Quelles architectures de Real-time data processing pour avoir une vision immédiate ?
Dans un monde de plus en plus interconnecté où la rapidité et l’agilité sont facteurs de succès pour les organisations, le traitement des données en temps réel n’est plus un luxe mais une nécessité. Les entreprises ont besoin d’une vision immédiate de leur data pour prendre des décisions éclairées et réagir en temps réel aux événements marché. Le traitement des données en temps réel devient alors un enjeu crucial pour rester compétitif.
Chez Smartpoint, nous concevons des architectures permettant aux entreprises de réagir instantanément aux données entrantes, assurant ainsi un véritable avantage compétitif sur des marchés qui demandent de la réactivité.
1. Fondamentaux des architectures temps réel
Le traitement des données en temps réel se définit comme la capacité à ingérer, traiter et analyser des données au fur et à mesure qu’elles sont générées, sans délai significatif. Cela permet d’obtenir une vue actualisée en permanence de l’activité de l’entreprise et de réagir instantanément aux événements. C’est une réponse directe à l’éphémère « fenêtre d’opportunité » où les données sont les plus précieuses.
Définition et Composants Clés
Des collecteurs de données aux processeurs de streaming, en passant par les bases de données en mémoire, chaque composant est optimisé pour plus de vitesse et d’évolutivité. La réactivité, la résilience et l’élasticité sont les principes fondamentaux de conception de ce type d’architecture. Cela implique des choix technologiques robustes et une conception architecturale qui peut évoluer dynamiquement en fonction du volume des données. Une architecture de Reel-time data processing a une forte tolérance aux pannes, sans perte de données afin d’être en capacités de reprendre le traitement là où il s’était arrêté, garantissant ainsi l’intégrité et la continuité des opérations.
Plusieurs architectures de données peuvent être utilisées pour le traitement en temps réel, chacune avec ses avantages et ses inconvénients :
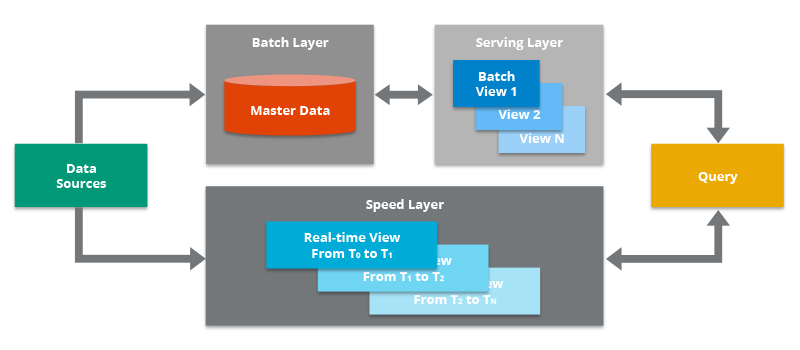
1.1 Lambda Architecture
Principe : Deux pipelines distinctes traitent les données en temps réel et en batch. La pipeline temps réel offre une faible latence pour les analyses critiques, tandis que le pipeline batch assure la cohérence et la complétude des données pour des analyses plus approfondies.
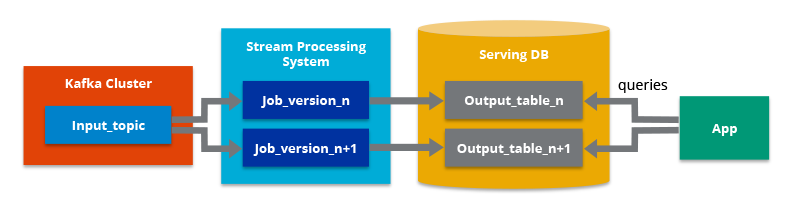
Principe : Unification du traitement des données en temps réel et en batch en un seul pipeline. Cette approche simplifie l’architecture et réduit les coûts de maintenance.
Principe : Se concentrent sur le traitement des données en temps réel en tant que flux continus. Cette approche offre une grande flexibilité et permet de réagir rapidement aux changements dans les données.
Technologies
: Apache Kafka, Apache Storm, Apache Flink
Outils : Apache Beam, Amazon Kinesis, Google Cloud Dataflow
Avantages : Flexibilité, scalabilité et adaptabilité aux nouveaux types de données.
Inconvénients : Complexité de la mise en œuvre et nécessité d’une expertise en streaming de données.
Cas d’utilisation : Surveillance des performances du réseau informatique en temps réel.
Technologie : Apache Kafka ingère les données des capteurs réseau, Apache Storm les traite pour détecter les anomalies et les visualiser en temps réel.
Exemple : Amazon utilise des architectures basées sur les flux de données pour surveiller ses infrastructures en temps réel.
Architecture Lambda++: Combine les avantages des architectures Lambda et Kappa pour une meilleure flexibilité et évolutivité.
Apache Beam : Plateforme unifiée pour le traitement des données en temps réel et en batch.
2. Comment choisir la bonne architecture ?
Le choix de l’architecture de données pour le traitement en temps réel dépend de plusieurs facteurs :
Nature des données: Volume, variété, vélocité et format des données à traiter.
Cas d’utilisation: Besoins spécifiques en termes de latence, de performance et de complexité des analyses.
Compétences et ressources disponibles : Expertises en interne ou recourt à une cabinet spécialisé comme Smartpoint et budget alloué à la mise en œuvre et à la maintenance de l’architecture.
Architecture
Latence
Performance
Scalabilité
Coût
Lambda
Haute
Bonne
Bonne
Élevé
Kappa
Faible
Bonne
Bonne
Moyen
Streaming data architecture
Faible
Excellente
Excellente
Variable
Cas d’usages
Amélioration de l’expérience client Par exemple, la capacité à réagir en temps réel aux comportements peut transformer l’expérience utilisateur, rendant les services plus réactifs et les offres plus personnalisées.
Optimisation opérationnelle La maintenance prédictive, la détection des fraudes, et l’ajustement des inventaires en temps réel sont d’autres exemples d’opérations améliorées par cette architecture.
3. Technologies et outils pour le traitement en temps réel
Kafka et Stream Processing Apache Kafka est une référence pour la gestion des flux de données en temps réel, souvent associé à des outils comme Apache Storm ou Apache Flink pour le traitement de ces flux.
Base de données en mémoire Des technologies comme Redis exploitent la mémoire vive pour le traitement et des accès ultra-rapides aux données.
Frameworks d’Intelligence Artificielle Des frameworks comme TensorFlow ou PyTorch sont employés pour inférer en temps réel des données en mouvement, pour des résultats immédiats.
4. Cas Pratiques par Secteur
Finance : Détection de fraude en millisecondes pour les transactions de marché.
E-commerce : Mise à jour en temps réel des stocks et recommandation de produits personnalisés.
Télécommunications : Surveillance de réseau et allocation dynamique des ressources pour optimiser la bande passante.
Santé : Surveillance en temps réel des signes vitaux pour une intervention rapide en cas d’urgence.
La complexité de l’ingénierie, la nécessité d’une gouvernance des données en temps réel, la gestion de la cohérence, la sécurité et les règlementations sont des défis de taille à intégrer. Smartpoint, à travers ses conseils et son expertise technologique, accompagne les CIO pour transformer ces défis en opportunités.
— Yazid Nechi, Président, Smartpointt
Et demain ?
Les architectures de Reel-time data processing sont amenées a évoluer rapidement, alimentées par l’innovation technologique et les besoins accrus des entreprise pour du traitement temps réel des données. Avec l’avènement de l’IoT, l’importance de la cybersécurité devient centrale, nous amenant à adopter des protocoles plus solides et à intégrer l’IA pour une surveillance proactive. L’informatique quantique, bien que encore balbutiante, promet des avancées considérables dans le traitement de volumes massifs de données, tandis que l’apprentissage fédéré (federeted learning) met l’accent sur la confidentialité et l’efficacité de l’apprentissage automatique.
Des outils comme DataDog et BigPanda soulignent la pertinence de l’observabilité en temps réel et de l’analyse prédictive, et des plateformes telles qu’Airbyte montrent l’évolution vers des solutions de gestion de données sans code.
