonomes, ces fondations sont à la fois techniques, organisationnelles et opérationnelles.
2.1. Des rôles bien définis dans un cadre distribué
Data Owners, Domain Owners, Data Stewards : chacun doit connaître son périmètre, ses responsabilités et ses obligations vis-à-vis de la donnée.
La gouvernance n’est plus portée par une équipe centrale unique mais répartie selon une logique domain-driven.
Les équipes métiers sont responsables de la qualité, de la documentation et de la traçabilité de leurs “data products”.
Smartpoint recommande la formalisation claire des rôles, appuyée par des chartes de gouvernance et des cadres de responsabilisation contractuels (SLA, politiques de qualité, règles de sécurité).
2.2. Un socle d’outils transverse pour aligner et orchestrer
Dans un environnement distribué, la gouvernance ne peut malheureusement pas s’appuyer sur un outil unique ni sur une solution centralisée … ce qui complique le tout. Il faut centraliser la connaissance sur les données sans centraliser les données elles-mêmes !
Orchestrer une gouvernance data dans une architecture distribuée demande donc de composer une stack outillée en approche best-of-breed ; c’est à dire en sélectionnant les meilleures briques technologiques selon les besoins spécifiques : catalogage, traçabilité, gestion des accès, documentation, qualité, monitoring, SLA…
Les briques de la gouvernance des données à assembler :
Data Catalogs pour référencer et exposer les données disponibles (Collibra, Atlan, Azure Purview, Informatica Axon…)
Data Lineage pour tracer les transformations, du sourcing à la consommation (ex. : Informatica, DataHub, OpenMetadata)
Portails de documentation et glossaires métiers pour formaliser le patrimoine data partagé
Mécanismes d’accès sécurisés selon les les rôles, intégrant les règles de souveraineté et de confidentialité
SLA automatisés / Quality contracts via des solutions comme dbt, Soda, Monte Carlo (…) pour monitorer la qualité, la fraîcheur ou la disponibilité des data products
Une approche best-of-breed incontournable
Aucun outil unique ne permet aujourd’hui de couvrir l’ensemble des besoins d’une gouvernance data moderne dans un modèle Data Mesh ou multi-cloud. Il est nécessaire d’assembler des composants spécialisés tout en assurant leur interopérabilité et leur intégration dans l’architecture data existante.
L’enjeu n’est pas d’acheter un outil de plus mais de construire un socle de data governance cohérent et aligné avec la réalité technique et organisationnelle de l’entreprise.
2.3. Une gouvernance alignée sur les exigences de conformité et de souveraineté
Le RGPD reste un cadre structurant pour la gouvernance des données en Europe mais il n’est plus le seul à imposer des exigences fortes. En 2025, des textes comme le Data Act ou l’AI Act récemment adoptés par l’Union européenne, introduisent de nouvelles obligations en matière de transparence, documentation, accessibilité et auditabilité des données et des traitements. À cela s’ajoutent des contraintes sectorielles spécifiques : HDS dans la santé, PCI-DSS dans la finance, ISO/IEC 27001 dans les environnements sensibles qui exigent une maîtrise rigoureuse du cycle de vie de la donnée.
Ces exigences règlementaires impliquent concrètement au niveau de la gouvernance des données :
Gérer la localisation géographique des données (cloud souverain, hébergement certifié, interdiction de transferts non encadrés)
Assurer une traçabilité complète des transformations de données y compris dans les chaînes automatisées (pipelines, IA, ETL/ELT)
Documenter les bases légales de traitement, les consentements et les finalités de chaque usage
Piloter les droits d’usage (lecture, écriture, partage, export) en fonction des rôles, des statuts et des contextes réglementaires.
Dans un modèle distribué de type Data Mesh, où chaque domaine est responsable de ses données, ces exigences ne peuvent pas être imposées depuis une fonction centrale. La conformité doit être intégrée nativement dans les flux métiers, à travers des mécanismes automatiques de traçabilité, de validation, de gouvernance des accès et de documentation des traitements.
La gouvernance ne se limite plus à garantir la qualité des données : elle devient une condition de conformité, de sécurité juridique et de souveraineté numérique. Dans les environnements cloud distribués, cette gouvernance doit être pensée “by design” et non vérifiée a posteriori sous forme d’audit ou de cartographie figée.
2.4.Une gouvernance pilotée par la donnée et non par les processus
La data gouvernance moderne ne se limite pas à poser des règles ou à publier un référentiel : elle doit être mesurée, suivie, pilotée comme toute fonction stratégique du SI. Pour créer de la confiance autour de la donnée, il faut démontrer sa qualité, sa traçabilité, sa disponibilité mais aussi sa valeur d’usage.
Les indicateurs clés de la gouvernance des données
Qualité de données (DQM) : taux de complétude, fraîcheur, cohérence inter-systèmes, fréquence d’anomalies remontées…
Disponibilité et performance : respect des SLA de mise à disposition des data products, temps d’accès, volumétrie servie…
Usage : taux de réutilisation, nombre de vues / extractions, requêtes actives sur un domaine ou une table…
Documentation / traçabilité : pourcentage de champs documentés, sources renseignées, parcours de transformation lisible…
Conformité : présence du fondement légal de traitement, gestion des consentements, taux d’accès non conforme détecté…
Ces métriques doivent être exposées, analysées et partagées dans l’organisation ; non pas pour sanctionner mais pour responsabiliser les producteurs et valoriser les bonnes pratiques. Sans mesure, la gouvernance reste déclarative. Avec des indicateurs pertinents et partagés, elle devient un levier d’amélioration continue et un facteur de confiance dans les architectures data modernes.
Elles permettent aussi :
Aux DSI de prioriser les efforts (outillage, industrialisation, acculturation) sur les domaines critiques
Aux métiers de visualiser la valeur créée par leur production de données
À la gouvernance d’évoluer vers un cadre de performance … et non de contrôle
Mettre en œuvre une gouvernance data fédérée ? Entre vision cible et réalité terrain
Retour d’expérience Smartpoint
Si le modèle de gouvernance fédérée, inspiré du Data Mesh, semble être un impondérable ; sa mise en œuvre concrète n’est pas simple dans de nombreuses entreprises que nous avons accompagné.
Voici les freins les plus fréquemment rencontrés sur le terrain par nos architectes data et consultants data governance.
1. Des métiers encore peu préparés à endosser le rôle de data owner
Culture encore très “consommatrice” de la donnée, peu tournée vers la production ou la responsabilisation.
Manque de temps, de formation et d’indicateurs pour assurer le suivi qualité, la traçabilité ou les SLA sur leurs jeux de données.
Résultat : les rôles clés (data owner, domain owner) existent dans l’organigramme mais sont peu incarnés dans les faits.
2. Des DSI « en transit » vers un rôle de facilitateur
Passer d’un modèle de gouvernance centralisée à un modèle “platform as a service” demande une transformation en profondeur de l’organisation IT.
Cette évolution est souvent freinée par des réflexes pavloviens, des contraintes de sécurité ou une absence de cadre clair de fédération.
3. Des outils puissants mais parfois déconnectés des usages
L’adoption d’outils de gouvernance (Collibra, Informatica, Atlan…) est parfois perçue comme une surcouche lourde et déconnectée du quotidien.
À l’inverse, des stacks plus flexibles (dbt, DataHub,…) nécessitent des compétences pointues et une vraie capacité à industrialiser les process.
4. Une gouvernance qui reste trop souvent théorique
Le risque ? Une illusion de conformité sans impact réel sur la fiabilité ou la réutilisabilité des données.
Sans réels indicateurs de pilotage (qualité, usage, documentation), sans sponsoring fort, la gouvernance se résume trop souvent des documents figés ou des catalogues non maintenus.
3. Gouvernance data distribuée : construire une trajectoire réaliste et pilotable
Le passage d’une gouvernance data centralisée à un modèle fédéré, inspiré du Data Mesh, s’impose face à la complexité des architectures data modernes, au foisonnement des sources de données et à la pression réglementaire croissante. Mais cette transition doit s’appuyer sur une trajectoire pragmatique pour réussir, adaptée à la maturité réelle de l’organisation, à ses contraintes SI, et à la capacité des équipes, IT comme métiers, à s’approprier les nouveaux rôles (et les outils !).
Une gouvernance des données efficace dans un environnement cloud distribué n’est ni totalement centralisée, ni totalement décentralisée. Elle repose sur un équilibre parfois fragile entre autonomie locale et cohérence globale, orchestré par l’architecture data et porté par une culture de la responsabilité partagée.
Luc Doladille, Directeur Conseil, Smartpoint
Ce que recommande Smartpoint
En tant qu’ESN spécialisée en IA, Data et gouvernance, Smartpoint accompagne les DSI dans la construction de modèles de gouvernance distribuée réalistes, outillés, mesurables et surtout pérennes dans le temps. Notre approche repose sur trois principes :
La gouvernance n’est pas un outil, mais une architecture organisationnelle à faire évoluer avec la donnée.
Les métiers doivent être engagés sans être livrés à eux-mêmes via des cadres clairs et des indicateurs actionnables.
Le choix des outils doit rester agnostique centré sur les besoins de traitement, de pilotage et de conformité … et non dicté par le buzz ou par les éditeurs.
Vous souhaitez réaliser un diagnostic de maturité de votre gouvernance actuelle ? Vous voulez définir une trajectoire adaptée à votre SI et vos enjeux métiers ? Vous cherchez à identifier et à intégrer les outils les plus pertinents dans votre stack existante ?
Contactez nos experts Data & IA pour cadrer, tester et mettre en œuvre une gouvernance fédérée sur mesure, à votre rythme … mais dans la bonne direction.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Tout savoir – Gouvernance des données cloud
Qu’est-ce qu’une gouvernance data fédérée ?
