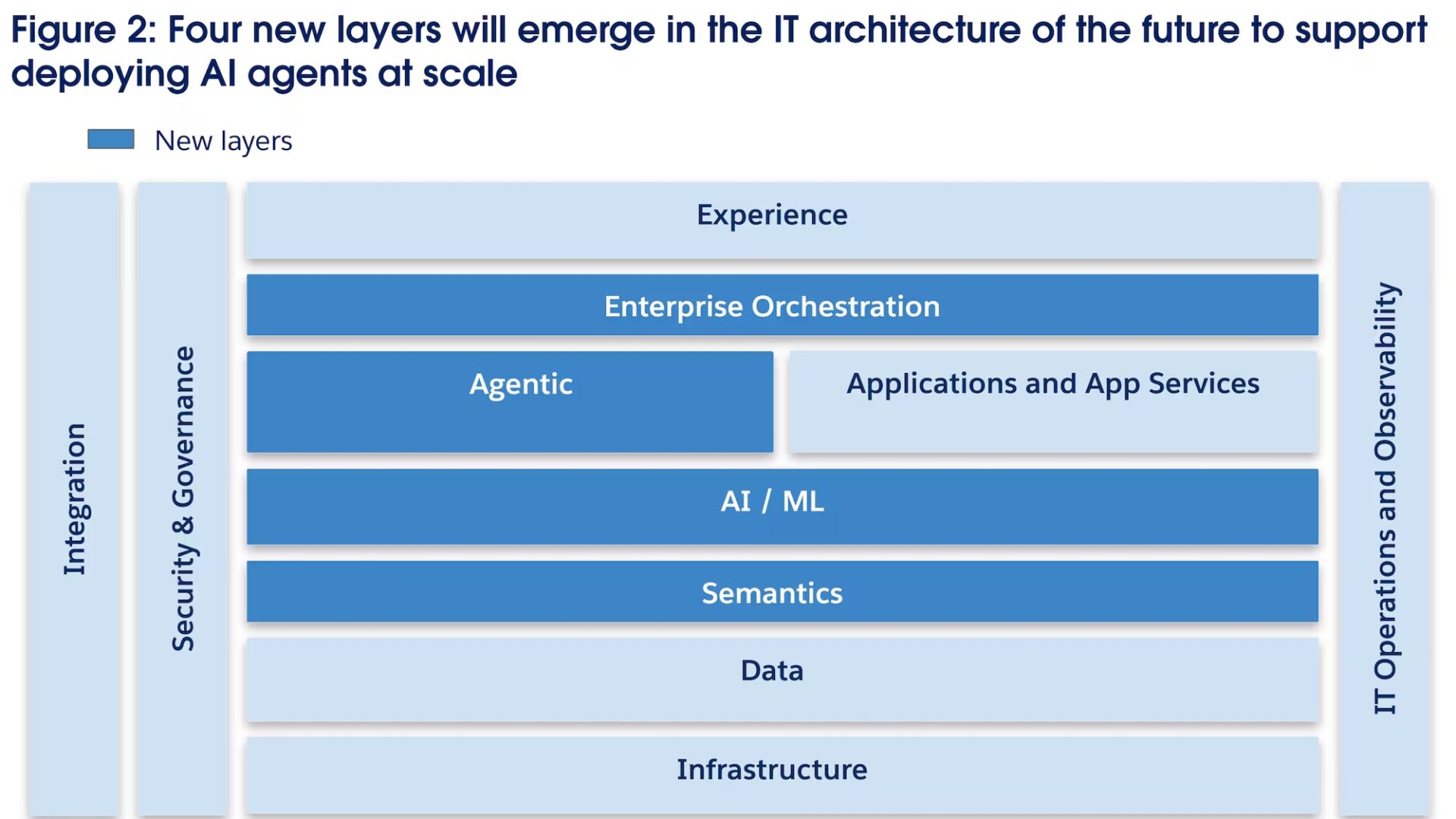
Architecture
Le faut débat des architectures data
Il y a encore quelques années, le débat fait rage dans toutes les comités d’architecture. D’un côté, les gardiens du temple du data warehouse, reconnu pour sa stabilité, sa gouvernance et sa fiabilité De l’autre, les évangélistes du lakehouse portés par son agilité, sa scalabilité et sa compatibilité avec l’IA. Depuis, les lignes ont bougé. Non pas qu’un camp ait eu raison de l’autre mais parce que les équipes terrain ont constaté que les deux approches n’étaient pas en concurrence mais bien complémentaires. Les deux se conjuquent parfaitement dans un SI Data performant.
