Architecture
Après une année consacrée aux expérimentations IA, nous constatons chez Smartpoint que la mise en production suscite de nouvelles préoccupations. De plus en plus de DSI (voire le Comex) se posent la question de la souveraineté des données. L’IA, ce n’est pas qu’une question de performance … mais aussi de territoire, de dépendance et de responsabilité.
Risques d’exposition des données, forte dépendance vis-à-vis des acteurs américains (vendor lock-in) et contexte géopolitique instable, tous les facteurs sont réunis. Le temps est venu de se poser la question de comment concevoir une plateforme IA souveraine capable d’opérer un RAG en production.
Mettre en production l’IA générative sans audit possible et avec des coûts non maîtrisés n’est pas une option viable.
« La souveraineté IA est liée au contrat d’exploitation : qui possède vos clés, où sont hébergés vos modèles et sous quelle juridiction tombent vos données » souligne Luc Doladille, Directeur conseil data & IA,
Pourquoi un RAG souverain ?
Le passage à l’IA agentique et le déploiement d’un copilote IA privé en entreprise soulèvent des vulnérabilités critiques que les solutions SaaS « boîte noire » ne peuvent pas couvrir. Pour une direction DSI, l’enjeu n’est pas d’accéder à un modèle performant mais de garantir la maîtrise du cycle de vie des données.
Le système doit être exploitable, auditable et gouvernable.
La souveraineté est le socle de confiance indispensable pour soutenir l’innovation. Opérer une architecture RAG souveraine permet de relier la puissance des LLM au patrimoine documentaire de l’entreprise, tout en garantissant un cadre d’hébergement et d’exploitation maîtrisé (cloud de confiance, exigences sécurité, conditions contractuelles). C’est cette maîtrise qui permet de construire une IA générative compatible avec les exigences RGPD et prépare celles de traçabilité, de documentation et de tenue de logs lorsque les cas d’usage relèvent des obligations de l’AI Act.
Enfin, une approche souveraine remet la DSI en capacité de piloter le TCO d’un RAG (coûts d’inférence, de réindexation, d’observabilité, d’exploitation) et d’offrir aux métiers un copilote privé fiable, mesuré, et sous contrôle.
Plateforme IA souveraine : de quoi parle-t-on ?
Pour nos experts Data IA, la souveraineté se traduit par un contrat d’exploitation vérifiable.
Une plateforme IA souveraine repose sur quatre piliers indissociables :
- Souveraineté des données : localisation, classification, chiffrement, politiques de rétention, conditions d’accès et de transfert.
- Souveraineté du modèle : liberté de choix, portabilité, réversibilité, capacité multi-modèles, gouvernance des versions.
- Souveraineté opérationnelle : logs et traces, IAM, SLO, runbooks, supervision et capacité de rollback.
- Souveraineté juridique & conformité : exigences RGPD, cadre contractuel de sous-traitance et capacité à démontrer la conformité y compris sur les dimensions de documentation et de record-keeping attendues par l’AI Act lorsque applicable.
En France, la qualification SecNumCloud sert souvent de repère “cloud de confiance” pour les environnements sensibles.
-> A lire sur ce sujet : Règlement (UE) 2024/1689 du Parlement européen et du Conseil du 13 juin 2024 établissant des règles harmonisées concernant l’intelligence artificielle. https://eur-lex.europa.eu/legal-content/FR/TXT/HTML/?uri=OJ:L_202401689 et Posture générale et actions de l’ANSSI sur le cloud, SecNumCloud.