Une gouvernance data fédérée repose sur une répartition des responsabilités entre les différents domaines de l’organisation. Chaque équipe métier est responsable de ses propres données (data ownership), tout en respectant des règles communes, partagées et outillées au niveau transverse (catalogue, sécurité, qualité…).
Le Data Mesh est-il une architecture ou un modèle de gouvernance ?
Le Data Mesh est avant tout un modèle d’organisation et de gouvernance de la donnée, fondé sur quatre principes clés : responsabilité des domaines, “data as a product”, plateforme en libre-service, et gouvernance fédérée. Il n’est pas une architecture technique, mais il impacte directement l’architecture data.
Quels outils sont nécessaires pour une gouvernance data distribuée ?
Il n’existe pas d’outil unique. Il faut composer une stack en mode best-of-breed :
Data catalogs (Collibra, Atlan…)
Lineage & documentation (DataHub, OpenMetadata…)
Qualité et SLA (dbt, Soda…)
Portails d’accès et politiques de sécurité
Ces briques doivent être intégrées à l’architecture data existante.
Comment intégrer la conformité RGPD, Data Act et AI Act dans la gouvernance ?
La conformité doit être intégrée nativement dans les processus de traitement des données. Cela implique :
La traçabilité des transformations
La gestion des consentements
Le contrôle des droits d’usage
La localisation des données
Une gouvernance moderne doit être pensée “by design”, pas vérifiée a posteriori.
Pourquoi la gouvernance des données est-elle un enjeu stratégique pour les DSI ?
Parce qu’elle conditionne :
La fiabilité des traitements analytiques et IA
Le respect des réglementations
La qualité des décisions métier
Et la valeur des plateformes data
Dans un SI moderne, la gouvernance est un levier de performance autant que de conformité.
Autres articles architectures data et gouvernance des données qui pourraient vous intéresser ?
DataOps : industrialisez vos pipelines data pour une BI agile et fiable
0 commentaires
Les pipelines de données sont de plus en plus complexes à concevoir et à maintenir : infrastructures hybrides, environnements multi-cloud, explosion des volumes, multiplication des outils BI, ETL, ELT, intégration de l’IA… Les équipes data BI sont confrontées à des flux hétérogènes, instables et difficiles à fiabiliser à l’échelle.
Aujourd’hui, les DSI ne peuvent plus se reposer sur des workflows artisanaux ou des scripts dispersés. Pour garantir la qualité, la scalabilité et l’automatisation des traitements, il est nécessaire d’adopter une approche plus industrielle. C’est là qu’intervient DataOps comme cadre de référence pour orchestrer les pipelines analytiques de manière agile, fiable et continue.
Qu’est-ce que le DataOps ?
Le DataOps (Data Operations) est un ensemble de pratiques inspirées du DevOps, mais appliquées aux pipelines de données. Son objectif principal est de fluidifier, fiabiliser et industrialiser le cycle de vie des données, de l’ingestion à la restitution BI, en passant par la transformation, le stockage et la gouvernance.
Face à des environnements data de plus en plus complexes (cloud, multi-outils, multi-sources), le DataOps apporte une réponse structurée pour automatiser les processus, améliorer la qualité des données, accélérer les déploiements analytiques et permettre la maintenabilité. le DataOps vise à faire du pipeline data un actif industriel, robuste et agile, pour permettre aux entreprises d’exploiter au mieux leurs données en production.
Objectifs du DataOps ?
Automatiser les workflows de traitement et de livraison des données
Garantir la fiabilité et la traçabilité des données utilisées par les outils BI
Monitorer et superviser en temps réel les pipelines pour détecter anomalies et dérives
Favoriser l’agilité dans les projets data grâce à des itérations rapides et maîtrisées
Principes du DataOps ?
Intégration Continue (CI) : validation automatisée des modifications apportées aux pipelines de données
Déploiement Continu (CD) : mise en production rapide et sécurisée des évolutions
Tests automatisés sur les datasets (qualité, fraîcheur, conformité)
Orchestration des pipelines : pilotage centralisé des traitements batch et temps réel
Collaboration renforcée entre les équipes data : data engineers, développeurs BI, analystes et métiers
Pourquoi le DataOps est nécessaire dans un SI data cloud ?
L’intégration du DataOps dans une architecture cloud permet de passer à l’ industrialisation des processus data, avec plus de rigueur, de transparence et d’agilité sur l’ensemble du cycle de vie des données.
Le premier enjeu est celui de la gouvernance distribuée. Dans un écosystème cloud où les données sont réparties entre équipes, domaines et plateformes, le DataOps permet d’instaurer une logique produit : chaque jeu de données est documenté, monitoré, versionné et rendu interopérable avec les autres. Cette approche garantit la cohérence des environnements et renforce la maîtrise des flux au sein du SI.
La qualité des données en temps réel devient également de plus en plus un impératif. Le DataOps intègre des tests automatisés et des règles métier embarquées directement dans les pipelines, permettant d’identifier les anomalies dès leur apparition et d’éviter les erreurs en aval. Cela contribue à fiabiliser les tableaux de bord, les modèles BI ou les algorithmes d’IA qui reposent sur ces données.
En ingénierie data, le DataOps introduit les principes d’intégration continue et de déploiement continu (CI/CD) dans le SI Data. Modèles BI, transformations, scripts d’intégration : tout est versionné, testé, validé puis déployé selon des workflows automatisés. Les équipes Data Engineering et BI peuvent ainsi itérer plus rapidement, sans sacrifier la qualité ou la stabilité des environnements (Top outils testing & IA).
Autre bénéfice majeur ? L’auditabilité. Attester de la conformité réglementaire est indispensable (RGPD, auditabilité financière, traçabilité métier), le DataOps permet de retracer avec précision l’origine des données, les traitements appliqués et les décisions prises. Cette transparence est devenue une brique essentielle de la gouvernance.
La résilience opérationnelle est également renforcée grâce à une supervision active des pipelines, des alertes automatiques en cas d’échec et des capacités de redémarrage ou de reprise ciblée. L’architecture data devient ainsi plus robuste et moins dépendante des interventions humaines.
Enfin, le DataOps facilite la collaboration entre les équipes data, dev et métier. En alignant les pratiques, les outils et les objectifs, cette approche décloisonne les silos et accélère la livraison de valeur, tout en assurant une meilleure compréhension des enjeux data à chaque niveau de l’organisation.
Les fondamentaux d’une architecture DataOps cloud-native
Dans un SI moderne distribué, u’approche DataOps cloud-native ne se limite pas à l’orchestration des tâches. Elle repose sur une série de piliers techniques et méthodologiques qui permettent d’industrialiser les pipelines data tout en garantissant fiabilité, traçabilité, évolutivité et maintenabilité dans le temps.
1. Infrastructure as Code (IaC) appliquée aux pipelines data
Le pipeline as code consiste à gérer les définitions des flux de données, les environnements d’exécution et les configurations cloud via du code versionné. Grâce à des outils comme Terraform ou Pulumi, il devient possible de provisionner dynamiquement les ressources nécessaires (compute, stockage, réseaux), assurant ainsi reproductibilité, auditabilité et conformité.
2. Tests automatisés et validation des datasets
La qualité des données ne s’improvise pas. Elle se construit via :
des tests de régression intégrés,
la détection de schema drift,
des règles métiers automatisées à chaque étape du pipeline.
Des outils comme Great Expectations, dbt tests ou Deequ permettent de maintenir un haut niveau de confiance dans les données livrées aux utilisateurs.
3. Orchestration intelligente et modulaire des traitements
L’orchestration reste un socle structurant des architectures DataOps. Des frameworks comme Airflow, Prefect ou Dagster orchestrent l’exécution des tâches dans une logique déclarative permettant la gestion des dépendances, la parallélisation des traitements et l’automatisation des flux de données de bout en bout.
4. CI/CD pour les pipelines data
Comme pour le DevOps, le CI/CD appliqué à la data permet de livrer des pipelines de transformation, des modèles BI ou des jobs d’intégration avec contrôle et agilité. Les processus d’intégration continue (tests, linting, pré-validation) et de déploiement automatisé assurent rapidité, stabilité et gouvernance des mises en production data.
5. Observabilité des pipelines en temps réel
L’observabilité temps réel devient critique. Elle dépasse la simple supervision technique pour intégrer :
des logs centralisés et corrélés,
des alertes intelligentes,
le suivi de lineage,
la détection d’anomalies métiers ou techniques,
et la capacité à effectuer du debug rapide grâce au croisement de traces, de métriques et de logs.
Des outils commeDatadog, Grafana, OpenTelemetry ou Monte Carlo renforcent cette couche indispensable à la résilience des pipelines.
6. Collaboration versionnée et gouvernée
Une architecture DataOps cloud-native impose une collaboration fluide et structurée entre data engineers, développeurs et métiers. Cela passe par l’usage de Git pour versionner les pipelines, de documentation centralisée pour les référentiels de données, et de pratiques partagées pour garantir l’alignement technique et métier.
Infrastructure as code pour les pipelines
Testing des datasets (tests de régression, schema drift, etc.)
Orchestration des tâches (Airflow, Dagster, Prefect…)
Quels outils pour automatiser vos pipelines data en 2025 ?
Open source ou plateforme unifiée : comment choisir une stack DataOps adaptée à votre contexte français ?
Dans le paysage technologique actuel, plusieurs familles d’outils permettent d’automatiser les pipelines data, chacune ayant ses forces, ses usages et ses contraintes. Il est essentiel de les comparer au regard de votre maturité technique, des contraintes réglementaires et de l’écosystème SI déjà en place.
Transformation & modélisation
Les outils de transformation comme dbt, Trino ou Spark sont très populaires pour leur capacité à structurer, transformer et modéliser les données. dbt se distingue particulièrement par sa philosophie SQL-first, son intégration avec Git et son adoption massive dans les communautés Data Engineering en 2025.