Nous vous proposons dans cet article de partager nos retours d’expérience sur ce que nous constatons au quotidien chez Smartpoint sur les différents projets de modernisation de plateformes data que nous menons pour des DSI et des CDO qui doivent arbitrer dans des contextes généralement très contraints.
Le data warehouse, cet incontournable du SI Data
Le data warehouse a mauvaise réputation, jugé trop rigide, trop lent, trop cher. Cette caricature a la vie dure alors que le datawarehouse a au contraire su batir sa légitimité sur la confiance dans la durée.
C’est le Datawarehouse qui est derrière le dashboard P&L du contrôleur de gestion, le rapport réglementaire Bâle 4 de l’Analyste Risques ou encore la clôture des comptes trimestriels. Son atout coeur ? La reproductibilité du résultat.
Le modèle schema on write, qui impose de définir la structure avant d’ingérer la donnée, est certes une forte contrainte mais elle oblige les équipes à documenter, à modéliser et à trancher sur la sémantique métier avant. C’est coûteux en amont mais c’est ce qui permet à un KPI d’avoir la même signification pour tout le monde dans l’entreprise.
D’ailleurs plateformes cloud-native modernes, comme Snowflake, BigQuery, Azure Synapse ou Redshift, ne s’y sont pas trompées et ont dépoussiéré le datawarehouse. Séparation compute/storage, scalabilité élastique, support du semi-structuré (JSON, Parquet), connecteurs natifs vers les outils BI et ML; le datawarehouse 2026 n’a plus grand-chose à voir avec les appliances Teradata d’il y a quinze ans !
Pour la BI critique, le reporting financier, la conformité réglementaire et tout contexte où la donnée doit être auditée, certifiée, gouvernée; le data warehouse reste pour Smartpoint l’architecture de référence.
— Smartpoint · Architecture Data & IALe lakehouse, le socle de la data moderne
Avant le lakehouse, l’architecture Data était vécue comme une épreuve … Two-stack hell : un datalake pour ingérer sans contrainte (S3/ADLS, tout format, tout schéma) et un warehouse pour la BI. Entre les deux, un no man’s land de jobs Spark mal versionnés, de schémas qui driftent et de pipelines qui tombent en pleine nuit parce qu’un upstream a étrangement changé un type de colonne. La double ingestion et le double compute faisaient dériver les coûts sans aucune valeur ajoutée. Sans data contract formalisé entre les deux mondes, chaque modification en amont était une véritable bombe à retardement pour les pipelines en aval.
Conceptualisé et popularisé notamment par Databricks avec Delta Lake, puis standardisé via Apache Iceberg et Apache Hudi; Le lakehouse s’est imposé comme la réponse architecturale la plus solide après des années de recalculs, d’engagements de service non tenus et de dette technique accumulée à coups de patchs. Le principe consiste à poser une couche de gestion transactionnelle (garanties ACID, versioning, time travel) directement sur un stockage objet économique comme S3, ADLS ou GCS, puis à exposer au-dessus une couche SQL pour l’analytique et une autre Python/Spark pour les workloads machine learning.
Nos équipes de data engineers ont tout se suite étaient séduites par le modèle schema on read qui consiste à ingérer d’abord et à structurez ensuite. L’inverse du datawarehouse, plus besoin de modéliser parfaitement dès le départ. La donnée brute atterrit dans la zone bronze, elle est nettoyée en silver, puis agrégée et enrichie en gold. C’est l’architecture médaillon et elle est devenue le cadre de référence pour la plupart des plateformes data modernes.
Mais le vrai Game Changer du lakehouse, c’est son rapport natif à l’IA. En effet, nos équipes de data scientists et de ML engineers opèrent dans l’écosystème Python (Scikit-learn, PyTorch, HuggingFace, Pandas) et ils ont besoin d’accéder à de la donnée brute, à du feature store et à des volumes massifs pour l’entraînement. Le lakehouse met ces capacités à disposition nativement alors que le datawarehouse contraignait les équipes à multiplier les exports, les conversions et autres compromis.
