
modernisation BI
Les entreprises se sont presque habituées à fonctionner avec des KPI incohérents d’un tableau de bord à l’autre et les équipes s’en accommodaient. Certes c’était un irritant, parfois couteux, mais tolérable tant que la BI restait principalement consommée dans des dashboards.
Ce temps est derrière nous. La modernisation de la BI ne consiste pas à seulement remplacer un outil décisionnel par un autre, ni à migrer Cognos ou Business Objects vers une plateforme Data cloud-native. La BI moderne, ce n’est plus que de la restitution, elle alimente désormais des insights automatisés, des alertes en temps réel, des interfaces en langage naturel, des APIs analytiques, des copilotes et de plus en plus des agents IA de déclencher des actions.
Une divergence de définition n’a plus la même résonnance, elle se diffuse et pollue l’ensemble. C’est tout le sens métier qui est compromis.
C’est pour ces raisons que la Metrics Layer et la Semantic Layer sont devenus indispensables à la BI moderne. Elles sont la condition sine qua non pour qu’un indicateur conserve la même signification, quel que soit le canal sur lequel il est exposé, consommé, interrogé ou réutilisé. La vraie modernisation de la BI dépasse les considérations d’ergonomie, de vitesse, de performance ou de cloud ou pas cloud ou encore d’ergonomie ; elle passe par la construction d’un commun de sens partagé.
La BI moderne n’est plus dans le dashboard mais dans toutes les interfaces où circule le sens métier
Le principal changement est que les KPIs ne sont plus que des dans des rapports, ils circulent dans les outils métiers, les applications embarquées, les copilotes analytiques, les requêtes en langage naturel … et bientôt dans des workflows décisionnels toujours plus autonomes.
La BI est plus diffuse, conversationnelle, embarquée et agentique.
Et cela change tout en termes d’architecture Data BI. Tant que l’analyste officiait comme intermédiaire quasi incontournable entre les données et les décisions, la correction humaine était implicite. Les erreurs et autres incohérences étaient identifiées et redressées.
Mais lorsqu’un assistant IA répond directement à une question du type « quel était notre taux de churn sur le trimestre dernier ? », il ne sait pas improviser le sens métier. Il a besoin d’un cadre avec un langage métier cohérent, des définitions immuables, des relations explicites, des règles d’agrégation, des exclusions documentées et des hiérarchies compréhensibles.
Historiquement, nous avions une BI centrée sur data visualisation ; elle se déporte sur la sémantique gouvernée. Une « bonne » plateforme décisionnelle doit être aujourd’hui en capacités de garantir que le chiffre est bon, compris par tous ceux qui le consomme de la même manière quel que soit le canal utilisé. Plus la BI est augmentée, plus la gouvernance des métriques est un sujet d’architecture Data.
La Metrics Layer et la Semantic Layer ne répondent pas au même besoin mais sont indissociables
Déjà, revenons sur leurs définitions.
- La Metrics Layer centralise la définition des indicateurs métier. Elle formalise les calculs, les agrégations, les dimensions autorisées, les filtres applicables, les exceptions, les variantes de calcul et si nécessaire, les fenêtres temporelles. Elle précise donc ce qui définit réellement le chiffre d’affaires, la marge, le stock disponible, le revenu net, le churn, le coût d’acquisition, le délai moyen de traitement ou encore le turnover. Son rôle est de remplacer les définitions éparsespar un référentiel de métriques commun, versionné, gouverné et réutilisable dans les tableaux de bord, les APIs, les requêtes en langage naturel, les copilotes et les agents.
- La Semantic Layer organise le sens métier autour de ces indicateurs. Elle relie les métriques à des objets, à un vocabulaire partagé, à des synonymes, à des hiérarchies, à des dimensions, à des relations entre entités et à des descriptions compréhensibles par les utilisateurs métier. Elle précise donc ce que recouvrent réellement des notions comme par exemple un client actif, une commande livrée, un revenu récurrent, une marge commerciale, un stock exploitable ou un canal de vente en les replaçant dans leur contexte d’usage. Son rôle est de remplacer les interprétations par un référentiel sémantique commun, documenté, gouverné et réutilisable.
En clair, la Metrics Layer stabilise le calcul, la Semantic Layer stabilise l’interprétation. La première garantit que le chiffre est produit de façon cohérente et la seconde qu’il est compris de manière cohérente.