À mesure que ces tendances gagnent en importance, Smartpoint se prépare à un data world où l’agilité, la sécurité et la personnalisation seront les clés de voûte des infrastructures de données temps réel de demain, redéfinissant la réactivité et l’efficacité opérationnelle de tous les secteurs d’activité.
« Real-Time Data Analytics: The Next Frontier for Business Intelligence » by Thomas Erl, Zaigham Mahmood, and Ricardo Puttini
« Building Real-Time Data Applications with Azure » by Steve D. Wood
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Architecture
Choisir une architecture data modulaire ?
0 commentaires
1. Définition et principes d’architecture
L’agilité la capacité à évoluer très rapidement – voir de « pivoter » – ne sont plus aujourd’hui l’apanage des startups. Toutes les entreprises doivent s’adapter, réagir et innover constamment pour exister sur leurs marchés. On évoque souvent la nécessite d’avoir un système d’information agile, l’architecture de données modulaire est son pendant.
Ce modèle architectural, qui s’oppose à la rigidité des systèmes monolithiques traditionnels, est basé sur la conception de composants autonomes ou modules indépendants qui peuvent interagir entre eux à travers des interfaces prédéfinies. Chacun est dédié à une fonctionnalité data spécifique qui couvre un aspect de la chaine de valeur. Cette approche fragmente le système en sous-ensembles de tâches, ou de modules, qui peuvent être développés, testés et déployés de manière indépendante :
Collecte & ingestion des données, processus dynamique qui prend en charge divers formats, en temps réels ou en lots
Traitement et transformation, exécution d’opération comme le nettoyage, le redressement ou l’enrichissement des données, l’application de règles métiers, la conversion dans d’autres formats
Organisation et stockage selon les performances attendues, en data lake, en base de données opérationnelle, en data warhouse ou solution de stockage hybride
Analyse et restitution, pour le calcul de KPI, l’exécution de requêtes, l’utilisation de l’IA pour obtenir des insights, la génération de rapports, etc.
Sécurité et conformité, pour la gestion de l’authentification et des accès, le chiffrement (…) mais aussi la compliance auditable avec toutes les règlementations en vigueur dont RGPD
Cette architecture modulaire offre aux entreprises la possibilité de mettre à jour, de remplacer ou de dé-commissionner des composants distincts sans impacter le reste du système Data. En d’autres termes, une architecture de données modulaire est semblable à un jeu de legos où l’on peut ajouter, retirer ou modifier des blocs selon les besoins, sans devoir reconstruire l’ensemble de la structure.
La flexibilité en priorité
La quantité de données générées et collectées par les entreprises a explosé littéralement et les volumes sont exponentiels, tout comme la variété des formats et la vitesse de traitement requise. Les systèmes d’information (SI) doivent plus que jamais être en capacités de s’adapter rapidement à ces nouvelles exigences. Hors le poids du legacy reste le frein numéro 1. Lors des chantiers de modernisation des SID (Système d’information décisionnel historiques) ; le choix d’une architecture modulaire est de plus en plus populaire et pour cause.
Les architectures modulaires répondent à ce besoin impérieux de flexibilité sur des marchés très concurrencés, mondiaux et volatiles. C’est un choix qui permet une meilleure réactivité face à l’évolution très rapides des besoins métiers, des innovations technologiques ou des changements stratégiques. Ces architectures sont nativement conçues pour une intégration facile de nouvelles technologies, telles que le traitement en temps réel des données ou l’intelligence artificielle, tout en supportant les besoins croissants en matière de gouvernance et de sécurité des données.
Cette flexibilité est également synonyme de viabilité à long terme pour les systèmes d’information, offrant ainsi aux entreprises un avantage concurrentiel durable. En résumé, l’architecture de données modulaire n’est pas seulement une solution pour aujourd’hui, mais une fondation solide pour l’avenir.
2. Les avantages d’une architecture Data Modulaire
Une architecture Data modulaire répond aux enjeux de notre ère basée sur la prolifération des données mais pas que ! C’est aussi une réponse alignée sur une stratégie d’entreprise pour qui la flexibilité et l’innovation continue sont des impératifs.
2.1. Évolutivité et facilité de maintenance
La maintenance et l’évolution des SI sont des gouffres financiers, fortement consommateurs de ressources et souvent un frein à l’innovation. Une architecture data modulaire facilite grandement la tâche ! Un composant peut être mis à jour ou remplacé sans risquer d’affecter l’intégralité du système, ce qui réduit significativement les temps d’arrêt et les coûts associés. L’évolutivité et l’innovation sont intrinsèques : ajout de nouvelles fonctionnalités, remplacement, montée en charge, intégration de nouvelles sources de données, (…).
2.2. Agilité organisationnelle et adaptabilité
Dans notre écosystème résolument numérique, l’agilité est primordiale. En isolant les différentes fonctions liée la gestion des données dans des modules autonomes, les architecture data modulaire s’adaptent aux demandes et aux besoins par nature évolutifs. Cette structure permet non seulement d’intégrer rapidement de nouvelles sources de données ou des technologies émergentes ; mais aussi de répondre efficacement aux exigences réglementaires spécifiques à la data.
Exemples : Dans le cas des évolutions des normes de protection des données, le module dédié à la sécurité peut être mis à jour ou remplacé sans affecter les mécanismes de traitement ou d’analyse de données. De même, si une entreprise décide de tirer parti de nouvelles sources de données IoT pour améliorer ses services, elle peut développer ou intégrer un module d’ingestion de données spécifique sans perturber le fonctionnement des autres composants.
Cette adaptabilité réduit considérablement la complexité et les délais associés à l’innovation et à la mise en conformité, ce qui est fondamental pour conserver une longueur d’avance dans des marchés data-driven où la capacité à exploiter rapidement et de manière sécurisée de grandes quantités de données est un avantage concurrentiel qui fait clairement la différence.
2.3 Optimisation des investissements et des coûts dans la durée
L’approche « pay-as-you-grow » des architectures data modulaires permet de lisser les dépenses en fonction de l’évolution des besoins, sans donc avoir à engager des investissements massifs et souvent risqués. Cette stratégie budgétaire adaptative est particulièrement pertinente pour les entreprises qui cherchent à maîtriser leurs dépenses tout en les alignant sur leur trajectoire de croissance.
3. Architecture Modulaire vs. Monolithique
En ingénierie de la data, on distingue les architectures modulaires des systèmes monolithiques en raison de l’impact direct que leur structure même a sur l’accessibilité, le traitement et l’analyse des données.
3.1. Distinctions fondamentales
Les monolithiques fonctionnent comme des blocs uniques où la collecte, le stockage, le traitement et l’analyse des données sont intégrés dans une structure compacte ce qui rend l’ensemble très rigide. Ainsi, une modification mineure peut nécessiter une refonte complète ou de vastes tests pour s’assurer qu’aucune autre partie du système ne connait de régression.
Les architectures de données modulaires, quant à elles, séparent ces fonctions en composants distincts qui communiquent entre eux via des interfaces, permettant des mises à jour agiles et des modifications sans perturber l’ensemble du système.
3.2. Maintenance & évolution
Faire évoluer et maintenir un SID monolithique peut être très fastidieux car chaque modification peut impacter l’ensemble. En revanche, dans le cas d’une architecture de données modulaire, l’évolution se fait composant par composant. La maintenance est facilitée et surtout moins risquées.
Exemple : Le changement ou l’évolution du module Data Visualisation ne perturbe en rien le module de traitement des données, et vice versa.
3.3. Intégration des innovations technologiques
L’ingénierie de la data est foisonnante de changements technologique, les architectures modulaires offrent une meilleure adaptabilité. Elles permettent d’intégrer rapidement de nouveaux outils ou technologies telles que l’Internet des Objets (IoT), les data cloud platforms, les solutions d’IA, de machine Learning ou encore d’analyse prédictive ; alors qu’un système monolithique nécessite une refonte significative pour intégrer de telles solutions. Elles permettent l’intégration de technologies avancées telles avec plus de facilité et moins de contraintes.