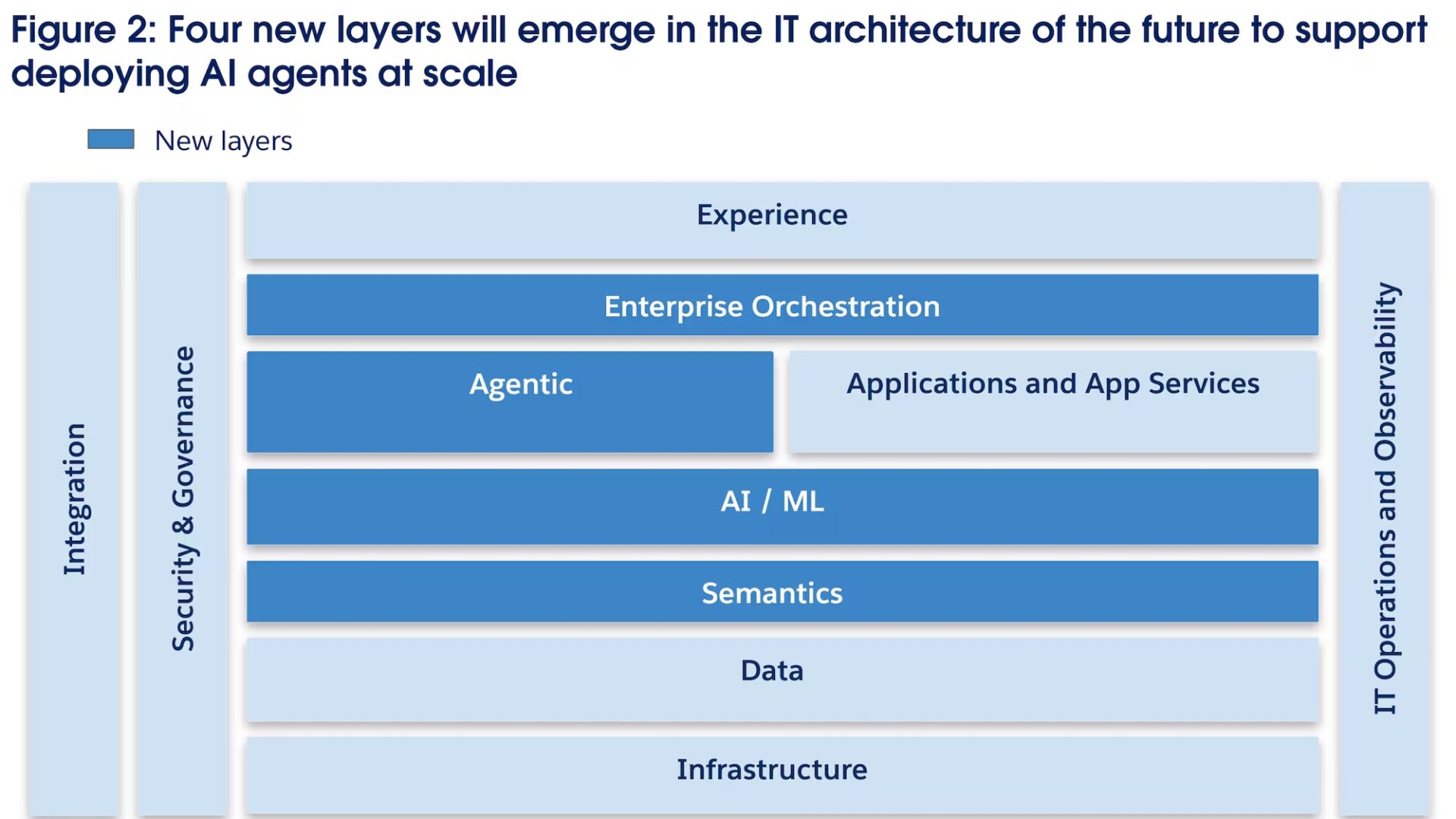
Architecture cible, les 7 briques d’un RAG souverain industrialisable
Nos architectes Data & IA recommandent une architecture structurée autour de 7 briques intégrées dans un cadre d’hébergement et d’exploitation de confiance :
- Compute & Hosting : Hébergement dans un environnement maîtrisé (cloud qualifié SecNumCloud, on-premise ou hybride) afin de réduire la surface d’exposition et de garantir la résidence des données.