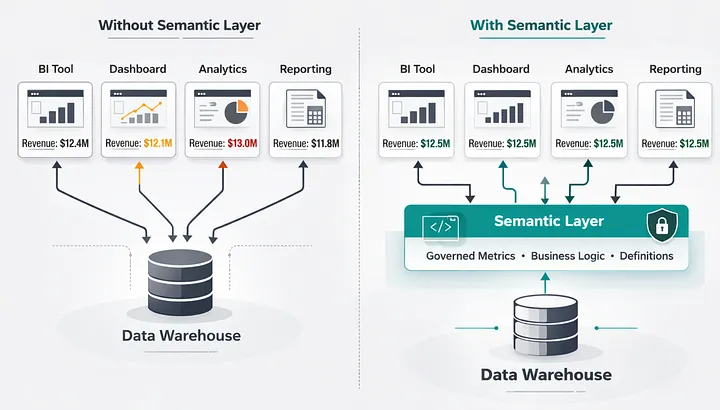
Source : Alwyn DSouza : https://medium.com/towards-data-engineering/why-data-teams-need-a-semantic-layer-83947a5a0057
Le vrai problème de l’IA n’est pas le modèle mais l’absence de sens métier exécutable
Lorsque les réponses générées par un copilote analytique ne sont pas aux attendus, la tentation est grande de condamner le modèle ou la qualité des données. Alors que dans les faits, c’est souvent lié à l’absence de contexte métier exécutable.
Une donnée structurée ne parle pas d’elle-même. Un nom de colonne, une table ou une relation physique ne suffisent pas à dire ce que signifie réellement un KPI dans l’organisation. Une IA peut repérer des schémas, émettre des hypothèses, rapprocher des concepts. Elle ne peut pas deviner par elle-même ce que votre entreprise entend exactement par revenu récurrent net, client actif, commande livrée, stock exploitable ou marge commerciale. Tant que ce sens n’est pas explicitement gouverné, versionné et exposé dans une couche réutilisable, cela ne peut pas fonctionner.
La Semantic Layer ne doit pas être vue comme une simple couche de documentation. Elle a pour rôle de rendre le sens métier directement exploitable par les systèmes. Elle formalise les définitions, les relations, les hiérarchies et les contextes nécessaires pour qu’une plateforme BI, une API analytique, une interface en langage naturel, un copilote ou un agent IA interprète les données de façon cohérente. La semantic Layer est une brique d’architecture à part entière, au croisement de l’analytics, de la gouvernance et de l’AI readiness.
Attention à la dérive sémantique !
Il ne suffit pas d’ajouter une couche sémantique. Encore faut-il qu’elle reste alignée dans la durée sur le modèle physique, sur les transformations opérées et sur les règles métier en production. Sans cela, la plateforme donne une impression de cohérence alors qu’elle diffuse en réalité un sens devenu obsolète.
Une métrique peut rester exposée alors que son calcul a changé. Une relation logique peut rester documentée alors qu’elle ne reflète plus la chaîne de traitement réelle. Une colonne renommée peut ne pas être répercutée correctement. Un libellé métier peut perdurer alors que son périmètre a évolué. La couche sémantique cesse alors d’être ce facteur de stabilité pour devenir une source invisible d’écart.
Dans le cas des dashboards traditionnels, cette dérive produisait des analyses non pertinentes. Dans un univers de BI conversationnelle, de copilotes et d’agents, c’est particulièrement critique. Une réponse fausse mais fluide dégrade la confiance plus vite qu’une absence de réponse.
La dette BI n’est donc plus seulement une dette de pipelines, d’outils ou de restitution. C’est aussi une dette de sémantique. Moderniser la BI, c’est réduire cet écart entre calcul réel, définition métier et interprétation exposée.
Le RAG, les copilotes et les agents ne remplacent pas une couche sémantique gouvernée
Le RAG ne remplace pas la sémantique. Un copilote connecté à de la documentation interne peut très bien retrouver une définition ou expliquer une règle métier. C’est utile mais cela ne suffit pas à garantir la cohérence d’un KPI dans un environnement décisionnel moderne.
Si la logique de calcul est disséminée (requêtes SQL, tableaux de bord, exports Excel..), l’IA ne va rien arranger du tout, elle va au contraire fluidifier l’accès à des bases instables.