Les architectures modulaires encouragent l’innovation grâce à leur flexibilité intrinsèque. Les équipes peuvent expérimenter, tester et déployer de nouvelles idées rapidement, contrairement au SID monolithique plus lourd et complexe à manipuler. Cette capacité d’adaptation est cruciale pour exploiter de nouvelles données, telles que les flux en temps réel ou les grands volumes de données non structurées.
Exemple : l’introduction d’un module d’apprentissage automatique pour l’analyse prédictive peut se faire en parallèle du fonctionnement normal des opérations, sans perturbation.
3.4. Évolutivité & performances
Les architectures de données modulaires peuvent être optimisées de manière granulaire au niveau des charges pour dimensionner les performances au plus juste des besoins ; et ce sans impacter les autres fonctions du système. Dans un système monolithique, augmenter la performance implique souvent de redimensionner l’ensemble du système, ce qui est moins efficace et surtout plus coûteux.
Contrairement aux systèmes monolithiques, où l’intégration de nouvelles technologies peut être un processus long et coûteux, les architectures modulaires sont conçues pour être évolutives et extensibles.
4. Architecture modulaire vs. microservices
4.1 différences entre une architecture data modulaire et une architecture microservices
Les deux termes peuvent en effet porter à confusion car ces deux types d’architecture sont basés sur la décomposition en modules autonomes mais l’un est orienté services, l’autre composants. Leurs pratiques de développement et de mise en opérations sont bien distincts.
Dans l’architecture data modulaire, chaque module représente une certaine capacité du système et peut être développé, testé, déployé et mis à jour indépendamment des autres.
Les microservices, en revanche, sont un type spécifique d’architecture modulaire qui applique les principes de modularité aux services eux-mêmes. Un système basé sur des microservices est composé de petits services autonomes qui communiquent via des API. Chaque microservice est dédié à une seule fonctionnalité ou un seul domaine métier et peut être déployé, mis à jour, développé et mise à l’échelle indépendamment des autres services.
4.2 Comment choisir entre architecture modulaire et microservices ?
Taille et complexité du projet : Les microservices, par leur nature granulaire, peuvent introduire une complexité inutile dans la gestion des petits entrepôts de données ; ou pour des équipes d’analyse de données limitées. Ils sont surdimensionnés pour les petits projets. Une architecture modulaire, avec des composants bien définis pour la collecte, le traitement et l’analyse, suffit largement.
Expertises des équipes data : Une architecture microservices nécessite des connaissances spécialisées sur l’ensemble de la chaine de création de valeur de la data, de la collecte à l’analyse, ce qui n’est pas forcément transposable sur des petites équipes ou composées de consultants spécialisés par type d’outils.
Dépendance et intégration : L’architecture modulaire gère mieux les dépendances fortes et intégrées, tandis que les microservices exigent une décomposition fine et des interfaces claires entre les services. Les architectures modulaires se comportent donc mieux quand les données sont fortement interdépendantes et lorsque des modèles intégrés sont nécessaires. Les microservices, quant-à-eux, sont plus adaptés quand on cherche une séparation claire et des flux de données autonomes, permettant ainsi des mises à jour très ciblées sans affecter l’ensemble du pipeline de données.
Performances et scalabilité : Les microservices peuvent être recommandés dans le cas de traitements à grande échelle qui nécessitent une scalabilité et des performances individualisées. En revanche, cela vient complexifier la gestion du réseau de données et la synchronisation entre les services.
Maintenance des systèmes de données : Bien que ces deux types d’architectures soient par natures évolutifs, les microservices facilitent encore davantage la maintenance et les mises à jour en isolant les changements à des services de données spécifiques. Cela peut réduire les interruptions et les risques d’erreurs en chaîne lors des mises à jour dans des systèmes de données plus vastes.
5. Cas d’usages et applications pratiques
Une architecture de données modulaire, avec sa capacité à s’adapter et à évoluer, est particulièrement recommandée dans des cas où la flexibilité et la rapidité d’intégration de nouvelles technologies sont essentielles. Elle est devenu est must-have pour les entreprises qui cherchent à maximiser l’efficacité de leurs systèmes d’information décisionnels.
Voici quelques exemples concrets et études de cas où ce choix s’impose.
Télécoms : Dans ce secteur, où les volumes de données sont gigantesques et les besoins de traitement en temps réel sont critiques, l’architecture modulaire permet d’isoler les fonctions de traitement et d’analyse de flux de données, facilitant une analyse et une prise de décision rapides sans perturber les autres systèmes.
Secteur de la santé – Gestion des dossiers patients : Une architecture modulaire est particulièrement efficace pour gérer les dossiers de santé électroniques dans les hôpitaux. Des modules autonomes traitent les entrées en laboratoires d’analyse, les mises à jour des dossiers médicaux et les ordonnances, permettant des mises à jour régulières du module de gestion des prescriptions sans perturber l’accès aux dossiers historiques des patients.
Banque et finance – Analyse de la fraude : Un de nos clients utilise un module d’analyse de fraude en temps réel sur son système de gestion des transactions financières. Ce module s’adapte aux nouvelles menaces sans nécessiter de refonte du système transactionnel entier, ce qui renforce la sécurité et réduit les failles de vulnérabilité.
Plateformes de streaming vidéo : Ces services utilisent des architectures modulaires pour séparer le traitement des données de recommandation d’utilisateurs des systèmes de gestion de contenu, permettant ainsi d’améliorer l’expérience utilisateur en continu et sans interrompre le service de streaming principal.
Fournisseurs de services cloud : Ils tirent parti de modules dédiés à la gestion des ressources, à la facturation et à la surveillance en temps réel pour offrir des services évolutifs et fiables, enrichis en solutions d’IA notamment innovations pour l’analyse prédictive de la charge serveur.
Études de cas sur les bénéfices des architectures modulaires vs. monolithiques :
E-commerce – Personnalisation de l’expérience client : Un de nos clients, plateforme de vente en ligne, a implémenté un module d’intelligence artificielle pour la recommandation de produits. Cette modularité a permis d’innover en incorporant l’apprentissage automatique sans avoir à reconstruire leur plateforme existante, augmentant ainsi les ventes croisées et additionnelles.
Smart Cities – Gestion du trafic : Une métropole a installé un système modulaire de gestion du trafic qui utilise des capteurs IoT pour adapter les signaux de circulation en temps réel. L’introduction de nouveaux modules pour intégrer des données de différentes sources se fait sans interruption du service, améliorant ainsi la fluidité du trafic et les prédictions.
Avantages et inconvénients de l’architecture modulaire en ingénierie des données :
Avantages
Agilité : Permet une intégration rapide de nouvelles sources de données, d’algorithmes d’analyse, etc.
Maintenabilité : Les mises à jour peuvent être opérées sur des modules spécifiques sans interruption de services.
Inconvénients
Complexité de l’intégration : L’implémentation peut demander des charges supplémentaires pour assurer l’intégration entre les modules.
Gestion des dépendances : Une planification rigoureuse est nécessaire pour éviter les conflits entre modules interdépendants.
5. Conception d’une Architecture de Données Modulaire
En ingénierie data, la conception d’une architecture modulaire nécessite une segmentation du pipeline de données en modules distincts et indépendants, chacun est dédié à une tâche précise dans la chaîne de valeur des données.
Les prérequis d’une architecture data modulaire :
Interopérabilité : Les modules doivent s’intégrer et communiquer entre eux facilement via des formats de données standardisés et des API bien définies. Cette étape est cruciale pour garantir la fluidité des échanges de données entre les étapes de collecte, d’ingestion, de traitement et d’analyse.
Gouvernance des données : Chaque module doit être conçu avec des mécanismes de gouvernance (governance by design) pour assurer l’intégrité, la qualité et la conformité des données à chaque étape : gestion des métadonnées, contrôle des versions, audit, …
Sécurité : Vous devez intégrer un système de contrôle de sécurité adapté à la nature des données traitées dans chaque module. Par exemple, les modules de collecte de données ont besoin de sécurisation des données en transit, tandis que ceux impliqués dans le stockage se concentrent sur chiffrement des données froides.