En bref, si votre roadmap Data 2026 inclut du ML, de la GenAI, du RAG ou de l’analytique temps réel (et c’est plus que probable !), le lakehouse s’impose clairement.
Le comparatif entre Data Warehouse et Data Lakehouse
Voici un tableau récapitulatif des différents critères de comparaison entre ces deux architectures data par nos architectes Data.
| Critères | Data Warehouse | Data Lakehouse |
|---|---|---|
| Structure des données | Schema on write, rigide mais solide | Schema on read, flexible mais demande de la discipline |
| Time to ingest | Long (modélisation requise) | Court (ingestion brute possible) |
| Performance analytique BI | Excellente nativement | Bonne à très bonne selon l’optimisation (Z-Order, partitioning) |
| Workloads ML / IA | Limité, nécessite des exports | Natif avec accès direct depuis Spark, Python, notebooks |
| Coût infrastructure | Élevé à très élevé (compute + storage couplés) | Optimisable (stockage objet cheap + compute élastique) |
| Gouvernance | Mature : lineage, RBAC, audit nativement | De mieux en mieux : Unity Catalog, Iceberg REST mais est à outiller |
| Conformité RGPD / AI Act | Outils matures | Nécessite une couche de gouvernance dédiée |
| Évolutivité | Difficile sans refonte de modèle | Haute : Ajout de sources sans impact majeur |
| Maturité de l’écosystème | Très mature | Mature et en croissance rapide |
Ce tableau ne fait pas foi et nous sommes amenés à challenger ces critères dans chaque contexte client : Cas d’usages prioritaires, régulations du secteur d’activité, SI Data legacy, maturité des équipes. Un travail d’arbitrage architectural nécessite un cadrage et ne se résume jamais en un simple benchmark même si cela donne des repères.
L’architecture médaillon, le meilleur des mondes
Nous avons déjà prôné l’architecture Médaillon (ou medallion architecture) à de nombreuses reprises (Architecture Data : le modèle Médaillon, la solution à la dette technique ?), elle est devenue le modèle de référence pour organiser un lakehouse et par extension, pour structurer la transition entre ingestion brute et analytique gouvernée.
Le principe est simplissime et redoutablement efficace :
- Zone Bronze : La donnée brute telle qu’elle est ingérée. Logs applicatifs, flux Kafka, extractions API, fichiers CSV mal formatés. Pas de transformation, tout est conservé et c’est la source of truth de l’historique.
- Zone Silver : La donnée nettoyée avec déduplication effectuée, typage homogénéisé et règles de qualité appliquées. C’est la zone où on commence à faire confiance à la donnée
- Zone Gold : La donnée agrégée, enrichie, modélisée pour un usage métier spécifique. C’est dans cette zone qu’on retrouve les datasets prêts pour le reporting BI, les feature stores ML ou les RAG pipelines GenAI.
Ce qui est intéressant dans le modèle Médaillon, c’est qu’il réconcilie l’approche du Lakehouse et cette du Datawhare. La zone gold se comporte comme un datamart : gouvernée, structurée, fiable. Les zones bronze et silver conservent la flexibilité du datalake. Et l’ensemble est dans le même système Data avec un seul catalogue et un seul plan de gouvernance des données.
Chez Smartpoint, nous implémentons ce modèle architectural avec Delta Lake sur Databricks, Apache Iceberg sur des stacks AWS ou GCP ou encore dbt pour orchestrer les transformations silver vers gold sur Snowflake ou BigQuery. Le choix de la technologie est finalement assez secondaire, c’est davantage la discipline d’implémentation qui fait la différence dans ce type de projet.
Extrait de cas d’usages d’arbitrage d’architectures Data
Cas 1
Reporting financier & conformité réglementaire
Choix Data Warehouse
Un grand bancaire français devait produire ses reportings prudentiels (COREP, FINREP), ses arrêtés comptables et ses tableaux de bord risques. La donnée devait être certifiée, traçable et reproductible. Le choix architectural s’est porté sur un data warehouse Snowflake. Le lakehouse alimente le data warehouse en amont (ingestion, nettoyage) mais c’est le data warehouse qui certifie.