Orchestration des workflows
Pour piloter les dépendances, les exécutions et la planification des tâches, des frameworks matures comme Apache Airflow, Dagster et Prefect sont souvent retenus. Ils permettent de gérer des workflows complexes sur plusieurs environnements (dev, prod), de retracer les exécutions et de faire évoluer les pipelines avec modularité.
Tests / qualité des datasets
Garantir la fiabilité des données requiert l’usage d’outils de qualité comme Great Expectations, Soda ou Datafold. Ils permettent d’intégrer des vérifications automatiques à chaque étape du pipeline — contrôle de schéma, valeurs manquantes, distribution statistique — ce qui est indispensable pour une BI fiable.
Monitoring & logs / observabilité
Un pipeline automatisé doit être observable. Des solutions comme Monte Carlo, OpenLineage, ou DataDog facilitent le suivi des performances, la détection d’anomalies, la corrélation entre logs et traces, et la visualisation du lineage des données.
CI/CD & infrastructure
Pour solidifier le delivery des pipelines, l’outillage CI/CD (GitLab CI, Jenkins, CircleCI) combiné à une infrastructure as code (Terraform, Pulumi) permet de versionner, tester et déployer les pipelines et leurs environnements de manière reproductible.
Approche best‑of‑breed vs plateformes intégrées
Best‑of‑breed : composer sa stack à partir de composants spécialisés (ex. Airflow + dbt + Great Expectations + monitoring externe). Cela donne une flexibilité maximale, mais exige une forte expertise et des efforts d’intégration.
Plateformes intégrées : des solutions “tout-en-un” (ex. certains outils cloud ou SaaS data) offrent une intégration native entre orchestration, qualité et monitoring, au prix d’une moindre liberté et souvent d’un coût plus élevé.
La décision doit être aussi influencée par des impératifs de souveraineté, de localisation des données ou de préférence pour des outils déployables dans des datacenters français.
Comment Smartpoint vous accompagne dans la mise en place d’un DataOps performant ?
Pure player data & BI, nos experts Smartpoint vous recommandent votre stratégie DataOps de bout en bout.
Audit de maturité DataOps
Définition de la stack cible (outillage open source ou cloud)
Comment Smartpoint vous accompagne dans la mise en place d’un DataOps performant ?
En tant que pure player spécialisé en data et en business intelligence, Smartpoint vous aide à structurer et industrialiser votre stratégie DataOps de bout en bout — avec une approche outillée, pragmatique et centrée sur la création de valeur métier.
Notre accompagnement repose sur un socle d’expertise éprouvée :
Audit de maturité DataOps : évaluation de votre niveau d’automatisation, de gouvernance et d’agilité data.
Définition de la stack cible : choix des bons outils (open source ou cloud) selon votre contexte SI, vos usages et votre roadmap.
Architecture des workflows data : conception de pipelines robustes, scalables et observables, alignés avec vos exigences de qualité et de traçabilité.
Automatisation CI/CD des pipelines : intégration continue, tests automatisés, versioning des transformations, livraison en environnement maîtrisé.
Industrialisation de la qualité des données : mise en place de contrôles automatiques, détection d’anomalies, gestion du schema drift.
Formation des équipes & gouvernance : transfert de compétences, documentation, mise en place de rôles et de bonnes pratiques pérennes.
Expertise multi-cloud & delivery agile : Azure, GCP, Snowflake, Databricks, Kubernetes… avec des équipes organisées en mode produit et sprint court.
Besoin d’un diagnostic DataOps ou d’une trajectoire de mise en œuvre ?
Contactez-nous pour cadrer votre projet, auditer votre pipeline actuel et co-construire une architecture DataOps performante, évolutive et alignée avec vos enjeux BI & cloud.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Tout savoir sur la DataOps
Quelle est la différence entre DataOps et DevOps ?
DevOps concerne le cycle de vie des applications. DataOps applique ces principes (CI/CD, tests, monitoring) aux pipelines de données. L’objectif : fiabilité, agilité, qualité des données.
Le DataOps est-il que pour les grandes entreprises ?
Non. Même les PME peuvent tirer profit du DataOps, notamment pour fiabiliser leurs pipelines ET gagner en réactivité sur la BI. L’approche peut être progressive (PoC, MVP…).
Peut-on faire du DataOps sans Kubernetes ?
Oui. Kubernetes apporte de la scalabilité mais ce n’est pas indispensable. Des orchestrateurs comme Airflow ou Prefect fonctionnent très bien sur des architectures plus simples.
Peut-on faire du DataOps avec Power BI ?
Oui, Power BI peut s’intégrer à une architecture DataOps. On peut versionner les rapports, automatiser les déploiements (via scripts), et intégrer des tests en amont sur les datasets.
Quelles compétences nécessaires pour un projet DataOps ?
Un mix entre data engineering, DevOps et BI : Python / SQL, Orchestration / CI/CD, Data quality / monitoring et culture produit.
Architecture
Interopérabilité et APIsation, les piliers des architectures Data modernes
0 commentaires
Dernière mise à jour : octobre 2025
Dans un monde où la donnée est reine, la capacité à concevoir des systèmes véritablement interopérables est devenue incontournable. L’interopérabilité et les APIs sont les piliers des architectures data moderne, facilitant la communication, l’échange et l’intégration des données entre différents systèmes et applications. Alors que les données sont disparates et d’une variété de plus en plus large, la capacité à interagir de manière transparente et efficace avec divers systèmes est devenue une nécessité pour les entreprises souhaitant valoriser leurs données. La fragmentation des données et les silos informationnels sont des défis majeurs auxquels l’interopérabilité et les APIs répondent de manière incontournable.
La taille du marché des APIs en France est en constante croissance. Selon Xerfi, le marché devrait atteindre 2,8 milliards de dollars en 2024, soit une augmentation de 50 % par rapport à 2023. Cette croissance reflète l’importance croissante des APIs dans le paysage technologique actuel.
Définition et Principes de l’Interopérabilité
L’interopérabilité désigne la capacité de différents systèmes, applications et services à communiquer, échanger des données et utiliser les informations échangées de manière efficace. Elle repose sur des normes et des protocoles communs permettant de surmonter les barrières technologiques et organisationnelles. Les APIs, en tant que points d’accès standardisés, sont essentielles pour permettre cette interopérabilité.
Ces systèmes interopérables permettent aux organisations d’établir des connexions pérennes entre leurs différents composants technologiques, garantissant ainsi une meilleure interopérabilité technique et fonctionnelle.
Principes de l’Interopérabilité
Standardisation : Utilisation de formats de données standardisés (XML, JSON, etc.) et de protocoles de communication (HTTP, REST, SOAP).
Modularité : Conception de systèmes modulaires pouvant être facilement connectés et déconnectés.
Scalabilité : Capacité des systèmes interopérables à évoluer en fonction des besoins de l’entreprise.
Sécurité : Mise en place de mécanismes de sécurité robustes pour protéger les échanges de données.
Les Avantages de l’Interopérabilité et des APIs
Flexibilité : Les systèmes peuvent être facilement intégrés, ce qui permet aux entreprises de s’adapter rapidement aux changements technologiques et aux nouvelles opportunités.
Réduction des coûts : En permettant la réutilisation des services existants, les APIs réduisent les coûts de développement et de maintenance. On estime que les entreprises qui adoptent des APIs peuvent réduire leurs coûts de développement de 30 % et améliorer leur efficacité opérationnelle de 25 % selon Forrester.
Amélioration de l’efficacité : Les échanges de données fluides entre systèmes améliorent l’efficacité opérationnelle et la prise de décision.
Innovation accélérée : L’accès facilité aux données et aux services stimule l’innovation et permet de développer rapidement de nouvelles applications ou produits.
En créant des environnements interopérables, les entreprises facilitent la circulation fluide de la donnée, éliminent les silos et posent les bases d’une gouvernance data agile.
Différents types d’API
Les APIs se déclinent en plusieurs variétés, chacune avec ses propres caractéristiques, avantages et inconvénients. Chacune de ces APIs joue un rôle essentiel pour rendre les composants logiciels interopérables et capables de communiquer à travers des environnements hétérogènes. Parmi les plus courants, on trouve :
APIs REST (Representational State Transfer) :
Avantages : Faciles à utiliser et à comprendre, largement adoptées, flexibles et évolutives.
Inconvénients : Peuvent être verbeuses et inefficaces pour les requêtes complexes, nécessitent une bonne compréhension de l’architecture sous-jacente.
APIs SOAP (Simple Object Access Protocol) :
Avantages : Normées et sécurisées, idéales pour les systèmes d’entreprise complexes.
Inconvénients : Plus lourdes et plus complexes à implémenter que les APIs REST, moins flexibles.
APIs GraphQL :
Avantages : Offrent une grande flexibilité et permettent aux clients de récupérer uniquement les données dont ils ont besoin, réduisant ainsi la latence et la consommation de bande passante.
Inconvénients : Plus récentes et moins matures que les APIs REST et SOAP, courbe d’apprentissage plus élevée.
Étude de Cas : Interopérabilité et APIs dans une entreprise de e-commerce
Prenons l’exemple d’une plateforme de e-commerce qui utilise des APIs pour intégrer divers services tels que la gestion des stocks, le traitement des paiements et la recommandation de produits. Grâce à des APIs standardisées, la plateforme peut facilement intégrer de nouveaux fournisseurs de services, adapter ses offres en temps réel et améliorer l’expérience utilisateur.
Intégration des APIs et de l’interopérabilité dans les principales plateformes du Marché
Les principales plateformes cloud et d’analyse de données offrent des outils puissants pour faciliter l’interopérabilité et l’utilisation des APIs. Ces solutions permettent de bâtir des architectures scalables, flexibles et interopérables, capables de s’adapter aux évolutions rapides de l’écosystème data. :
Microsoft Azure et Power BI : Azure propose une vaste gamme de services APIs pour l’intégration de données, le machine learning et l’Internet des objets (IoT). Power BI utilise ces APIs pour offrir des visualisations interactives et des analyses en temps réel, facilitant ainsi l’intégration et l’analyse des données provenant de diverses sources.