- Model Layer : Accès à des LLM privés ou opérés dans un cadre souverain, avec capacité multi-modèles pour arbitrer performance, coût, latence et contraintes de conformité.
- Knowledge Layer : Maîtrise de l’index et du vector store (hybrid search, rerank), avec gouvernance de la fraîcheur (réindexation / re-embedding) et des sources.
- Orchestration : Pipelines RAG incluant guardrails, routage intelligent et quality gates (évaluations) pour valider groundedness, conformité et actions autorisées avant restitution.
- Security & IAM : Politiques RBAC/ABAC, gestion des secrets, segmentation réseau et policy-as-code pour tracer et contrôler les accès comme les usages.
- Observabilité & LLMOps : Monitoring continu (traces, latence, erreurs, groundedness, dérive), journalisation maîtrisée des prompts (masquage PII, rétention), et mécanismes de rollback pour prévenir drift et régressions. (Pour approfondir : Industrialisation RAG, piloter l’IA en production )
- FinOps IA & TCO : Pilotage du coût global (tokens, rerank, réindexation, stockage, observabilité, run) pour éviter les surprises budgétaires et tenir un TCO RAG réaliste. (À lire : Combien coûte un agent IA ? Architecture, stack technique et TCO réel pour les DSI.)
La finalité est de rendre la plateforme IA auditable (logs), réversible (modèle & stack) et opérable (SLO + runbooks).
“La souveraineté n’impose pas un mono-fournisseur local : elle requiert la capacité d’arbitrer, d’auditer et de sortir.” Luc Doladille, Directeur Conseil Data & IA, Smartpoint
Grille de critères pour évaluer une plateforme IA / RAG en termes de souveraineté
Une plateforme IA souveraine, c’est la capacité vérifiable à maîtriser vos données, vos modèles, vos accès, vos coûts… et votre sortie.
Mode d’emploi
Note chaque critère : 0 = absent, 1 = partiel, 2 = maîtrisé.
Score max : 30 points.
| Domaine | Critère | 0 | 1 | 2 |
| Données & flux | Résidence des données documentée (régions/pays/sous-traitants, y compris sauvegardes & logs) | ☐ | ☐ | ☐ |
| Données & flux | Classification appliquée (sensibilité, règles de traitement, data lineage minimal) | ☐ | ☐ | ☐ |
| Données & flux | Rétention & effacement couvrant aussi les données dérivées (embeddings, caches, journaux) | ☐ | ☐ | ☐ |
| Clés, chiffrement, secrets | Contrôle des clés (BYOK/HYOK selon besoin), rotation, accès “break-glass” auditables | ☐ | ☐ | ☐ |
| Clés, chiffrement, secrets | Gestion des secrets centralisée (vault), séparation dev/test/prod, moindre privilège | ☐ | ☐ | ☐ |
| Clés, chiffrement, secrets | Isolation réseau (segmentation, egress control, politiques as-code) | ☐ | ☐ | ☐ |
| Auditabilité & traçabilité | Traçabilité bout en bout (requête → retrieval → rerank → réponse → action) | ☐ | ☐ | ☐ |
| Auditabilité & traçabilité | Logs inaltérables / contrôle d’intégrité (append-only/WORM), horodatage, corrélation | ☐ | ☐ | ☐ |
| Auditabilité & traçabilité | Preuves d’audit exportables (qui/quoi/quand, rôles, sources, versions modèle/index, décisions de garde-fous) | ☐ | ☐ | ☐ |
| Knowledge layer | Gouvernance des sources (liste autorisée, propriétaires, qualité, règles de mise à jour) | ☐ | ☐ | ☐ |
| Knowledge layer | Fraîcheur maîtrisée (réindexation/re-embedding, versioning index, suivi de dérive) | ☐ | ☐ | ☐ |
| Knowledge layer | Protection contre attaques RAG (prompt injection, data poisoning, règles de citation/exclusion) | ☐ | ☐ | ☐ |
| Exploitation & qualité | Évaluation continue avec protocole (jeux de tests, métriques, seuils, fréquence, owners) | ☐ | ☐ | ☐ |
| Exploitation & qualité | Rollback opérationnel (modèle/prompts/règles/reranker/index) + change management | ☐ | ☐ | ☐ |
| Exploitation & qualité | Plan de réversibilité contractuel & technique (export vector store/embeddings, orchestration, logs ; clauses de sortie) | ☐ | ☐ | ☐ |
Vous avez un RAG qui fonctionne en POC, et vous voulez vérifier qu’il est gouvernable, auditable et maîtrisé en coûts avant la mise en production ? Contactez-nous.