Pour que la BI augmentée soit fiable, elle doit s’appuyer sur plusieurs briques : données fiables, chaîne de transformation maîtrisée, métriques versionnées, couche sémantique documentée, data lineage, contrôle d’accès, observabilité, puis seulement des interfaces de restitution ou de conversation.
La bonne architecture, ce n’est pas trancher entre dashboard ou copilote, ni entre RAG et semantic layer. C’est une architecture Data dans laquelle la couche sémantique a un rôle de pivot entre la plateforme data, la BI moderne et les usages IA. Sans cela, la requête en langage naturel, le digest automatisé ou l’agent analytique diffusera des informations possiblement erronées, et ce à grande vitesse. (À lire sur ce sujet « Your Data Architecture Is Ready. Your Semantic Layer Isn’t. Here’s Why That’s the Real AI Problem.«
Les symptômes d’une plateforme BI sans Metrics Layer
On se rend vite compte au quotidien si votre plateforme BI repose bien sur une Metrics Layer ! Les équipes finance, commerce et opérations utilisent des chiffres différents pour décrire une même réalité. Le self-service BI est resté largement théorique, dès qu’une question est sensible, tout le monde se tourne vers les deux ou trois experts historiques. Les projets de migration de legacy BI sont laborieux non pas à cause du volume de rapports mais par ce que les règles métier sont implicites et disséminées dans les dashboards, les requêtes SQL, les exports Excel ou les habitudes des équipes. Elles n’ont jamais été formalisées dans un référentiel commun, au mieux partiellement.
Et c’est précisément là que la dette analytique fait son nid. Le patrimoine décisionnel d’une entreprise n’est pas que dans les outils, les rapports ou les pipelines, il est aussi dans la logique métier accumulée au fil des années. Ainsi, remplacer tel outil BI par un autre ne suffit pas. On modernise l’interface, parfois le run, mais sans repenser le socle de sens qui va soutenir tous les usages.
C’est aussi l’un des constats que nous faisons chez Smartpoint, ESN spécialisée en Data et IA.
la dette de la plateforme décisionnelle ne vient pas seulement d’outils vieillissants, d’ETL historiques ou de l’architecture data. Elle vient tout autant de la dispersion du sens métier, sans point de gravité clair, sans gouvernance unifiée des métriques et sans couche commune pour stabiliser les définitions. Tant que cette dette n’est pas traitée, la modernisation n’aura pas lieu. Il est important de palier à l’absence d’un référentiel de métriques partagé, gouverné et exploitable dans toute la chaîne BI et IA.
Partir des KPI critiques et reconnecter la sémantique à l’architecture
Chez Smartpoint, ESN spécialisée en Data et IA, nous vous conseillons de ne pas vous lancer tout de suite dans un vaste programme de glossaire métier !
Mieux vaut vous concentrer sur les KPI critiques, c’est-à-dire sur ceux qui sont les plus exposés dans l’entreprise : comités, tableaux de bord, exports, alertes, requêtes en langage naturel, APIs, outils métiers, copilotes, agents et applications embarquées. Ce sont eux qui portent le plus de valeur, mais aussi le plus fort risque de divergence.
La bonne démarche consiste d’abord à identifier ces métriques, à versionner leur définition, à documenter les hypothèses, les filtres, les règles d’exclusion et les exceptions, à désigner des owners, puis à relier ces objets à la qualité des données, au data lineage, aux droits d’accès et au change management de la plateforme. La couche sémantique ne doit plus rester à côté de l’architecture data, elle doit devenir une brique du modèle opérable.
C’est aussi ce qui distingue une approche purement aval d’une approche plus proche du design-time. Plus la sémantique est éloignée de la modélisation physique, des transformations et des workflows de changement, plus le risque de dérive augmente. À l’inverse, plus la gouvernance des métriques, le lineage, la qualité et la sémantique sont rapprochés, plus la plateforme décisionnelle gagne en stabilité. L’enjeu n’est donc pas seulement de mieux documenter mais d’intégrer la sémantique au cœur même du cycle de changement.
`
Définir le sens une fois, le réutiliser partout
Au niveau des éditeurs, tous convergent vers une même direction : définir les métriques et le contexte métier une fois, puis les réutiliser dans les tableaux de bord, les usages conversationnels, les APIs et les cas d’usage IA.
- Chez Microsoft, lorsqu’une question porte sur les données, Copilot s’appuie sur le modèle sémantique Power BI pour répondre.