Amazon Web Services (AWS) : AWS offre des services API via AWS Lambda, API Gateway et d’autres services cloud, permettant de créer des architectures serverless et d’intégrer des applications et des systèmes de manière transparente. Les APIs AWS facilitent également l’intégration avec des services tiers et des solutions SaaS.
Google Cloud Platform (GCP) : GCP fournit des APIs robustes pour le stockage, l’analyse de données et le machine learning, avec des services comme BigQuery, Pub/Sub et AI Platform. Ces APIs permettent une interopérabilité facile entre les différents composants de l’écosystème GCP et d’autres systèmes.
Snowflake : Snowflake, en tant que solution de data warehouse cloud-native, offre des APIs pour l’intégration et l’analyse des données en temps réel. Les entreprises peuvent utiliser les APIs de Snowflake pour connecter facilement leurs données à divers outils d’analyse et applications.
Databricks : Databricks, basé sur Apache Spark, propose des APIs pour le traitement des données et le machine learning. Ces APIs permettent une intégration fluide avec d’autres services cloud et applications, facilitant ainsi l’analyse des big data.
MicroStrategy : MicroStrategy offre des APIs pour la BI et l’analytique, permettant une intégration avec une variété de sources de données et d’applications. Les APIs de MicroStrategy permettent aux entreprises de créer des tableaux de bord personnalisés et des rapports interactifs.
Bonnes pratiques pour l’implémentation des APIs
Conception axée utilisateurs : Comprendre les besoins des utilisateurs finaux et concevoir des APIs intuitives et faciles à utiliser.
Documentation complète : Fournir une documentation détaillée et à jour pour aider les développeurs à comprendre et utiliser les APIs efficacement.
Sécurité intégrée : Implémenter des mécanismes de sécurité tels que l’authentification, l’autorisation et le chiffrement des données.
Gestion des versions : Gérer les versions des APIs pour assurer la compatibilité et faciliter les mises à jour.
Monitoring et analyse : Surveiller l’utilisation des APIs et analyser les performances pour identifier et résoudre les problèmes rapidement.
Défis et solutions
Complexité de l’intégration : L’intégration de systèmes disparates peut être complexe. La solution réside dans l’adoption de standards communs et la mise en place d’APIs bien documentées.
Sécurité des échanges de données : Protéger les données échangées est crucial. L’utilisation de protocoles de sécurité robustes (OAuth, TLS) et la mise en place de contrôles d’accès stricts sont essentielles.
Gestion de la scalabilité : Les systèmes doivent pouvoir évoluer avec les besoins de l’entreprise. La conception d’APIs scalables et l’utilisation de services cloud peuvent aider à répondre à ce défi.
Gouvernance des données : Les données échangées entre les systèmes et les applications doivent être gouvernées efficacement pour garantir leur qualité, leur cohérence et leur sécurité.
Tendances à suivre
L’avenir de l’interopérabilité et des APIs dans les architectures de données sera marqué par :
Le cloud : Permet aux entreprises de déployer et de gérer des architectures data interopérables et basées sur les API.
APIs GraphQL : Permet des requêtes plus flexibles et optimisées par rapport aux APIs REST traditionnelles.
Interopérabilité basée sur l’IA : Facilite et optimise les échanges de données entre systèmes.
Blockchain : Garantit la sécurité et la traçabilité des échanges de données.
Le paysage des architectures data est en constante évolution, porté par des tendances qui redéfinissent la manière dont les entreprises gèrent et exploitent leurs données. Parmi les plus marquantes, on observe une APIification croissante, où de plus en plus de fonctionnalités et de services sont exposés via des APIs. Cette approche favorise l’interopérabilité et la consommation de données par des applications et systèmes externes, stimulant ainsi l’innovation et la collaboration.
Ces tendances soulignent l’importance d’une architecture data moderne, capable de répondre aux défis croissants de l’interopérabilité, de la sécurité et de l’innovation. En adoptant les technologies et approches les plus récentes, les entreprises peuvent tirer le meilleur parti de leurs données et stimuler leur croissance. L’interopérabilité est plus qu’un besoin technique : c’est une nécessité. En misant sur des environnements pleinement interopérables, les entreprises s’ouvrent à un écosystème riche, évolutif et résilient. En adoptant des pratiques de conception robustes et en restant à l’affût des nouvelles tendances, les entreprises peuvent créer des systèmes flexibles, sécurisés et évolutifs capables de répondre aux défis de demain.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Interopérabilité, APIsation et architectures data modernes ?
Qu’est-ce que l’APIsation dans une architecture data ?
L’APIsation désigne le processus consistant à exposer des services, fonctions ou données via des API (interfaces de programmation applicative). Cette démarche permet aux applications de communiquer entre elles de manière fluide et interopérable, sans dépendre des technologies sous-jacentes. Dans une architecture data moderne, l’APIsation favorise la modularité, l’agilité et l’intégration rapide de nouveaux services.
Quelle est la différence entre interopérabilité technique et fonctionnelle ?
’interopérabilité technique concerne la capacité de différents systèmes à échanger des données au niveau technique (protocoles, formats, etc.), tandis que l’interopérabilité fonctionnelle s’attache à la compréhension et à l’exploitation correcte de ces données par les applications. Les architectures data interopérables combinent ces deux niveaux pour garantir un fonctionnement cohérent et fiable des services métiers.
Pourquoi les API sont-elles essentielles dans une architecture data interopérable ?
Les API agissent comme des passerelles standardisées entre les composants logiciels. Elles permettent de créer des systèmes ouverts et interopérables, capables de s’adapter rapidement aux évolutions technologiques. En facilitant la communication entre les sources de données, applications et services cloud, les API sont devenues un pilier central des architectures data modernes.
Quels sont les avantages d’une architecture data interopérable ?
Casser les silos de données Faciliter l’intégration multi-systèmes Réduire les coûts d’intégration Accélérer l’innovation et le time-to-market Améliorer la qualité des données et leur disponibilité en temps réel
Quels types d’API choisir pour une architecture évolutive ?
Les API REST et GraphQL sont les plus couramment utilisées dans les architectures interopérables modernes. REST est simple et largement adopté, tandis que GraphQL offre plus de flexibilité dans la récupération des données. Le choix dépend des cas d’usage, de la volumétrie des données et des besoins métiers en termes de performance et de personnalisation.
En quoi l’APIsation contribue-t-elle à la gouvernance des données ?
L’APIsation permet un contrôle centralisé des points d’accès aux données. Chaque API peut être monitorée, sécurisée et documentée, ce qui favorise la traçabilité, la qualité des données et la conformité réglementaire (RGPD, sécurité, etc.). Elle renforce ainsi la gouvernance des architectures data interopérables.
Outils Data
Testing automatisé augmenté par l’IA, notre top 5 outils 2024
0 commentaires
Dernière mise à jour : octobre 2025
L’intégration de l’intelligence artificielle (IA) dans les processus de testing représente une avancée majeure dans le domaine de la qualité logicielle (QA). En 2024, l’IA continue de transformer les pratiques de test automation en offrant des gains jusqu’alors inégalés en termes de productivité, de qualité, et de réduction des coûts.
En 2024, le test automatisé IA remet à plat les pratiques de QA augmentée en réduisant les coûts tout en améliorant la qualité logicielle. Ces nouvelles approches de testing intelligent redéfinissent les standards du marché.
Les bénéfices du testing augmenté à l’IA pour nos clients
1/ Amélioration de la Qualité Logicielle
L’IA permet d’identifier les défauts plus tôt et bien plus précisément que les tests manuels, réduisant ainsi le nombre de bugs et améliorant la qualité globale du logiciel. Les capacités d’apprentissage automatique de l’IA permettent également de générer des cas de tests exploratoires, couvrant ainsi des scénarios que les tests traditionnels auraient du mal à identifier.
2/ Réduction des coûts :
L’automatisation des tests permet de réduire drastiquement les coûts de main-d’œuvre et d’optimiser l’utilisation des ressources. 66 % des entreprises ont réussi à réduire leurs coûts de 21 à 50 % grâce à l’automatisation des tests. (Source enquête Qualitest). Moins de bugs en production signifie également moins de coûts associés à la correction des erreurs post-livraison.
3/ Accélération du Time-to-Market
L’IA permet d’exécuter des tests en continu et en parallèle, ce qui accélère le processus de validation et permet une mise sur le marché plus rapide des produits. C’est également plus d’adaptabilité car l’IA s’adapte rapidement aux changements dans le code. Les délais liés aux ajustements des tests sont également réduits. 56% des entreprises ont réduit le temps de test de 35 à 65% grâce à l’IA (Source Xray)
4/ Amélioration de l’efficacité
L’IA surveille et analyse les performances des applications en temps réel, permettant une identification rapide des problèmes et une optimisation continue. 73 % des entreprises affirment que l’IA a amélioré l’efficacité de leurs tests. (Source : Xray)
Les bénéfices de l’IA QA DevOps résident aussi dans l’agilité des workflows CI/CD, permettant une validation continue grâce à des scénarios de test prédictif logiciel.
Cas d’usages de l’IA dans les tests
Le recours au machine learning testing permet de détecter des anomalies complexes et d’anticiper les bugs critiques.
Certaines plateformes d’AI for software testing proposent même des tests fonctionnels adaptatifs (functional testing AI) générés automatiquement selon les évolutions du code.
Tests unitaires automatisés : Si le code est bien géré avec des pratiques appropriées de gestion de la configuration logicielle, les algorithmes d’analyse du code peuvent être utilisés pour automatiser les tests unitaires, assurant une couverture complète et réduisant les erreurs humaines.