Les meilleures pratiques pour la conception de systèmes modulaires
Conception granulaire : Vous devez penser vos modules autour des fonctionnalités de données spécifiques attendues, en veillant à ce qu’ils soient suffisamment indépendants pour être mis à jour ou remplacés sans perturber le pipeline global.
Flexibilité et évolutivité : Vous devez concevoir des modules qui peuvent être facilement mis à l’échelle ou modifiés pour s’adapter à l’évolution des données, comme l’ajout de nouveau formats de données ou l’extension des capacités d’analyse sur des volumes étendus.
Cohérence et normalisation : Vous devez tendre vers des standards pour la conception des interfaces des modules et la structuration des données, ce qui simplifiera l’ajout et l’harmonisation de modules additionnels et l’adoption de nouvelles technologies dans le futur.
6. Tendances Futures et Prédictions
À l’heure où l’IA et l’apprentissage automatique redessine notre monde et nourrisse l’ingénierie de la Data, l’architecture de données modulaire vraisemblablement connaitre aussi des transformations majeures à court terme.
Intégration approfondie de l’IA : Les modules d’IA seront de plus en plus élaborés, capables d’effectuer non seulement des analyses de données, mais aussi de prendre des décisions autonomes sur la manière de les traiter et de les stocker. L’auto-optimisation des pipelines de données basée sur des modèles prédictifs pourra augmenter l’efficacité et réduire les coûts opérationnels. Ils pourront identifier des modèles complexes indétectables par des analyses traditionnelles.
Apprentissage automatique en tant que service : L’architecture de données modulaire incorporera surement des modules d’apprentissage automatique en tant que service (MLaaS), permettant une scalabilité et une personnalisation accrues. Ces services seront mis à jour régulièrement avec les derniers algorithmes sans redéploiement lourd du système. Ces modules incluront des composants capables d’auto-évaluation et de recalibrage pour s’adapter aux changements de données sans intervention humaine. Par exemple, un module pourra ajuster ses propres algorithmes de traitement de données en fonction de la variabilité des schémas de données entrantes.
Auto-réparation et évolutivité : Les modules seront conçus pour détecter et réparer leurs propres défaillances en temps réel, réduisant ainsi les temps d’arrêt. Avec l’apprentissage continu, ils anticiperont les problèmes avant qu’ils ne surviennent et adapteront leur capacité de traitement selon les besoins.
Interopérabilité avancée : Les futures architectures de données modulaires seront probablement conçues pour interagir sans effort avec une variété encore plus large de systèmes et de technologies, y compris des algorithmes d’IA très élaborés, des modèles de données évolutifs et des nouveaux standards d’interface.
Automatisation de la gouvernance des données : Les modules dédiés à la gouvernance utiliseront l’IA pour automatiser la conformité, la qualité des données et les politiques, rendant la gouvernance des données plus proactive et moins sujette à erreur.
L’architecture de données modulaire va devenir plus dynamique, adaptative et intelligente, tirant parti de l’IA et de l’apprentissage automatique non seulement pour la gestion des données mais pour continuellement s’améliorer et innover dans le traitement et l’analyse des données.
Une architecture de donnée modulaire, en bref.
Une architecture de données modulaire offre aux entreprises une flexibilité sans précédent. Elle permet de gagner en agilité opérationnelle car elle a la capacité de se dimensionner et de s’ajuster aux changements qu’ils soient métiers ou technologique sans impact négatif sur le système existant. Cette approche par composants autonomes permet une meilleure gestion du pipeline de données et une évolutivité des systèmes inégalées. Les coûts et les interruptions liés à l’évolution technologique s’en trouvent drastiquement réduits. En outre, l’architecture modulaire est conçue pour intégrer facilement les dernières innovations comme l’intelligence artificielle et le machine learning. Des bases solides en sommes pour soutenir votre transformation digitale et votre croissance sur vos marchés.
Quelques solutions pour vous accompagner dans cette transition technologique
Databricks – Pour une plateforme unifiée, offrant une analyse de données et une IA avec une architecture de données modulaire au cœur de sa conception.
Snowflake – Offre une architecture de données dans le cloud conçue nativement pour être flexible et l’évolute, permettant aux entreprises de s’adapter rapidement aux besoins et aux demandes changeantes des métiers et des marchés.
GoogleCloudPlatform – Avec BigQuery, une solution puissante pour une gestion de données modulaire, permettant une analyse rapide et à grande échelle.
Architecture
Architecture Data, micro-services ou monolithique ? Un choix déterminant pour votre infrastructure d’entreprise.
0 commentaires
Alors qu’il existe une multitude d’outils et de solutions data qui s’offrent à vous ; vous devez vous interroger sur votre architecture Data – et sa roadmap – car c’est elle qui doit influencer votre stack technologique. Il ne s’agit pas tant de choisir entre architecture monolithique et architecture micro-services que de s’interroger sur la pertinence de votre stratégie data dont l’objectif est de soutenir votre business et vos capacités d’innovations dans la durée. Votre « vision data » va se traduire par une décision architecturale qui définit la manière dont votre entreprise gère et valorise ses données. Explications.
Du on-premise au cloud, c’est aussi une évolution architecturale !
Le paysage technologique des deux dernières décennies a connu une transformation radicale. Hier, les architectures de données étaient intrinsèquement en silos, chaque système fonctionnant en vase clos avec des degrés de compatibilité très limités. Les applications et les données étaient prisonnières d’infrastructures « on-premise » où l’intégration et l’interopérabilité étaient des défis majeurs (et des vrais centres de coûts) qui freinaient la collaboration et la pleine exploitation des données.
Aujourd’hui, le paradigme a basculé vers le « cloud », où se mêlent des configurations hybrides et des solutions on premise toujours très présentes. L’adoption d’architectures en micro-services a radicalement changé l’approche de la conception et de la gestion des données. Cependant, avec cette nouvelle liberté vient la responsabilité de choisir judicieusement parmi un large éventail d’outils éditeurs et de services offerts par divers cloud service providers (CSP). Les micro-services offrent un catalogue de services indépendants, chacun excellant dans sa spécialité et communiquant avec les autres via des interfaces bien définies.
Architectures Data, monolithique vs. micro-services
L’Architecture monolithique
C’est la configuration traditionnelle que l’on rencontre encore dans la plupart des entreprises. Toutes les fonctions sont regroupée en un seul et unique bloc logiciel. Imaginons par exemple, un énorme référentiel Airflow qui gère à la fois l’ingestion, la transformation des données et l’automatisation des processus métier, comme un guichet unique pour toutes les opérations data.
L’Architecture Microservices
Avec le cloud, les architectures data ont évolué vers un modèle de micro-services, où chaque service est autonome et spécialisé dans une fonction précise : gestion des données batch, transformation des données ou data warehousing. Citons pour exemples AWS Lambda, Apache Kafka, ou encore Snowflake choisis pour leur efficacité dans leurs domaines respectifs. Chaque service opère indépendamment, permettant une spécialisation et une adaptabilité qui étaient inimaginables dans les architectures en silos du passé.
Quel choix d’outil pour quelle architecture ?
Pour une architecture monolithique : Vous pouvez choisir des outils intégrés capables de gérer l’ensemble du cycle de vie des données au sein d’une même plateforme, tels que Talend ou Informatica. Les solutions comme Microsoft SQL Server Integration Services (SSIS) pour Azure peuvent convenir à ce type d’architecture en offrant un ensemble d’outils unifié.
Pour une architecture microservices : Vous optez pour la spécialisation avec des outils dédiés pour chaque service. AWS Lambda pour l’exécution de code sans serveur, Apache Kafka pour le traitement des flux de données en temps réel, et Snowflake pour le data warehousing sont des exemples de cette diversification des outils. Ou encore Azure Functions pour des scénarios d’intégration événementielle, et Google BigQuery pour l’analyse en volume des données.
Quels critères essentiels à prendre en compte dans votre choix d’architecture data ?