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels,
Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Toutes vos questions plateforme IA, RAG et souveraineté
Qu’est-ce qu’une plateforme IA souveraine ?
Une plateforme IA souveraine est un environnement technologique garantissant la maîtrise totale du cycle de vie des données et des modèles, sans dépendance extra-territoriale. Chez Smartpoint, nous définissons cette souveraineté par quatre piliers : la localisation physique des données, l’utilisation de modèles (souvent Open Weights), une infrastructure d’hébergement sécurisée (type Cloud de confiance) et un contrat d’exploitation auditable. Elle permet à la DSI de s’affranchir du vendor lock-in tout en assurant une conformité stricte avec les régulations européennes.
Quelle différence entre RAG souverain et RAG « standard » ?
La différence fondamentale réside dans le contrôle de la chaîne de confiance et l’étanchéité des données. Un RAG « standard » s’appuie généralement sur des solutions SaaS propriétaires (« boîte noire ») où les documents de l’entreprise transitent par des API tierces. À l’inverse, un RAG souverain opéré par intègre le stockage vectoriel et l’inférence du LLM dans un cadre d’hébergement maîtrisé, garantissant que le patrimoine documentaire ne sort jamais du périmètre de sécurité de l’organisation.
SecNumCloud est-il obligatoire pour une IA souveraine ?
Bien que SecNumCloud constitue le plus haut standard de confiance en France, la souveraineté IA repose avant tout sur la capacité à auditer le contrat d’exploitation : qui possède les clés de chiffrement et sous quelle juridiction tombent les données. Pour un projet en production, le choix dépend du niveau de sensibilité des données mais l’utilisation d’une infrastructure qualifiée ou d’un Cloud de confiance est fortement préconisée chez Smartpoint pour neutraliser les risques liés aux lois extraterritoriales.
Comment prouver la traçabilité des réponses d’un RAG ?
La traçabilité s’obtient par la mise en place d’un système d’auditabilité et de tenue de logs rigoureux. Cela implique de documenter chaque étape, de la source documentaire récupérée dans la base vectorielle jusqu’au prompt final soumis au modèle. Cette transparence est essentielle pour répondre aux futures obligations de l’AI Act en matière de documentation technique et de gestion des risques liés aux sorties de l’IA générative.
Comment maîtriser le coût tokens d’un RAG en production ?
La maîtrise du TCO d’un RAG passe par le pilotage précis des coûts d’inférence, de réindexation et d’observabilité. Chez Smartpoint, nous recommandons l’optimisation de la taille des chunks et l’utilisation de modèles adaptés à la tâche (plus légers que les modèles généralistes) pour réduire la consommation de tokens. Une approche souveraine permet souvent une meilleure prédictibilité budgétaire en évitant les fluctuations de prix des API propriétaires.
Quelle gouvernance de l’IA pour être conforme AI Act et RGPD ?
Une gouvernance solide doit garantir que le système est exploitable, auditable et totalement sous contrôle de la DSI. Cela nécessite un cadre d’exploitation maîtrisé incluant des exigences de sécurité strictes et une traçabilité des données d’entraînement et d’inférence. Ce socle de confiance permet de transformer l’IA en un copilote privé fiable, répondant aux impératifs de protection des données personnelles (RGPD) et aux critères de transparence de l’AI Act.