Tests d’API Automatisés : Dans le cas d’une architecture microservices, les algorithmes peuvent générer automatiquement des tests d’API, assurant que chaque service communique correctement avec les autres, ce qui améliore l’intégrité du système.
Génération automatisée de données de test : En surveillant les données de production, des algorithmes de régression peuvent générer automatiquement des données de test synthétiques, assurant que les tests sont représentatifs des conditions réelles.
Prédiction des goulets d’étranglement : En utilisant les journaux opérationnels, des algorithmes de régression peuvent prédire les goulets d’étranglement et les points de référence en matière de performance, permettant une optimisation proactive.
Automatisation des scripts de développement axés sur le comportement : Les algorithmes de traitement du langage naturel peuvent convertir des récits d’utilisateurs rédigés en langage simple en formats Gherkin, créant ainsi des tests automatisés basés sur le comportement utilisateur.
Optimisation basée sur l’Analyse des Défauts : En se focalisant sur les zones à risque en utilisant des données historiques propres aux défauts, des algorithmes de corrélation peuvent identifier les fonctionnalités les plus sujettes aux défauts, permettant aux équipes de se concentrer sur ces zones lors des tests.
Détermination des scénarios critiques : En analysant les comportements des utilisateurs en production, des algorithmes d’apprentissage non supervisés peuvent identifier les scénarios les plus importants à tester, optimisant ainsi la couverture des tests.
Notre Top 5 des outils de testing augmentés à l’IA à adopter en 2024
Voici les outils de test IA que nos experts recommandent en 2024 pour automatiser intelligemment vos process QA. Ces solutions s’inscrivent dans une logique de test logiciel automatisé 2024, où l’IA QA DevOps devient un standard pour accélérer les cycles de vie.
Selenium est un outil de testing open source largement utilisé pour l’automatisation des tests web. Avec l’intégration de frameworks IA, Selenium améliore la capacité à détecter et à corriger les erreurs plus efficacement.
Avantages ? Flexibilité, large adoption, compatibilité avec de nombreux langages de programmation.
Spécialisé dans les tests visuels, Applitools utilise l’IA pour valider les interfaces utilisateur en comparant automatiquement les captures d’écran à des versions de référence.
Avantages ? Amélioration de la qualité UI/UX, réduction des erreurs visuelles.
Testim utilise l’IA pour créer, exécuter et maintenir des tests automatisés avec une grande précision. Il améliore continuellement les scripts de test en apprenant des modifications de l’application.
Avantages ? Réduction des temps de maintenance des tests, meilleure détection des changements dans l’application.
Une plateforme de tests unifiée qui utilise l’IA pour automatiser les tests web, API, mobiles et desktop. Katalon Studio offre des fonctionnalités avancées d’analyse des tests et d’optimisation.
Avantages ? Facilité d’utilisation, large couverture de tests.
Functionize combine l’apprentissage automatique et le traitement du langage naturel pour créer des tests adaptatifs. Il offre une reconnaissance visuelle et des tests automatisés basés sur des scénarios utilisateurs réels.
Avantages ? Tests adaptatifs, réduction des efforts de scriptage.
Pourquoi passer au testing intelligent ?
L’adoption de l’AI for software testing en 2024 est certes un véritable avantage compétitif mais c’est surtout devenu une une nécessité pour toutes les entreprises engagées dans une démarche DevOps et qualité logicielle automatisée.
Le testing augmenté à l’IA est un domaine en pleine évolution qui offre de nombreux avantages aux entreprises et aux clients. En 2024, l’adoption de cette technologie devrait s’accélérer, avec des outils et des solutions encore plus puissants disponibles sur le marché. Les entreprises qui investissent dans le testing augmenté à l’IA seront en mesure d’améliorer la qualité de leurs logiciels, d’offrir une meilleure expérience utilisateur, de réduire leurs coûts et de mettre leurs produits sur le marché plus rapidement. L’implémentation de l’IA dans les processus de testing est un levier puissant pour améliorer la qualité, la productivité et l’efficacité tout en réduisant les coûts. En 2024, les outils de testing augmentés à l’IA continuent d’évoluer, offrant des fonctionnalités toujours plus sophistiquées et une intégration plus étroite avec les processus de développement logiciel.
Vous souhaitez intégrer l’automatisation et l’IA dans vos processus de test ? Challengez-nous !
LAISSEZ-NOUS UN MESSAGE
Les champs obligatoires sont indiqués avec *.
En savoir plus sur AI Testing ou QA augmentée ?
Qu’est-ce que le test automatisé IA ?
Le test automatisé IA désigne l’utilisation de l’intelligence artificielle pour automatiser, adapter et optimiser les tests logiciels. Contrairement aux tests traditionnels, l’IA permet d’identifier les scénarios critiques, d’adapter les scripts en temps réel et d’exécuter des tests prédictifs sur base d’analyses comportementales.
Quelle est la place de l’IA dans les processus QA DevOps ?
L’IA QA DevOpspermet d’intégrer l’intelligence artificielle directement dans les chaînes CI/CD. Cela facilite l’exécution continue des tests, leur adaptation automatique aux évolutions du code, et une meilleure fiabilité des livraisons logicielles.
Quelle valeur ajoutée du testing intelligent vs le testing classique ?
Le testing intelligent repose sur l’analyse automatique des données de test et des comportements utilisateurs. Il permet une couverture plus large, une maintenance réduite, et une détection anticipée des anomalies. C’est une composante clé de la QA augmentée.
Quels sont les meilleurs outils de test IA ?
Parmi les meilleurs outils de test IA, nous recommandons Testim, Applitools, Functionize, ou encore Katalon Studio. Ces solutions combinent machine learning testing, reconnaissance visuelle et génération automatique de cas de test pour accélérer les cycles de développement.
Quelle est la différence entre test automation AI et functional testing AI ?
Le test automation AI concerne l’ensemble des techniques d’automatisation pilotées par IA, incluant l’optimisation des scripts, la génération de données de test et l’auto-maintenance. Le functional testing AI, quant à lui, se concentre sur les tests des fonctionnalités logicielles à l’aide d’IA pour en valider le comportement attendu.
Qu’est-ce que le test prédictif logiciel ?
Un test prédictif logiciel anticipe les pannes ou les défauts en analysant des données historiques, des journaux d’erreurs ou des comportements utilisateurs. Grâce à des algorithmes de régression ou de corrélation, il cible les zones à haut risque pour améliorer la qualité dès la phase de validation.
Architecture
Datalake VS. Datawarehouse, quelle architecture de stockage choisir ?
0 commentaires
Dernière mise à jour : octobre 2025
Alors que les volumes des données collectées croient de manière exponentielle dans une variété de formats considérable, vous devez choisir comment les stocker. Devez-vous opter pour un lac de données (datalake) ou pour un entrepôt de données (datawarehouse) ? Cette décision n’est pas anodine car elle influence l’architecture globale du système d’information data, la stratégie de gestion des données et, finalement, la capacité de votre entreprises à exploiter ces données pour créer de la valeur sur vos marchés.
Un datalake, c’est comme une vaste réserve centralisée conçue pour stocker de grandes quantités de données brutes, quel que soit le format. Son principal avantage réside dans sa capacité à héberger des données non structurées, semi-structurées et structurées, offrant ainsi une flexibilité sans précédent pour l’exploration, l’analyse et l’exploitation de données via des technologies avancées comme l’IA et le machine learning.
Un datawarehouse est une solution de stockage qui organise les données en schémas structurés et hiérarchisés. Spécialement conçu pour les requêtes et les analyses avancées, il est reconnu pour ses performances, sa fiabilité, l’intégrité des données pour les opérations décisionnelles et la génération de rapports.
Le choix entre ces deux architectures de stockage n’est pas anodin. Il doit être éclairé par une fine compréhension des besoins en données de votre entreprise, de ses objectifs stratégiques, de ses processus opérationnels et de ses capacités analytiques.
1. Comprendre les datalakes et les entrepôts de données
1.1 Définition et objectifs
Un datalake est une architecture de stockage conçue pour stocker de très larges volumes de données sous leur forme brute, c’est-à-dire dans leur format natif non transformé. Contrairement aux bases de données traditionnelles, il n’impose pas de schéma au moment de l’écriture des données (schema-on-write), mais au moment de la lecture (schema-on-read), offrant ainsi une souplesse inégalée dans la manipulation et l’exploration des données. L’objectif principal d’un datalake est de centraliser les données non structurées et structurées d’une entreprise pour permettre des analyses futures très diverses, y compris l’exploration de données, le big data, le datamining, les analytics et l’intelligence artificielle.
Un entrepôt de données, ou datawarehouse, est une solution de stockage qui collecte des données en provenance de différentes sources et les transforme selon un schéma fixe, structuré et prêt à l’emploi. Il est optimisé pour assurer la rapidité et l’efficacité des requêtes et des rapports analytiques. Il est conçu pour le traitement rapide des opérations de lecture et d’écriture. L’objectif d’un entrepôt de données est de fournir une vision cohérente et unifiée des données, facilitant ainsi la prise de décision et la génération de rapports standardisés pour les fonctions opérationnelles métiers et stratégiques de l’entreprise.
1.2 Comparaison des fonctionnalités et des cas d’utilisation
Fonctionnalités des datalakes
Stockage de données à grande échelle en format brut
Capacité de stockage économique qui permet de conserver des données hétérogènes, facilitant un large éventail d’analyses exploratoires et un réservoir à explorer d’innovations futures data centric
Support de tous types de données (structurées, semi-structurées, non structurées) y compris des data tels que les logs, les flux IoT, etc.
