Architecture
En 2025, sous l’effet de l’explosion des volumes de données et de l’industrialisation des workloads d’intelligence artificielle (IA), les Directeurs des Systèmes d’Information (DSI) doivent repenser en profondeur leurs architectures data.
Scalabilité, gouvernance, souveraineté et maîtrise des coûts sont les maîtres mots et cela demande de revoir les choix technologiques.
Popularisation des architectures hybrides et du Data Lakehouse
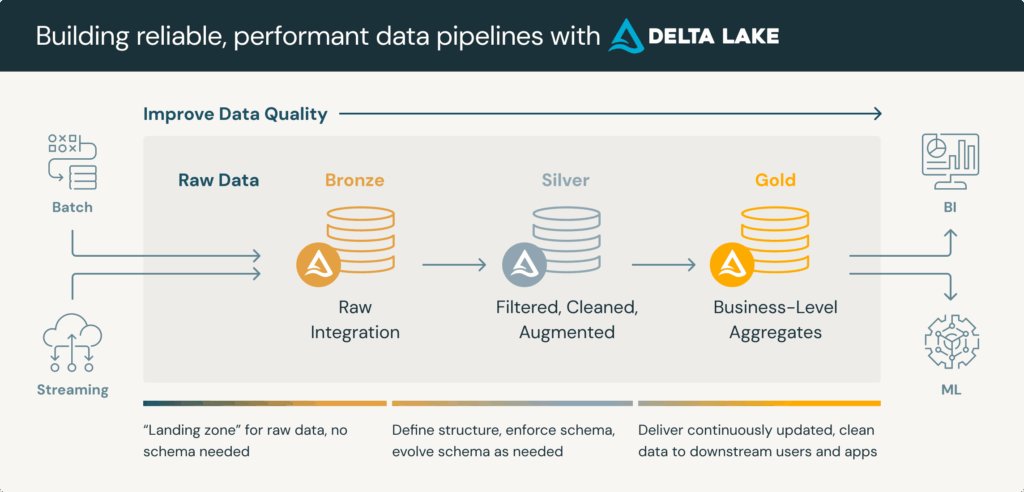
Les data warehouses traditionnels ont atteint leurs limites et une nouvelle architecture tend à s’imposer : le Data Lakehouse.
Offrant la flexibilité des data lakes et la performance analytique des data warehouses, ce modèle d’architecture permet de stocker, gérer et analyser données brutes, semi-structurées et structurées dans une seule et même plateforme.
Selon plusieurs études de marché, plus de la moitié des charges analytiques devraient être exécutées à court terme sur des architectures lakehouse en raison de leur scalabilité quasi-infinie, leur capacité à unifier stockage et analytique, et leur participation à une forte réduction des coûts.
En simplifiant les pipelines de traitement des données et en rendant enfin possible l’analyse self-service, le lakehouse devient le modèle de référence pour les grandes entreprises souhaitant moderniser leur patrimoine data en s’appuyant sur une architecture data scalable et souveraine.
Adoption des formats de tables ouverts
Les formats ouverts comme Apache Iceberg, Delta Lake et Apache Hudi s’imposent comme des standards dans les architectures data modernes.
Leur adoption s’explique par plusieurs avantages qui répondent aux nouvelles exigences des entreprises en matière d’agilité, de souveraineté et de gouvernance.
Déjà, ces formats offrent une meilleure interopérabilité. Ils permettent d’utiliser plusieurs moteurs analytiques (DuckDB, Trino, Spark, etc.) sans dépendance technologique, favorisant ainsi la flexibilité dans un environnement multi-cloud et hybride.
Ensuite, ils permettent une souveraineté renforcée sur les données. En s’appuyant sur des standards ouverts, les entreprises conservent la maîtrise totale de leur infrastructure et de leurs choix technologiques, limitant le risque de vendor lock-in souvent associé aux solutions fermées.
Enfin, ces formats assurent une flexibilité et une évolutivité optimales. Ils permettent une évolution dynamique des schémas de données, une gestion fine des suppressions (essentielle pour la conformité RGPD) ainsi qu’une gouvernance avancée grâce à des métadonnées enrichies.
Apache Iceberg tend à devenir un incontournable des plateformes modernes grâce à :
- la suppression au niveau ligne (indispensable pour le RGPD et l’AI Act),
- la gestion native de l’évolution des schémas,
- et la compatibilité avec les data catalogs (AWS Glue, Snowflake, Databricks).
Les principaux cloud providers intègrent désormais nativement ces formats ouverts, facilitant l’exploitation des données avec des moteurs comme DuckDB, Trino ou Polars.