Spécialisation vs. Intégration : L’architecture micro-services comprend la spécialisation (une fonction = un service), mais exige une intégration rigoureuse pour éviter la création de nouveaux silos.
Infrastructure distribuée : Les micro-services optimisent l’efficacité et la scalabilité. AWS Lambda, par exemple, offre une solution de calcul sans serveur, tandis qu’un cluster Kubernetes est préférable pour des charges de travail plus lourdes et constantes. Azure et AWS offrent une variété de services qui s’alignent avec cette approche, comme Azure Event Hubs pour l’ingestion d’événements à grande échelle ou AWS Kinesis pour le streaming de données.
Interopérabilité et gouvernance des données : L’interconnexion entre services est un enjeu majeur ! Les outils d’orchestration comme Apache Airflow peuvent aider … mais cela induit souvent des coûts supplémentaires et de la complexité. L’interopérabilité doit être intégrée dès la conception pour éviter des solutions de gouvernance onéreuses comme les catalogues de données ou des outils d’observabilité. Les services comme Azure Data Factory et AWS Glue facilitent l’orchestration de workflows data et l’intégration de services.
Gestion des coûts : Les architectures microservices peuvent entraîner des coûts de transfert de données inattendus. Des outils comme Apache Kafka réduisent ces coûts en optimisant le traitement des données avant de les déplacer vers des solutions comme Snowflake. Les coûts de transfert et de stockage des données restent un point de vigilance. Les solutions comme Apache Kafka et les services de streaming de données peuvent minimiser ces coûts et optimiser le flux de données.
Architecture Data en micro-services ou monolithique ?
L’architecture choisie est essentielle car elle va déterminer l’efficacité de votre stratégie data. Dans un monde où les fournisseurs de cloud continuent d’innover et d’intégrer des services plus efficaces, les architectures modulaires en micro-services sont appelées à devenir encore plus interconnectées, performantes et économiques. L’avenir des données se dessine dans le cloud, où la complexité cède la place à la connectivité, à toujours plus d’agilité et à l’optimisation des coûts.
Chez Smartpoint, nous vous accompagnons dans la conception et la mise en oeuvre d‘une architecture data, sur mesure, en parfait alignement avec votre stratégie et vos objectifs métiers. Notre expertise et notre approche agnostique vous assurent une stratégie data qui n’est pas seulement performante aujourd’hui, mais qui est aussi prête pour les innovations de demain.Challengez-nous !
En ingénierie des données, le Data Mesh s’impose comme un changement de paradigme face aux limites des entrepôts de données et data lakes traditionnels. Il ne s’agit plus simplement de stocker ou de centraliser, mais de concevoir une architecture de données distribuée, orientée domaine, pour une gestion des données plus agile et évolutive.
Les Data Products sont dont conçus, développés et maintenus en fonctions des besoins spécifiques de leur domaine, conformément aux principes fondamentaux de l’approche Data Mesh.
Les principes fondamentaux de cette architecture data, de sa conception à son exécution.
Le Data Mesh repose sur une architecture data où chaque domaine métier devient responsable de ses propres data products, contribuant ainsi à une gouvernance décentralisée efficace. Contrairement aux modèles centralisés où la plateforme décisionnelle repose sur un unique entrepôt de données, ici, la donnée est traitée comme un produit, exploitable directement par ceux qui en ont la responsabilité fonctionnelle.
Les données sont l’actif principal : Toute décision concernant la conception et l’architecture doit être prise en fonction des données qui sont traitées comme des produits. Elles ne sont plus une ressource cachée, mais un produit concret avec une propriété claire et des règles d’accessibilité précises.
La gouvernance des donnée est décentralisée : Les propriétés et le contrôle des données sont distribués parmi différents domaines et les équipes en charge de ces domaines. Les équipes de domaine sont responsables de la qualité, de l’accessibilité et de la compréhension des données, garantissant ainsi que les données sont entre les mains de ceux qui les connaissent le mieux !
La conception pilotée par le domaine, Domain Driven Design, est par nature adaptée à ce type d’architecture. Le développement piloté par des composants autonomes et réutilisables, Component-DrivenDevelopement, fournit la modularité nécessaire pour la mettre en oeuvre. Dans un data mesh, ces composants correspondent à des pipelines de données, des traitements ou des systèmes de delivery des données spécifiques aux domaines.
L’intéropérabilité des données : Un schéma de données commun favorise un échange fluide des données entre les différents systèmes.
Une architecture basée sur les événements : L’échange de données s’effectue en temps réel au fur et à mesure que les événements se produisent.
La sécurité des données : La protection des données est réalisée via grâce à des mesures telles que le contrôle des d’accès et le chiffrement.
La scalabilité et résilience : l’architecture est conçue nativement pour gérer de grands volumes de données et résister aux défaillances.
Scalabilité : Le Data Mesh est conçu pour supporter la croissance des volumes, des domaines et des usages, sans réécrire l’architecture BI.
Flexibilité : L’approche est compatible avec les environnements hybrides (on-premise / plateformes BI cloud) et prend en charge des protocoles hétérogènes.
Sécurité : Une gouvernance par domaine renforcée par des contrôles d’accès adaptés aux nouveaux standards de gestion des données critiques.
Résilience : Contrairement aux data lakes monolithiques, l’architecture distribuée résiste mieux aux pannes et évolue par composants.
Pourquoi faire le choix d’une architecture Data Mesh plutôt qu’un entrepôt de données classique ?
Les modèles traditionnels basés sur un unique entrepôt de données ou un data lake centralisé ne suffisent plus à répondre aux exigences de la modernisation BI. En répartissant les responsabilités de la gestion des données entre les domaines métiers, le Data Mesh permet de concevoir une architecture BI réellement scalable et résiliente, compatible avec les plateformes BI Cloud et les nouveaux modèles décisionnels distribués.
Le Data Mesh n’est pas qu’un simple buzz word mais bien un changement de paradigme en ingénierie des données qui s’appuie sur des changement majeurs : la donnée est considérée comme un produit accessible, l’infrastructure est en en libre-service, une plateforme de données as a product et une gouvernance axée sur des domaines spécifiques propriétaires.
Comment concevoir votre Data Mesh via le Domain Driven Design (DDD) et le Composant Driven Developement (CDD) ?
La première étape consiste à identifier et délimiter vos différents domaines via le domain driven design (DDD). Cela permet de se concentrer sur le périmètre précis de chaque domaine, les relations entre eux, les processus associés, etc. Dès lors, vous avez la base de vos Data Products ! Reste à cartographier votre « paysage » de données, c’est à dire comment le domaine consomme les données, comment elles circulent, qui les exploitent, à quoi elles servent et quelles sont leurs valeurs ajoutées. Une fois le paysage posé, vous devez définir clairement votre domaine et ses limites en vous concentrant sur les données spécifiques à ce domaine en particulier et les processus associés, c’est ce qui va permettre de définir les responsabilités de chacun, puis d’attribuer la propriété des data products. C’est le principe même du data-mesh, responsabiliser les équipes les plus à même de comprendre leurs données et de gérer leur domaine !
Une fois vos « produits de données » définis, le composant-driven developement vous permet de réaliser votre architecture en décomposant votre domaine en petits composants indépendants, autonomes, faciles à gérer et réutilisables. Chaque composant est associé à une tache spécifique comme l’ingestion, la transformation, le stockage ou encore la livraison des données. Ils sont développés, testés et déployés de manière indépendante.
Il ne vous reste plus qu’à assembler votre data-mesh ! Chaque composant interagit avec les autres pour former un système cohérent avec des protocoles de communication normalisés et des APIs pour garantir l’intéropérabilité entre les composants.
Vous souhaitez moderniser votre architecture de données ou migrer vers une plateforme BI Cloud plus agile et distribuée ? Faites appel à Smartpoint, l’ESN experte en architecture BI et Data, pour construire une stratégie Data Mesh adaptée à vos enjeux métier.