Écosystème propice à la démocratisation de l’analyse des données, permettant aux data scientists et aux analystes de travailler avec des données non préparées ou semi-préparées
Flexibilité pour l’expérimentation avec des modèles de données évolutifs et des schémas à la volée
Intégration facile avec des outils d’analyse avancée et de machine learning
Flexibilité dans le modèle de données, qui permet des analyses exploratoires et ad-hoc
Fonctionnalités des datawarehouses
Stockage de données organisé selon un schéma défini et optimisé pour les requêtes ; avec également des outils d’ETL (Extract, Transform, Load) éprouvés pour la transformation des données
Haute performance pour les requêtes structurées et les rapports récurrents
Une source de vérité unique pour l’entreprise, facilitant la cohérence et la standardisation des métriques et des KPIs
Fiabilité et intégrité des données pour la prise de décision basée sur des données historiques consolidées
Interfaces utilisateurs conviviales pour la business intelligence, avec des capacités de reporting avancées et des visualisations interactives.
Intégration avec les systèmes de gestion de la relation client (CRM) et de planification des ressources de l’entreprise (ERP), enrichissant les données transactionnelles pour des analyses décisionnelles stratégiques
Cas d’utilisation des datalakes
Scénarios nécessitant une exploration de données pour identifier des opportunités de marchés émergents, pour prévoir des tendances de consommation ou des modèles cachés.
Environnements innovants où l’analytique en temps réel et l’intelligence opérationnelle peuvent transformer des flux de données en actions immédiates.
Projets de recherche et développement (R&D) où des données variées doivent être explorées sans la contrainte d’un schéma prédéfini.
Cas d’utilisations des datawarehouses
Dans les industries réglementées, comme les services financiers ou la santé, où l’intégrité et la traçabilité des données sont essentielles pour la conformité réglementaire.
Lorsque l’on a besoin de mener des analyses sur de longues périodes pour suivre leur évolution au fil du temps et anticiper les tendances futures. Les data warehouses offre une base solide pour les systèmes décisionnels pour les managers qui souhaitent prendre leurs décisions sur la base de données historiques détaillées.
Lorsqu’il est crucial de rapprocher des données issues de sources multiples en informations cohérentes pour piloter la stratégie d’entreprise et optimiser les processus opérationnels.
2. Avantages et Inconvénients
Avantages d’un data lake
Le data lake offre beaucoup de flexibilité pour le stockage de données. Son avantage principal réside dans sa capacité à accueillir tous types de données, des données structurées telles que les lignes et les colonnes des bases de données relationnelles, aux données non structurées comme les textes libres ou encore des médias. Ceci est un véritable avantage pour les organisations agiles qui souhaitent capitaliser sur la variété et la vitesse des données actuelles, y compris les données générées par les appareils connectés (IoT), les plateformes de médias sociaux, et autres sources numériques. L’intégration avec des plateformes d’analyses avancées et le machine learning permet d’extraire des insights précieux qui peuvent être sources d’innovation.
Avantages d’un Entrepôt de Données
L’entrepôt de données, quant à lui, est spécialement conçu pour la consolidation de données issues de divers systèmes en un format cohérent et uniforme. C’est un peu comme une bibliothèque traditionnelle où chaque livre – ou plutôt chaque donnée – a sa place attitrée, classée, indexée ! C’est une solution à privilégier pour les entreprises qui ont besoin d’effectuer des analyses complexes et récurrentes, qui exigent de la performance dans le traitement des requêtes. La structuration des données dans des schémas prédéfinis permet non seulement des interrogations rapides et précises mais assure également l’intégrité et la fiabilité des informations, ce qui est essentiel pour les rapports réglementaires, les audits et la prise de décision stratégique. Les Data warehouses sont également conçus pour interagir avec des outils de reporting et de business intelligence, offrant ainsi de la data visualisation et des analyses compréhensibles par les utilisateurs finaux.
Inconvénients, Limites et Défis
Malgré leurs nombreux avantages, les data lakes et les entrepôts de données ont chacun leurs limites ! Le data lake, de par sa nature même, peut devenir un « data swamp » si les données ne sont pas gérées et gouvernées correctement, rendant les informations difficilement exploitables. La mise en place d’une gouvernance efficace et d’un catalogue de données s’avère nécessaire pour maintenir la qualité et la questionnabilité des données.
Les data warehouses, bien que fortement structurés et performants pour les requêtes prédéfinies, peuvent être rigides en termes d’évolutivité et d’adaptabilité. L’intégration de nouvelles sources de données ou l’ajustement aux nouvelles exigences analytiques peut se révéler très coûteuse et chronophage. De plus, les entrepôts traditionnels peuvent ne pas être aussi bien adaptés à la manipulation de grands volumes de données non structurées, ce qui peut limiter leur application dans les scénarios où les formes de données sont en constante évolution.
3. Critères de choix entre un data lake et un data warehouse
3.1 Volume, Variété et Vitesse de la data
Les trois « V » de la gestion des données – volume, variété et vitesse – sont des critères essentiels dans votre choix entre un data lake et un data warehouse. Si votre organisation manipule des téraoctets ou même des pétaoctets de données diversifiées, issues de différentes sources en flux continus, un data lake est à priori le choix le plus adapté. Sa capacité à ingérer rapidement de grands volumes de données hétérogènes, voire évolutives, en fait un critère de choix déterminant dans les situations où la quantité et la multiplicité des données dictent la structure de l’infrastructure technologique.
3.2 Analyse et traitement des données
L’approche et les outils que vous utilisez pour l’analyse et le traitement des données influencent également le choix de votre architecture de stockage. Les data lakes, avec leur flexibilité et leur capacité d’ingestion de données en l’état, sont parfaitement adaptés aux environnements exploratoires où le data mining et le traitement par intelligence artificielle sont votre lot quotidien. En revanche, si vos besoins s’articulent autour d’analyses structurées et de reporting périodique, un data warehouse offre un environnement hautement performant optimisé pour ces activités, avec la possibilité d’extraire les données de manière rapide et fiable.
3.3 Gouvernance, sécurité et conformité
La manière dont vous gérez la gouvernance, la sécurité et la conformité des données est un facteur déterminant. Les data warehouses, avec leurs schémas de données structurés et leur maturité en matière de gestion de la qualité des données, offrent un cadre plus strict et sécurisé, ce qui est impératif dans les environnements réglementés. Les data lakes requièrent quant-à-eux une attention particulière en matière de gouvernance et de sécurité des données, surtout parce qu’ils stockent des informations à l’état brut, qui pourraient inclure des données sensibles ou personnelles.
3.4 Coûts et complexité de mise en oeuvre
Enfin, les considérations financières et la complexité de la mise en œuvre sont des critères déterminants. Mettre en place un data lake est souvent moinscoûteux en termes de stockage brut, mais nécessite souvent des investissements significatifs additifs en outils et en compétences pour être en capacités d’exploiter pleinement cet environnement. Les data warehouses, en revanche, générèrent souvent des coûts initiaux plus élevés, mais leur utilisation est souvent plus rapide et moins complexe, avec un ensemble d’outils déjà intégrés pour la gestion et l’analyse des données.
4. Architecture et technologies : Data Lakes vs. Data Warehouses
L’architecture et les technologies des data lakes et des data warehouses révèlent des différences essentielles dans la manière dont les données sont stockées, gérées, et exploitées. Ces différences influencent directement le choix entre ces deux solutions en fonction des besoins spécifiques en matière de données.
4.1. Stockage de Données
Data Lakes : Les data lakes sont conçus pour stocker d’énormes volumes de données sous leur forme brute, sans nécessiter de schéma prédéfini pour le stockage. Cela permet une grande flexibilité dans le type de données stockées, qu’elles soient structurées, semi-structurées ou non structurées. Les technologies comme Apache Hadoop et les services cloud comme Amazon S3 sont souvent utilisés en raison leur évolutivité et leurs capacités à gérer de très larges volumes.
Data Warehouses : À l’inverse, les data warehouses stockent des données qui ont été préalablement traitées (ETL – Extract, transform & load) et structurées selon un schéma prédéfini, ce qui facilite les requêtes complexes et l’analyse de données. Des solutions comme Amazon Redshift, Google BigQuery, et Snowflake sont reconnues pour leur efficacité dans le stockage et la gestion de données structurées à grande échelle.
4.2. Indexation et Optimisation des Requêtes
Data Lakes : L’indexation dans les data lakes peut être plus complexe en raison de de l’hétérogénéité des formats de données. Cependant, des outils comme Apache Lucene ou Elasticsearch peuvent être intégrés pour améliorer la recherche et l’analyse des données non structurées. Les data lakes requièrent souvent un traitement supplémentaire pour optimiser les requêtes.
Data Warehouses : Les data warehouses bénéficient d’une indexation et d’une optimisation des requêtes plus avancées dès le départ, grâce à leur structure hautement organisée. Des techniques comme le partitionnement des données et le stockage en colonnes (par exemple, dans Amazon Redshift) permettent d’exécuter des analyses complexes et des requêtes à haute performance de manière plus efficace.
4.3. Technologies et outils éditeurs
Différents éditeurs et technologies offrent des solutions spécialisées pour les data lakes et les data warehouse :
Pour les Data Lakes :
Apache Hadoop : Écosystème open-source qui permet le stockage et le traitement de grandes quantités de données.
Amazon S3 : Service de stockage objet offrant une scalabilité, une disponibilité et une sécurité des données.
Microsoft Azure Data Lake Storage : Solution de stockage haute performance pour les data lakes sur Azure.
Pour les Data Warehouses
Snowflake : Infrastructure de données cloud offrant une séparation du stockage et du calcul pour une élasticité et une performance optimisée.
Google BigQuery : Entrepôt de données serverless, hautement scalable, et basé sur le cloud.
Oracle Exadata : Solution conçue pour offrir performance et fiabilité pour les applications de bases de données critiques.