- Chez dbt, la Semantic Layer centralise les définitions de métriques dans la couche de modélisation et les rend cohérentes dans les outils et les applications.
- Google Cloud présente quant-à-lui Looker comme une plateforme orientée API, dotée d’une couche sémantique et d’une interface en langage naturel, tandis que sa documentation indique que Conversational Analytics s’appuie sur la couche sémantique LookML comme source de vérité.
- Snowflake explique que ses Semantic Views rapprochent les données brutes de la compréhension métier et fournissent une couche cohérente pour Cortex Analyst, les outils BI et même SQL.
- Databricks, de son côté, positionne ses Metric Views comme un moyen centralisé, gouverné et réutilisable de définir les KPI, puis d’y ajouter des métadonnées sémantiques utiles aux tableaux de bord AI/BI et aux interfaces en langage naturel.
- Chez Tableau, on “traduit les données dans le langage de l’entreprise”, tandis que Tableau Pulse pousse les métriques directement dans Slack, Teams et les e-mail.
- Qlik parle moins semantic layer mais la logique est proche : Qlik Answers mixe analytics et contenu non structuré pour produire des réponses contextualisées et explicables, avec citations des sources, tandis que Qlik Cloud Analytics distribue analytics, IA, data products, embedded analytics et orchestration.
A lire sur ce sujet pour aller plus loin :
- Utiliser Copilot avec des rapports Power BI et des modèles sémantiques : https://learn.microsoft.com/fr-fr/power-bi/create-reports/copilot-reports-overview
- Pilote automatique de vues sémantiques / Snowflake https://docs.snowflake.com/fr/en/user-guide/views-semantic/autopilot
- Centrally defined metrics: The key to AI success / Dbt Labs https://www.getdbt.com/blog/centrally-defined-metrics
- Conversational Analytics dans Looker https://docs.cloud.google.com/looker/docs/conversational-analytics-overview?hl=fr
- Use semantic metadata in metric views / Databricks https://docs.databricks.com/aws/en/metric-views/data-modeling/semantic-metadata
- Databricks annonce la disponibilité générale et de l’ouverture du code source des sémantiques métier d’Unity Catalog : https://www.databricks.com/fr/blog/redefining-semantics-data-layer-future-bi-and-ai
Et bientôt l’interopérabilité sémantique ?
Si la couche sémantique devient le pivot des produits analytics, dashboards, copilotes, agents et interfaces en langage naturel, un nouveau risque émerge : recréer un vendor lock-in au niveau même du sens métier.
C’est pourquoi l’interopérabilité sémantique devient un enjeu majeur. Sa portabilité comptera bientôt autant que celle des données elles-mêmes. Le sujet dépasse la technique : il touche à la gouvernance, la réversibilité, l’architecture cible et la capacité à faire évoluer la plateforme sans enfermer l’entreprise dans une nouvelle dépendance.
Moderniser la BI, c’est fiabiliser l’architecture décisionnelle
Aujourd’hui, moderniser la BI ne consiste pas à ajouter un énième outil de restitution, mais à bâtir une plateforme décisionnelle garantissant un sens métier unifié. Et cela demande de concevoir un socle solide : données fiables, chaîne de transformations maîtrisée, métriques versionnées, couche sémantique, data lineage, observabilité et contrôle d’accès.
Metrics Layer pour réduire la dette analytique.
Semantic Layer pour relier définitions métier et architecture data.
Cette articulation ouvre le chemin d’une BI statique à une BI exploitable à l’échelle, y compris en conversationnel et IA.
Chez Smartpoint, spécialiste Data & IA, nous sommes convaincus qu’on ne modernise pas durablement la BI en changeant l’outil. On la reconstruit avec un socle de sens gouverné, réutilisable et opérable dans toute la chaîne décisionnelle.
Quelle différence entre Metrics Layer et Semantic Layer ?
La Metrics Layer stabilise le calcul des KPI. la Semantic Layer stabilise leur interprétation métier.
Pourquoi la couche sémantique est critique pour l’IA ?
Parce qu’un copilote ou un agent IA ne peut pas deviner seul ce que signifie un indicateur dans votre entreprise.
Le RAG remplace-t-il la couche sémantique ?
Non. Le RAG aide à retrouver du contexte documentaire, mais il ne remplace pas une définition gouvernée des métriques.