Le Data Mesh est aujourd’hui l’une des architectures les plus prometteuses pour structurer des systèmes data scalables, autonomes et gouvernés à l’échelle. Son adoption demande rigueur et accompagnement, mais le retour sur investissement est élevé pour les grandes entreprises.
Architecture
Le Data Mesh, la réponse aux limites des architectures data traditionnelles en 4 piliers fondateurs.
Article publié le 26 septembre 2023 — mis à jour le 8 octobre 2025
L’écosystème Data est en constante mutation. Alors que les entreprises cherchent des moyens de mieux collecter, gérer et exploiter leurs vastes gisements et autres actifs de données, une nouvelle approche nommée Data Mesh s’impose. Développée par Zhamak Dehghani, cette méthode vise à repenser notre façon de traiter les données.
1. Découpage en Data Domains
Les Data Domains représentent le découpage au sein de l’entreprise (par métiers par exemple), chacun ayant ses propres données et ses responsabilités afférentes. En découpant les données en domaines, cela permet de réduire la complexité et améliorer l’efficacité de la gestion des données.
Avantages:
Simplification de la gestion des données.
Meilleure optimisation et exploitation des données.
Capacité à évoluer sans compromettre l’intégrité des données.
2. Data as a Product
Le concept de « Data as a Product » encourage les organisation à appréhender et traiter leurs données comme un produit. Ceci implique une équipe dédiée pour chaque ensemble de données, assurant sa qualité et sa pertinence tout au long de son cycle de vie.
Avantages:
Assure une qualité et fiabilité des données.
Favorise une culture d’ownership.
Optimise la valeur pour les consommateurs de données.
3. Self-Service Data Infrastructure as a Platform
Ce la représente la mise en place d’une infrastructure qui permet aux équipes d’accéder, de gérer et d’exploiter les données sans dépendre d’une équipe centrale.
Avantages:
Accélération de l’innovation.
Réduction des dépendances et silos.
Autonomie accrue pour les équipes de données.
Solutions éditeurs: Des acteurs comme Databricks, Snowflake et Redshift ont adopté cette approche et sont de plus en plus populaires.
4. Gouvernance Fédérée
En lieu et place d’une approche centralisée, la gouvernance fédérée vise à distribuer la gestion des données à travers l’organisation, équilibrant autonomie locale et directives globales.
Avantages:
Adaptabilité aux besoins spécifiques de chaque domaine.
Maintien d’une standardisation et cohérence globale.
Quels sont les avantages d’une architecture Data Mesh pour moderniser une plateforme décisionnelle ?
Choisir une architecture Data Mesh permet aux entreprises de moderniser leur plateforme décisionnelle en profondeur, en s’affranchissant avec des modèles centralisés traditionnels qui se révèlent très rigides et coûteux à faire évoluer. Cette approche architecturale permet une plus grande agilité, essentielle pour accompagner les transformations métiers.
ChezSmartpoint, en tant qu’expert en architecture data, nous observons que les organisations qui adoptent une architecture Data Mesh récoltent des bénéfices significatifs :
Décloisonnement des silos grâce à une gouvernance décentralisée mais cohérente
Responsabilisation des équipes métiers via des domaines data autonomes
Gain de temps dans la mise à disposition des données pour les utilisateurs
Scalabilité native, adaptée aux enjeux de volume et de diversification des sources de données
En tant qu’ESN spécialisée en Data et BI, nous accompagner entreprises dans l’intégration de ces principes dans leur système pour accélérer la modernisation de leurs plateformes BI et data, tout en s’alignant sur les standards en architecture BI moderne.
Quelles sont les limites des architectures data traditionnelles face aux enjeux actuels ?
Les architectures data traditionnelles de stockage, centrées autour de data lakes ou entrepôts centralisés, ont montré leurs limites structurelles face à la volumétrie croissante et à la diversité des cas d’usage. Ces limites freinent la modernisation BI et la valorisation rapide des données.
Voici les principaux écueils constatés pour nos architectes data chez nos clients :
Bottlenecks organisationnels : une équipe data centrale saturée
Manque de réactivité métier : lenteur dans l’accès aux données pertinentes
Coût élevé de maintenance des plateformes décisionnelles monolithiques
Faible alignement entre IT et métiers, ce qui nuit à la gouvernance
L’approche Data Mesh vient précisément répondre à ces limites en proposant une architecture data distribuée, fédérée et orientée produit. Chez Smartpoint, nous sommes convaincus que la modernisation des plateformes BI et Data repose avant tout sur une stratégie data fondée sur des fondations solides et durables.
Le Data Mesh est une tendance de fond en architecture de données car elle représente une approche novatrice c’est une réponse aux défis croissants que pose la gestion des données à grande échelle. Elle permet aux organisation d’entrer réellement dans une nouvelle ère Data-Centric.
Vous souhaitez repenser votre architecture de données ? Vous souhaitez savoir quelles alternatives d’offrent à vous ? Vous avez besoin d’accompagnement sur le sujet ? Challengez-nous !
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels, Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Architecture
Pourquoi avez-vous besoin d’un Architecte Solutions ?
0 commentaires
Dans un monde de plus en plus digitalisé, chaque entreprise cherche à innover et à optimiser ses processus en continu. Mais comment vous assurer que cette transformation numérique s’aligne parfaitement avec vos objectifs business ? C’est là qu’intervient l’architecte de solutions.
L’allié de votre transformation digitale
Un architecte de solutions n’est pas qu’un simple professionnel en ingénierie. Il est le lien entre vos ambitions business et les solutions technologiques les plus adaptées pour les réaliser. Il s’assure que chaque investissement technologique réalisé ait du sens pour votre entreprise et participe à la création de valeur.
L’expertise technologique au service du business
Avec l’évolution effrénée des nouvelles technologies, vous avez besoin de vous entourer d’un spécialiste qui les maîtrise, connait leur réelle maturité et sait comment elles peuvent être mises en pratique dans votre contexte d’entreprise particulier afin de vous donner un avantage concurrentiel.
La fluidification de la communication entre les métiers et les « techniciens de l’informatique »
L’architecte de solutions facilite la communication entre les équipes techniques et les métiers. Il s’assure que chaque décision est prise en connaissance de cause et qu’elle répond précisément aux besoins exprimés, ce qui l’amène souvent à les reformuler pour qu’ils soient effectivement partagés par tous.
La maîtrise des risques
De la compliance règlementaire à la sécurisation, l’architecte de solutions identifie, évalue et anticipe les risques liés à toutes les initiatives technologiques ou introduction de nouvelles technologies au sein de votre écosystème IT.
Le bon choix technologique
Que vous souhaitiez migrer vers le cloud, intégrer de nouvelles applications ou renforcer votre cybersécurité, l’architecte de solutions s’assure que la pile technologique choisie est la meilleure pour vous en fonction de votre existant mais aussi de vos ressources disponibles. Il vous propose également la bonne stratégie et la trajectoire de transformation technologique.
Le profil type d’un architecte solution
En raison des multiples dimensions de son poste et la diversité de ses missions au quotidien, il a à la fois des compétences techniques solide, une véritable vision stratégique et des qualités interpersonnelles indispensables.
Expériences : C’est un professionnel expérimenté qui a souvent commencé sa carrière comme développeur ou ingénieur système suivi d’une expérience en conseil. Il a généralement plusieurs certifications dont AWS Certified Solution Architect et/ou Azure Solutions Architect Expert.
Connaissances techniques : il maîtrise bien entendu toutes les dernières tendances en architectures data modernes (data fabric, data mesh, lakekouse, etc.), le cloud, l’intelligence artificielle, etc. Il a de l’expérience dans l’intégration de différentes plateformes et de technologies pour être en capacité d’être force de recommandations pour réconcilier des systèmes disparates. Il connait tous les principes de sécurité pour assurer la protection des données et la sécurisation des systèmes.
Compétences en gestion de projet : Gestion et coordination d’équipe sont ses points forts ! Il est le garant du budget (suivi des dépenses et ROI projet) et de la gestion des risques afin d’identifier précocement les éventuels problèmes (anticipation).
Vision stratégique : il est en capacité de traduire des besoins métiers ou des attentes métiers en solutions technologiques. Il sait également anticiper et proposer des solutions évolutives dans la durée.