Databricks, le pont entre Data Lakes et Data Warehouses
Databricks a un rôle crucial dans l’évolution des architectures de données en offrant une solution qui réduit la frontière entre les data lakes et les data warehouses. Par son approche lakehouse, Databricks permet aux organisations de gérer leurs données de manière plus efficace, en facilitant à la fois le stockage de grandes quantités de données brutes et l’analyse avancée de ces données.
Plateforme Unifiée : Databricks offre une plateforme basée sur Apache Spark qui permet aux utilisateurs de réaliser des tâches d’ingénierie de données, de science des données, de machine learning, et d’analyse de données sur un même environnement. Cette approche intégrée facilite la collaboration entre les équipes et optimise le traitement des données.
Data Lakehouse : Databricks promeut le concept de « Lakehouse », un modèle d’architecture qui combine les avantages des data lakes et des data warehouses. Le lakehouse vise à fournir la flexibilité et la capacité de stockage des data lakes pour des données brutes et diversifiées, tout en offrant les capacités d’analyse et de gestion de la qualité des données typiques des data warehouses.
Delta Lake : La technologie proposée par Databricks est Delta Lake, un format de stockage qui apporte des fonctionnalités transactionnelles, de gestion de la qualité des données, et d’optimisation des requêtes aux data lakes. Delta Lake permet aux organisations de construire un data lakehouse, en rendant les data lakes plus fiables et performants pour des analyses complexes.
Avantages en architectures Data : En utilisant Databricks, les entreprises peuvent tirer parti de la scalabilité et de la flexibilité des data lakes tout en bénéficiant des performances et de la fiabilité des data warehouses. Cette approche permet d’effectuer des analyses avancées, du traitement de données en temps réel, et du machine learning à grande échelle.
Intégration avec les Écosystèmes de Données Existantes : Databricks s’intègre facilement avec d’autres plateformes de données, comme les services de stockage cloud (Amazon S3, Azure Data Lake Storage, Google Cloud Storage) et les solutions de data warehouse (Snowflake, Google BigQuery, etc.), offrant ainsi une grande flexibilité dans la conception de l’architecture de données.
5. Cas pratiques et scénarios d’utilisation par secteur
5.1 Cas d’utilisation d’un Data Lake
Géants du web : Les entreprises de la tech utilisent des data lakes pour analyser d’importants volumes de données utilisateurs afin d’affiner les algorithmes de recommandation, de personnaliser l’expérience client et d’optimiser les stratégies de contenu et de publicité.
Industries : Les data lakes permettent de collecter et d’analyser les données issues des capteurs IoT pour la surveillance en temps réel des équipements, l’optimisation des chaînes logistiques, et la prévision des opérations de maintenance.
Transport : Les entreprises du secteur automobile exploitent des data lakes pour traiter de grandes quantités de données issues de tests de véhicules et ou encore celles relatives aux véhicules autonomes et à l’analyse des comportements de conduite.
5.2 Cas d’utilisation d’un Entrepôt de Données
Finance et banque : Les institutions financières et bancaires s’appuient sur des data warehouses pour effectuer des analyses de marché, générer des rapports de performance financière, et conduire des analyses de risques basées sur des données historiques.
Retail: Les entreprises de retail utilisent des data warehouses pour analyser les tendances d’achat et de consommation sur plusieurs années, permettant une gestion des stocks plus précise et le développement de campagnes marketing ciblées.
Énergie : Les sociétés du secteur de l’énergie exploitent des data warehouses pour la gestion des données relatives à la production, à la consommation énergétique, et pour se conformer aux régulations environnementales et leur exigences en termes de reporting.
5.3 Synthèse des meilleures pratiques
Une mise en œuvre réussie des data lakes et des data warehouses dépend de la stratégie qui va orienter votre choix d’architecture de données.
Pour les Data Lakes
Gouvernance rigoureuse : Instaurez un cadre strict de gouvernance pour maintenir l’intégrité des données et clarifier l’accès et l’utilisation des données.
Qualité : Intégrez des processus systématiques pour le nettoyage et la validation des données, garantissant leur fiabilité pour l’analyse et la prise de décision dans la durée.
Catalogage : Adoptez des solutions de Data Catalog pour faciliter la recherche et l’utilisation des données stockées, transformant le data lake en un réservoir de connaissances exploitables.
Pour les Data Warehouses
Maintenance proactive : Menez des audits réguliers pour préserver les performances et adapter la structure aux besoins évolutifs de l’entreprise.
Évolution : Faites évoluer votre écosystème data avec prudence, en intégrant des innovations technologiques pour améliorer les capacités analytiques et opérationnelles.
Compétences à: Investissez dans la formation des équipes pour qu’elles restent à la pointe de la technologie et puissent tirer le meilleur parti de l’infrastructure de données.
Le débat entre data lake et data warehouse ne se réduit pas à un simple choix technologique ; il s’agit d’une décision stratégique qui reflète la vision, la culture et les objectifs de votre entreprise en matière de création de valeur à partir de l’exploitation des données. Alors qu’un data lake offre une palette vaste et flexible pour l’agrégation de données brutes propices à l’exploration et à l’innovation analytique ; un data warehouse apporte une structure organisée et performante pour le reporting et les analyses décisionnelles.
Votre choix dépend en somme des objectifs spécifiques de votre entreprise, des exigences en matière de gouvernance des données, de la variété et du volume des données, ainsi que de la rapidité avec laquelle l’information doit être convertie en action. Le data lake convient aux organisations qui aspirent à une exploration de données libre et sans contrainte, où les potentiels de l’IA et du machine learning peuvent être pleinement exploités. Inversement, le data warehouse est la solution pour ceux qui cherchent à solidifier leur Business Intelligence avec des données cohérentes et fiables.
Les data lakes et data warehouses ne sont pas mutuellement exclusifs et peuvent tout à fait coexister, se complétant mutuellement au sein d’une architecture de données bien conçue, permettant ainsi aux organisations de tirer le meilleur parti des deux mondes.
Data Governance
Mesurer la maturité et la performance de la gouvernance
0 commentaires
Episode 8
Entre la montée en puissance de l’architecture Data Mesh, la pression croissante de la conformité réglementaire (RGPD, Data Act, IA Act, etc.) et la multiplication des data products, les DSI et CDO doivent dépasser une gouvernance des données théorique pour adopter une gouvernance active, mesurable et scalable. Chez Smartpoint, nous vous conseillons de choisir un modèle de maturité adapté (DAMA-DMBOK, DCAM, CMMI…), de définir des KPI de gouvernance actionnables (qualité, traçabilité, métadonnées, rôles, adoption des outils) et de construire une feuille de route progressive sur deux à trois ans. Dans cet épisode 8, Smartpoint partage ses recommandations pour piloter une gouvernance des données alignée sur les enjeux métiers et technologiques. alignée avec les enjeux réels de l’entreprise et des métiers.
Comment mesurer l’efficacité de votre gouvernance des données ?
Alors que les architectures sont de plus en plus distribuée comme le Data Mesh, que la conformité réglementaire se durcit (RGPD, Data Act, IA Act) et que les les data products se multiplient dans votre SI, vous devez mesurer l’efficacité et la maturité de votre gouvernance des données.
Mais que mesure t-on exactement ? La performance de la gouvernance ne se résume pas en un reporting ou à un audit technique ponctuel. Elle s’analyse avec des indicateurs clés de pilotage (KPI et KRIs actionables), une lecture croisée des rôles opérationnels (CDO, Data Steward, Data Owner) et le suivi d’une feuille de route évolutive alignée sur des cas d’usages métiers réels.
Choisir un modèle de maturité comme le DAMA-DMBOK, DCAM ou encore CMMI, vous permet de positionner votre organisation, domaine par domaine : qualité des données, documentation, métadonnées, traçabilité (lineage), outillage. C’est pour Smartpoint, un prérequis dépasser une gouvernance déclarative bien souvent inefficace à une gouvernance active, mesurable, scalable.
Quels modèles de maturité choisir pour structurer votre gouvernance des données ?
Piloter la gouvernance sans modèle de maturité, c’est comme debugger sans logs.
Luc Doladille, Directeur Conseil, Smartpoint
Pour évaluer la maturité de votre gouvernance des données, nous vous conseillons de vous appuyer sur un modèle structurant, reconnu et adaptableà votre contexte métier et à votre écosystème technologique. Ces maturity models permettent d’objectiver les progrès, de cibler les axes d’amélioration et de comparer les niveaux de maturité entre domaines : qualité des données, traçabilité, métadonnées, cycle de vie, rôles ou encore outils/
Parmi les référentiels les plus utilisés, on retrouve :
le DCAM (Data Management Capability Assessment Model), très implanté dans la banque/assurance
le DMM / CMMI, modèle de maturité très répandu au sein des grandes DSI
le DAMA-DMBOK, référence mondiale en gestion des données
Citons également la norme ISO/IEC 38505qui pose un cadre de gouvernance des données au sein des systèmes d’information. Elle se révèle pertinente dans les environnements soumis à la certification ou à la conformité réglementaire (RGPD, DORA, souveraineté numérique, sécurité).
L’objectif n’est pas de “coller” à un modèle pour le principe mais d’aligner cette évaluation sur votre stratégie data, votre réalité opérationnelle (Data Mesh, gouvernance distribuée, data products) et vos obligations métiers / règlementaires. Ce cadre vous permettra de prioriser les chantiers et de construire une feuille de route de gouvernance scalable sur 2–3 ans.
Structuré, orienté finance, conformité & stratégie data
8 domaines – 5 niveaux
Banque, assurance, projets réglementaires
DMM / CMMI (Data Maturity Model)
CMMI Institute
Gouvernance IT étendue, amélioration continue
5 niveaux (Ad hoc → Optimisé)
Grandes DSI, secteur public
COBIT
ISACA
Alignement SI-métier, pilotage stratégique
5 niveaux + framework de contrôle
Gouvernance IT, audit, pilotage SI
DAMA-DMBOK
DAMA International
Référence data management, 11 disciplines
Modèle adaptable
CDO, data management global
ISO/IEC 38505
ISO / IEC
Norme formelle de gouvernance data dans le SI
Normatif, non gradué
Certification, conformité RGPD / DORA
Nos recommandations ?