Cas 2
IA générative & ML industrialisé
Choix Lakehouse
Notre client dans le retail souhaitait entraîner des modèles de prévision de la demande, déployer un moteur de recommandation produit et expérimenter un assistant GenAI pour ses équipes merchandising. Il avait besoin d’accéder à des téraoctets de données historiques, d’un feature store partagé et d’un environnement d’expérimentation rapide. Le choix s’est porté sur le lakehouse natif de Databricks.
Cas 3
Modernisation d’un SI Data hérité
Architecture hybride médaillon
C’est le cas le plus fréquent que nous rencontrons. Notre client, une entreprise industrielle, exploitait un entrepôt Teradata depuis des années : flux batch nocturnes, datamarts métiers et dette technique accumulée. La migration full-replace vers un lakehouse était trop risquée. Nous avons migré progressivement vers une architecture médaillon (lakehouse en bronze et silver) tout en maintenant le data warehouse existant pour la zone gold et le reporting, afin de préserver la confiance métier. Moderniser le SI Data, oui … mais de manière incrémentale.
Modernisation de la BI et du SI Data : réduire la dette de la plateforme décisionnelle pour alimenter l’IA
Comment Smartpoint accompagne la modernisation de votre plateforme Data
Chez Smartpoint, nous sommes agnostiques. Nos Architectes Data / IA vous aident à choisir la bonne solution architecturale en fonction de votre réalité opérationnelle : Stack existante, roadmap Data / IA, maturité équipe, contraintes de gouvernance, compliance, etc.
Nos prestations de service pour moderniser votre plateforme Data :
Consulting & Design
Nous commençons par un audit de la plateforme data existante : sources, volumétrie, usages BI, projets ML en cours ou planifiés, maturité DataOps. Puis, nous co-construisons la cible architecturale avec vos équipes et les sponsors métiers.
Build & Automate
Nous intégrons la plateforme data cible : ingestion (Kafka, Fivetran, custom), transformation (dbt, Spark, Azure Data Factory), stockage (Delta Lake, Iceberg, BigQuery), orchestration (Airflow, Dagster), observabilité (Great Expectations, Monte Carlo).
Nous appliquons les pratiques DataOps dès la conception : CI/CD, tests de qualité, lineage automatique.
Evolve & Scale
Nous accompagnons nos clients dans l’évolution de leur plateforme data avec l’intégration de nouvelles sources, de nouveaux cas d’usage ML, des montées en charge ou encore l’intégration des workloads GenAI (RAG, fine-tuning, LLMOps).
Run & Monitor
Pour les clients qui ne souhaitent externaliser le run, nous assurons la supervision opérationnelle de la plateforme data : SLA, alerting, gestion des incidents, optimisation des coûts cloud. Nous proposons d’ailleurs une offre experte à Tunis dans notre centre de services.
Notre différence tient dans notre positionnement : Nous sommes un pur player Data & IA, basé à Paris, avec vingt ans d’expérience sur des projets de modernisation complexes dans des secteurs régulés. Et c’est cette expertise pointue et spécialisée dont nos clients ont besoin quand ils sont confrontés à ces enjeux et veulent sécuriser leurs roadmap data & IA.
Alors, Lakehouse ou datawarehouse ?
Dans les faits, ce n’est pas une bonne question ! Celle que nous posons aux DSI ou CDO que nous rencontrons, est « Quelle est la nature de votre donnée, qui sont vos utilisateurs et quelle est votre ambition IA ? »
Si votre priorité est la confiance métier sur du reporting structuré alors le datawarehouse reste le bon choix. Si votre priorité est la vitesse d’ingestion et les workloads ML, le lakehouse est une bonne fondation. Si vous devez faire les deux, et c’est souvent le cas, l’architecture médaillon vous donnera le cadre pour y parvenir sans remettre en question votre plateforme à chaque projet.
L’architecture data n’est pas tant un chantier technologique qu’un levier d’industrialisation de l’IA au sein de l’organisation. Et comme tout levier, son efficacité tient entièrement à la qualité de son calibrage.
Vous êtes DSI ou CDO et vous réfléchissez à la modernisation de votre plateforme data ?
Smartpoint est une ESN pure player Data & IA basée à Paris, accompagnant DSI et CDO dans la conception et la mise en œuvre de plateformes data cloud-native depuis 2006. Agréée CIR.