Qualités : C’est un communiquant qui sait expliquer des concepts complexes à des interlocuteurs souvent néophytes. C’est un négociateur qui sait trouver des compromis entre des partie prenantes qui ont souvent des intérêts divergents. Et il s’épanouit dans le travail en équipe !
Un architecte de solutions a un rôle pivot dans toute entreprise qui souhaite mener à bien sa transformation numérique. Sa capacité à jongler entre des compétences techniques pointues, une vision stratégique claire et une communication efficace en fait un atout inestimable pour toute organisation.
Besoin de renfort dans vos projets, challengez-nous !
Architecture
Architectures data modernes : data warehouse, data lake et data lakehouse, quelle approche adopter ?
0 commentaires
Dans un monde moderne qui produit sans cesse des données qui nourrissent en continu ses économies, faire le bon choix en terme d’architecture est essentiel pour capter, gérer, analyser et exploiter les données. Les architectures de données ont beaucoup évolué pour répondre à ces nouveaux besoins sur des volumétries jamais atteintes jusqu’alors et des systèmes qui demandent de plus en plus de traitement temps réel. Voici un selon nous les architectures data les plus modernes en 2024.
La réponse ne peut plus reposer sur une seule approche. Les architectures data modernes doivent être modulaires, évolutives et capables d’intégrer des logiques d’automatisation via l’AIOps.
Dans ce contexte, l’architecte data joue un rôle central : il articule vision métier, contraintes techniques et exigences de gouvernance. Architectures Data Modernes & AIOps : Data Mesh, Lakehouse, Data Fabric, quelle architecture choisir en 2024 ?
Choix en architectures de données modernes
Le Data Lake, le socle historique, à repenser
Le Data Lake a longtemps été la solution privilégiée pour centraliser les données brutes. Il répond à un besoin de volume et de stockage low cost. Mais sans gouvernance, il devient rapidement un « data swamp », difficile à exploiter.
Le Lakehouse, un compromis entre performance et gouvernance
L’architecture Lakehouse combine les atouts du Data Lake et du Data Warehouse. Elle permet de traiter à la fois des workloads analytiques et des pipelines data intensifs. En termes de technologies, nous utilisons chez Smartpoint Delta Lake, Apache Iceberg, Snowflake, etc.
Avantages : unification, gouvernance, performance
Limites : encore jeune, nécessite une montée en compétences
Le Data Mesh, vers une architecture orientée data products
Le Data Mesh rompt radicalement avec le modèle centralisé et nos experts misent tout sur cette architecture de nouvelle génération ! Vous pouvez lire notre artciles sur le Data Mesh et ses fondamentaux ici. Chaque domaine métier devient responsable de ses “data products”. L’approche repose sur quatre piliers :
Limites : transformation culturelle, gouvernance plus complexe
L’AIOps Architecture, vers une automatisation intelligente !
L’architecture AIOps intègre des techniques d’intelligence artificielle pour automatiser l’observabilité, la détection d’incidents, la remédiation et le monitoring temps réel des infrastructures et des flux de données.
Nul doute qu’elle va s’imposer comme un complément indispensable des architectures data modernes, en particulier dans des environnements SI hybrides et cloud-native.
Avantages : fiabilité, anticipation des incidents, scalabilité automatique
Limites : complexité d’implémentation, dépendance à des modèles
Quels critères pour choisir la bonne architecture Data IA ?
Aligner stratégie d’architecture avec cas d’usages
Nos architectes data le constatent tous les jours dans la réalité des SI Data de nos clients. Le bon choix d’architecture de données repose sur une analyse des cas d’usage, des contraintes techniques, de votre SI Data et de la maturité Data globale de votre organisation.
Pour schématiser en fonction des priorités :
Gouvernance renforcée → Lakehouse ou Data Mesh
Cas d’usage IA → AIOps + Lakehouse
Organisation distribuée → Data Mesh
L’architecte data : un rôle clé pour 2024
Le data architecte n’est plus là pour faire des schémas directeurs, il intervient beaucoup plus en amont sur votre chantier de modernisation de votre architecture de données. Il traduit les enjeux métiers en modèles data, intègre la durabilité dans ses choix d’architecture, pilote les interactions entre cloud / IA / data et gouvernance et enfin il intègre les principes d’AIOps pour fiabiliser les environnements.
Comment construire une architecture data pérenne ?
Chez Smartpoint, nous accompagnons les DSI, les directions Data et les architectes dans la conception, l’implémentation et l’évolution de leurs architectures de données, en veillant à aligner les besoins des métier, les contraintes techniques, la stack existante et les impératifs de gouvernance.
Après un diagnostic de l’existant afin d’évaluer la maturité de l’organisation, les performances des environnements en place et le niveau de structuration de la gouvernance des données ; nous vous recommandons une architecture Data sur mesure, adaptées aux cas d’usage et à l’écosystème IT. Ces recommandations s’appuient sur des approches comme le Data Lakehouse, le Data Mesh ou des architectures intégrant des principes d’AIOps.
Une fois l’architecture cible définie, nous assurons sa mise en production en respectant les impératifs de performance, d’évolutivité et de scalabilité. Nous accompagnons également les équipes internes, data owners, architectes, DevOps, afin de nous assurer de l’appropriation des modèles mis en place et leur adoption durable dans les pratiques de l’entreprise.
Concevoir des architectures de données modernes, évolutives, gouvernées et automatisées, capables de soutenir durablement la performance et la création de valeur à l’échelle de l’organisation; c’est notre métier en tant qu’ESN spécialisée en ingénierie des données.
Vers des architectures intelligentes, au service de la valeur
Les architectures data modernes doivent répondre à aux maitres mots que sont l’agilité et la maîtrise.
Intégrer des logiques d’AIOps, favoriser des approches domain-centric comme le Data Mesh, ou unifier les flux via un Lakehouse sont autant de ressors pour créer de la valeur à l’échelle.
En 2024, l’architecte data devient un stratège : il conçoit des environnements data solides, adaptés aux enjeux métiers comme technologiques, dans une logique cloud-native, automatisée et gouvernée.
Data Warehouse, Data Lake et Data Lakehouse : comment choisir l’architecture adaptée ?
Les entreprises doivent aujourd’hui gérer une grande diversité de types de données : structurées, semi-structurées et non structurées. Le choix de l’architecture data moderne conditionne directement la qualité des données, leur exploitation en data science et les usages analytiques tels que la business intelligence (BI).
Le data warehouse cloud reste privilégié pour l’analytique et le reporting, grâce à sa capacité à organiser et fiabiliser les données structurées.
Le data lake (ou lac de données) se démarque par sa flexibilité et sa capacité de stockage de données massives, mais requiert une gouvernance rigoureuse pour éviter l’effet “data swamp”.
Le data lakehouse émerge comme une alternative hybride, combinant la puissance transactionnelle (transactions ACID) et analytique du warehouse avec la souplesse du data lake.
Le choix dépendra de plusieurs facteurs :
La prise en charge des données non structurées,
Les besoins en scalabilité et performance analytique,
La nécessité de garantir la traçabilité et la conformité réglementaire,
L’intégration avec les pratiques de data governance et les outils de traitement cloud-native.
Quelle architecture data adopter ?
La question n’est plus de savoir si un data warehouse ou un data lake est meilleur, mais de déterminer quelle combinaison d’architectures permet de répondre aux besoins spécifiques de l’entreprise.
Le data warehouse continue de jouer un rôle central dans la business intelligence (BI) et la fiabilité des rapports. Le data lake, de son côté, facilite la gestion des données non structurées et alimente les projets de data science. Enfin, le data lakehouse s’impose comme un modèle innovant, capable de concilier stockage de données, analytique avancée et qualité des données grâce à des mécanismes robustes comme les transactions ACID.
Pour les DSI et responsables data, la clé est de bâtir une stratégie d’architecture data moderne flexible, intégrant ces briques de manière cohérente, afin de soutenir la transformation numérique, l’innovation et la prise de décision.