Gouvernance, sécurité et conformité au cœur des architectures data modernes
Le renforcement des exigences réglementaires (RGPD, AI Act) oblige les entreprises à adopter une approche beaucoup plus rigoureuse dans la gouvernance de leurs données.
La simple gestion des données ne suffit plus. Il s’agit aujourd’hui de garantir une traçabilité complète, une sécurité renforcée et une conformité stricte aux normes en vigueur.
Les plateformes lakehouse modernes apportent des solutions en intégrant nativement des fonctionnalités avancées de gouvernance. Elles permettent notamment de tracer précisément les accès et les manipulations des données, de chiffrer et protéger les informations sensibles, d’appliquer des politiques granulaires de contrôle d’accès, et de répondre de manière efficace au droit à l’oubli imposé par la réglementation européenne.
Grâce à l’utilisation de formats ouverts (comme Apache Iceberg ou Delta Lake) associés à des outils de catalogage avancé, la gouvernance ne représente plus un frein à l’innovation.
Au contraire, elle devient un moteur d’agilité, capable de sécuriser les environnements data tout en soutenant les initiatives d’IA, de machine learning et de valorisation des données à grande échelle.
Réduction du Vendor Lock-in, un impératif
Échapper à l’enfermement technologique est devenu une priorité.
Face aux risques liés aux solutions propriétaires, les architectures hybrides et les formats ouverts s’imposent comme étant la meilleure réponse pour conserver une agilité technologique durable.
En adoptant des standards ouverts, les organisations peuvent intégrer rapidement des avancées majeures telles que :
- l’intelligence artificielle générative,
- les nouvelles approches de machine learning,
- ainsi que des technologies émergentes comme la blockchain, sans avoir à refondre entièrement leur infrastructure existante.
Cette capacité d’intégration rapide, sans dépendance imposée par un fournisseur unique, devient un véritable avantage concurrentiel à l’ère du temps réel et de l’IA ubiquitaire.
Elle permet aux entreprises de rester à la pointe de l’innovation tout en sécurisant une trajectoire de transformation numérique soutenue par une architecture data scalable et souveraine.

Qu’est-ce que l’IA ubiquitaire ?
L’IA ubiquitaire désigne l’intégration généralisée et souvent invisible de l’intelligence artificielle dans l’ensemble des processus, services et infrastructures d’une organisation.
À l’ère du temps réel, l’IA n’est plus confinée à des projets pilotes ou à des outils isolés : elle optimise en continu la prise de décision, la gestion des ressources, la relation client, la cybersécurité et bien plus encore.
Pourquoi c’est stratégique ?
Pour accompagner cette transformation, les entreprises doivent bâtir des architectures scalables, flexibles et gouvernées, capables de traiter de grands volumes de données tout en garantissant la sécurité, la conformité et l’interopérabilité nécessaires à l’adoption massive de l’IA.
Interopérabilité et pilotage par la gouvernance
Les DSI doivent avoir une roadmap claire pour bâtir des architectures data modernes et résilientes.
Le premier objectif est de concevoir des plateformes interopérables, capables d’orchestrer de manière fluide plusieurs moteurs analytiques, formats de données et environnements cloud. Cette approche multi-technologies offre la flexibilité nécessaire pour s’adapter aux besoins métiers en constante évolution.
Le second objectif consiste à piloter la donnée par la gouvernance. Il ne s’agit plus seulement de stocker ou traiter la donnée, mais de garantir un usage conforme aux réglementations, tout en maximisant sa valeur pour l’innovation. La gouvernance devient ainsi un levier stratégique pour concilier agilité, conformité et souveraineté.
Enfin, les DSI doivent préparer leur infrastructure à accueillir l’IA générative de manière sécurisée et maîtrisée. Cela implique d’intégrer l’IA sans compromettre la sécurité des systèmes ni perdre le contrôle budgétaire, tout en assurant l’équilibre entre innovation technologique et rigueur opérationnelle.
Quel nouveau standard des architectures Data en 2025 ?
Les architectures hybrides, l’adoption massive des formats ouverts, les moteurs analytiques flexibles et une gouvernance avancée s’imposent comme le nouveau standard pour une architecture data scalable et souveraine.
Souveraineté, agilité, réduction des coûts et valorisation accélérée de la donnée sont les quatre piliers de cette nouvelle génération d’architectures Data.
Chez Smartpoint, nous accompagnons les DSI et les Responsables Data dans la conception de plateformes évolutives, résilientes et prêtes à relever les défis technologiques de demain.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels,
Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Sources :
https://www.itpublic.fr/dossiers-thematiques/au-dela-du-buzzword/au-dela-du-buzzword-data-lakehouse