Choisissez un ou deux modèles au maximum parmi ceux les plus adaptés à votre secteur d’activité, votre niveau de maturité, votre mode de pilotage (agilité, centralisé, distribué) et vous contraintes règlementaires.
Quels KPI suivre pour mesurer l’efficacité de votre gouvernance des données ?
Mettre en œuvre une gouvernance des données efficace, ce n’était pas une simple définition de rôles ni l’affichage de chartes. Il faut être en capacités de la piloter dans la durée avec des indicateurs précis et activables.
Ces Governance KPI permettent d’objectiver les avancées, de prioriser les efforts et d’aligner les actions avec les enjeux métiers. Ils fluidifient aussi le dialogue entre le CDO, la DSI, les fonctions métiers et les parties prenantes réglementaires.
1. Mesurer la qualité des données
Des indicateurs comme le taux d’erreurs, la complétude des jeux de données, le nombre de valeurs corrigées ou un Data Quality Index (DQI) permettent de suivre la fiabilité des données exposées aux métiers. Ces mesures sont souvent contextualisées par domaine fonctionnel (ex : données clients en CRM, données financières pour la conformité).
2. Suivre la documentation et les métadonnées
La documentation des données, des traitements et des règles métiers est clé dans une gouvernance « by design ». Vous pouvez suivre le taux de tables documentées, la présence de glossaires ou encore la couverture des métadonnées dans les outils data catalog comme DataGalaxy, Zeenea our encore Alation).
3. Piloter la traçabilité et le cycle de vie des données
Le data lineage devient indispensable dans les architectures de données modernes. Il permet de comprendre d’où viennent les données, comment elles sont transformées et qui les utilise. Des indicateurs comme le taux de datasets avec lineage documenté, le nombre de versions tracées, ou le respect des règles d’archivage / suppression contribuent à renforcer la gouvernabilité.
4. Évaluer la conformité et la maîtrise des risques
Dans un contexte réglementaire qui ne cesse de renforcer (RGPD, DORA, souveraineté numérique), il est essentiel de suivre les taux de couverture RGPD, le nombre de traitements mappés, les incidents liés à la sécurité des données ou encore les résultats d’audits internes. Ces indicateurs permettent de démontrer la conformité mais aussi d’anticiper les zones à risque.
5. Suivre l’activation des rôles de gouvernance
La performance d’un modèle distribué se mesure aussi par l’implication des acteurs :
Combien de data products ont un Data Owner désigné ?
Quel est le niveau d’engagement des métiers dans les comités Data ?
Les data stewards de domaine sont-ils réellement actifs ?
Ces indicateurs permettent d’éviter que la gouvernance reste uniquement sur le papier.
6. Vérifier l’adoption des outils de gouvernance
Une gouvernance efficace repose sur des outils, certes, mais surtout des outils utilisés ! Nous ne comptons plus chez Smartpoint des projets de gouvernance des données outillés mais abandonnés car jamais adoptées dans la durée. Vous pouvez monitorer le nombre d’utilisateurs actifs du data catalog, le temps moyen d’accès à une donnée ou encore le nombre de demandes liées à la gouvernance (accès, corrections, tickets…). C’est souvent grace à ces données que l’on détecte les freins d’adoption ou les besoins d’accompagnement.
Ce que nous recommandons chez Smartpoint
Commencez simplement en identifiant quelques indicateurs clés en lien direct avec vos enjeux actuels, il sera toujours temps d’en rajouter par la suite. Appuyez-vous sur les outils déjà en place au sein de votre stack Data (catalog, observabilité, lineage) pour automatiser la collecte. Et surtout, intégrez ces KPI dans tous vos rituels (revues, comités, sprints, etc.) pour qu’ils deviennent réellement pilotables et adoptés par tous.
Comment concevoir une roadmap gouvernance des données sur 2 à 3 ans ?
Déployer une gouvernance des données efficace à l’échelle de l’entreprise ne s’improvise. Cela nécessite une trajectoire claire, réaliste et alignée avec la stratégie data globale, les priorités métier et les évolutions prévues du système d’information.
Une feuille de route de gouvernance sur deux à trois ans permet de structurer cette transformation sans tomber dans l’excès de planification ou l’illusion du “big bang”.
Une démarche progressive, alignée et gouvernable
Le premier prérequi d’une roadmap gouvernance des données efficace, c’est sa capacité à conjuguer vision stratégique et capacité opérationnelle. Elle doit donner du sens (alignement avec la stratégie data, les exigences réglementaires et les transformations technologiques telles que le Data Mesh) et offrir une séquence d’actions concrètes, pilotables et mesurables.
Chez Smartpoint, nous recommandons une trajectoire progressive, en trois phases structurantes : initier, étendre, ancrer.
1. Initier : commencer petit mais structuré
Plutôt que de viser une gouvernance globale dès le départ, nous vous recommandons de commencer par un périmètre pilote : un domaine métier prioritaire, des données critiques, des sponsors engagés. Ce premier terrain d’expérimentation va vous permettre de poser les bases : désigner les rôles clés (Data Owner, Data Steward, Référent Métier), tester un premier modèle de gouvernance distribué, qualifier les premiers KPIs et surtout outiller la démarche avec un data catalog ou une solution de metadata management adaptée. Cette première boucle permet d’éprouver concrètement les pratiques et de démontrer rapidement la valeur de la gouvernance data auprès des parties prenantes.
2. Étendre : industrialiser ce qui fonctionne
À partir des retours d’expérience terrain, la gouvernance peut ensuite s’élargir à d’autres domaines en prenant en compte le niveau de maturité, les enjeux métier et la capacité d’absorption des équipes. C’est le moment d’harmoniser les rôles, de mettre en place des rituels transverses (revues de gouvernance, comités de pilotage, sprints data), d’intégrer des outils de traçabilité (data lineage) ou d’observabilité et de consolider les premiers KPI de gouvernance : qualité des données, complétude des métadonnées, indicateurs d’usage ou de conformité.
La finalité n’est pas d’imposer un modèle figé mais de faire émerger une gouvernance vivante, adaptée à la culture et à l’organisation avec des garde-fous clairs et partagés.
3. Ancrer : aligner la gouvernance sur les transformations SI
Une feuille de route scalable doit s’intégrer dans la transformation planifiée du système d’information comme la migration dans le cloud, le déploiement de plateformes data modernes, l’adoption du modèle Data Mesh ou encore la montée en puissance des Data Products.
La gouvernance des données devient alors une capacité d’alignement entre les domaines, les technologies, la conformité réglementaire et les usages réels. Elle se pilote avec des indicateurs structurants, mais évolutifs, et repose sur une infrastructure outillée, observable, et adoptée.
La performance de la gouvernance des données se mesure alors par sa capacité à soutenir l’innovation, à limiter les risques et à valoriser les actifs data dans la durée.
Bonnes pratiques observées chez nos clients
Mesurer peu … mais bien : choisissez 5 à 10 KPI clés maximum mais les maintenir dans la durée
inclure métiers & IT dans la revue des indicateurs
Valoriser les résultats pour renforcer l’engagement
Outiller le suivi : dashboards, rapports automatisés, documentation intégrée
Ne pas figer les modèles : ajuster la grille de maturité aux priorités stratégiques
Chez Smartpoint, nous accompagnons nos clients dans la définition et l’exécution de leurs trajectoires de gouvernance, à leur rythme, selon leur maturité, et toujours en lien avec les réalités terrain. Gouverner, c’est créer les conditions pour que la donnée soit utile, utilisable et utilisée.
Besoins d’évaluer votre maturité en data governance ? Smartpoint vous accompagne dans de choix de votre modèle de gouvernance (CMMI, DCAM, ISO/IEC 38505…), la définition d’indicateurs sur-mesure, le choix des outils et l’élaboration d’une feuille de route efficace. Contactez-nous.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Questions fréquentes
Qu’est-ce qu’un modèle de maturité en gouvernance des données ?
Un modèle de maturité en gouvernance des données permet d’évaluer le niveau de structuration, de qualité et de pilotage de vos pratiques data. Il aide à identifier les axes d’amélioration pour construire une gouvernance scalable.
Quels sont les modèles de référence en gouvernance des données ?
DCAM, très répandu dans la finance, DMM / CMMI, pour les grandes DSI, DAMA-DMBOK, référence globale, COBIT pour la gouvernance IT, La norme ISO/IEC 38505 pour les environnements certifiés.
Quels KPI suivre pour évaluer la gouvernance des données ?
Parmi les plus utilisés : Taux de complétude des métadonnées, Data Quality Index (DQI), taux de datasets documentés, traçabilité (data lineage), indicateurs de conformité RGPD, adoption des rôles (Data Owner, Steward), utilisation du data catalog.
Quelle est la différence entre gouvernance centralisée et distribuée ?
La gouvernance centralisée repose sur un pilotage unique, souvent IT. La gouvernance distribuée (comme avec le Data Mesh) délègue la responsabilité aux domaines métiers via des rôles comme Data Product Owner et Data Steward.
Pourquoi utiliser un modèle comme DCAM ou DAMA ?
Ces modèles vous donnent une grille de lecture partagée pour piloter votre gouvernance. Ils permettent de comparer les niveaux de maturité, prioriser les actions et structurer une trajectoire réaliste sur 2 à 3 ans.
Quels outils pour le monitoring de la gouvernance des données ?
Des outils comme DataGalaxy, Zeenea, Alation, Collibra ou Great Expectations permettent de documenter, tracer, et suivre la gouvernance des données en continu. Ils renforcent l’autonomie des équipes tout en assurant la conformité.