Le choix de la bonne architecture de données dépend de vos besoins spécifiques. Que ce soit le Data Mesh, la Data Fabric ou le Lakehouse, chaque option a ses propres intérêts qui peuvent servir votre stratégie d’exploitation des données. Chez Smartpoint, nos architectes vous conseillent car être en capacités de comprendre les différentes architectures de données est primordial afin de concevoir et mettre en œuvre des systèmes data efficaces : traitement par lots, traitement en flux, architecture Lambda, entrepôt de données, le lac de données, microservices, (…)
Architecture
Data Mesh, architecture miracle pour libérer enfin la valeur promise des data ?
0 commentaires
Au-delà du concept et des principes d’architecture, est-ce que le Data Mesh est viable à l’épreuve de réalité des organisations et des SI data ? Est-ce que cette architecture décentralisée et orientée domaine fonctionnel, qui permet une exploitation des données en libre-service, est la hauteur des promesses ?
Voici les principaux écueils à anticiper.
En tant que pure-player de la Data, nous en avons connu chez Smartpoint des architectures de données … Et nous savons à quel point il est complexe de trouver, de concevoir, de mettre en œuvre la bonne solution et de briser enfin les silos. On sait aujourd’hui qu’environ 80% des projets de Data Warehouses ont échoué et il y a déjà presque 10 ans, Gartner prédisait que 90% des Data Lakes seraient finalement inutiles. Il est vrai aussi que l’on sait qu’une équipe Data centralisée est souvent débordée et manque d’expertises par domaines métiers, ce qui nuit invariablement à la découverte et à la création de valeur data.
1. Domain-driven ownership of data : Les données sont considérées comme des actifs appartenant à des domaines spécifiques au sein de l’organisation. Chaque domaine est responsable de la production, de l’amélioration de la qualité des données et de la gestion. Cette approche permet de créer des équipes spécialisées, composées d’experts métier et techniques, qui travaillent en étroite collaboration pour définir les normes et les règles spécifiques à leur domaine. Leur objectif est de répondre aux besoins de leur domaine fonctionnel en terme d’exploitation des données, tout en favorisant la réutilisation et l’interopérabilité entre les différents domaines métiers.
2. Data as a product : Les données sont destinées à être consommées par les utilisateurs au sein de l’organisation. Les équipes data doivent se recentrer sur le client pour fournir des data sets de qualité, fiables et bien documentés. Elles créent des interfaces claires (API) et définissent des contrats pour la consommation des données. Ainsi, les utilisateurs peuvent découvrir, accéder et utiliser les données de manière autonome, comme un produit prêt à l’emploi. On est dans la même logique que les architectures microservices.
3. Self-service data platform : Les équipes data fournissent une plateforme de données en libre-service, qui facilite la découverte, l’accès et l’exploitation des données. Cette plateforme fournit des outils, des services et des interfaces qui permettent aux utilisateurs de trouver intuitivement et de consommer les données de manière autonome. Elle favorise l’automatisation et l’orchestration des flux de données, permettant ainsi aux équipes data de se concentrer sur la qualité et l’enrichissement des données plutôt que sur des tâches opérationnelles chronophages et à faible valeur ajoutée.
4. Federated computational governance : La gouvernance des données est décentralisée et répartie entre les différentes équipes. Chaque équipe a la responsabilité de définir et d’appliquer les règles et les normes spécifiques à son domaine. La gouvernance fédérée consiste à mettre en place des processus et des outils qui permettent de gérer et de contrôler les données de manière distribuée. Cela inclut la gouvernance des métadonnées, la sécurité, la conformité réglementaire, ainsi que la prise de décision collective et transparente sur les évolutions de l’architecture et des pratiques liées aux données.
Voici pourquoi une architecture data mesh pourrait se révéler être un échec dans certaines organisations où les notions de produit data ou de propriété de domaines sont difficilement applicables.
Toutes les données n’ont pas forcément une valeur, c’est même le contraire. La plupart des données collectées sont inutiles et brouillent l’information car elles ne sont pas pertinentes. Dans les faits, c’est compliqué d’identifier dans la masse celles qui sont réellement précieuses et potentiellement génératrice de valeur. C’est un véritable chantier en soi, complexe et laborieux. Un travail de chercheur d’or !
Produire des données est une charge supplémentaire ! Certes le concept de data product est séduisant et facile à appréhender mais dans la réalité du terrain, les ingénieurs data doivent déjà les créer … Et les transformer en plus par domaine nécessite d’élargir encore leurs compétences. Certes les avancées en IA, automatisation, et autres Low Code promettent de leur faciliter la tâche mais c’est encore une promesse qui reste à éprouver.
On en vient naturellement à la troisième difficulté : le manque de compétences data disponibles. Le Data Engineering, c’est un métier de spécialiste de la gestion des données et nous savons qu’il est rare de trouver des professionnels qui en maîtrise toute la palette ! Déléguer la responsabilité à des équipes par domaine, sans compétences spécialisées en data, peut générer des problèmes sans aucun doute.
La gouvernance fédérée est aussi une évidence sur le papier. Dans les faits, ce n’est pas applicable sans de fortes contraintes avec un véritable régime central très autoritaire qui encadre les comportements et contrôle régulièrement les usages. En effet, si la gouvernance des données est détenue par une guilde fédérée composées de représentants de différents domaines, cela risque fortement d’être inefficace car chaque département a ses propres règles et priorités.
Une plateforme centralisée en libre-service fait rêver mais dans les faits, mettre en place ce type de solution se révèle très complexe car on est confronté à une variété vertigineuse de formats de données, une pluralité de systèmes et d’applications différents, de différentes versions voire de générations. Certes, nous disposons aujourd’hui de nombreux outils pour ingérer massivement les données et de larges bibliothèques de connecteurs … mais on peut rapidement retomber dans les travers du data warehouse.
Pour conclure, une architecture Data Mesh est très intéressante, mais au là du concept, il faut en mesurer les risques, les écueils et ses limites.
Voici les principaux avantages qui méritent qu’on étudie sa faisabilité et sa mise en pratique dans votre SI Data :
Démocratisation de l’exploitation des données par un plus grand nombre (au delà des data scientist) via les applications en libre service
Réduction des coûts car cette architecture distribuée est davantage #Cloud native avec des pipeline de collecte des données en temps réel (paiement à la consommation en terme de stockage)
Interopérabilité car les données sont normalisées indépendamment du domaine et les consommateurs s’interfacent par APIs.
Renforcement de la sécurité et de la gouvernance des données car les normes sont appliquées au-delà du domaines ainsi que la gestion des droits et des accès (journalisation, observabilité).
Back to the basics ! Zoom sur les différences entre un data warehouse dans le cloud, un data lake et data lakehouse.
0 commentaires
Un data Warehouse est une base de données analytique centralisée qui stocke les données déjà structurées. Il est utilisé par des analystes qui maîtrisent parfaitement le langage SQL et savent donc manipuler les données. Les données sont optimisées et transformées pour être accessibles très rapidement à des fins d’analyses, de génération de rapports et des tableaux de bords de pilotage des entreprises.
Un data lake collecte et stocke lui aussi des données mais il a été conçu pour traiter les Big Data, c’est-à-dire pour de fortes volumétries de données brutes, non structurées ou semi-structurées. Les data lakes sont à privilégier dans le cas d’un traitement en continu et d’une gestion en temps réel des données. Les données sont généralement stockées en prévision d’une utilisation ultérieure. Comme elles sont de natures brutes et non traitées, il est nécessaire de faire appel à un Data Scientist lorsqu’on souhaite les exploiter. Généralement, le datalake est utilisé pour le traitement par lots. Il permet notamment l’utilisation d’ELT en libre-service (par ex Informatica) pour automatiser l’ingestion et le traitement des données, ce qui permet de réduire la complexité de la conception et la maintenance des pipelines de données.
Un data Lakehouse, c’est une nouvelle architecture qui réconcilie en théorie le meilleur des deux mondes entre l’entrepôt de donnée et le data lake en une seule plateforme ! Le data lakehouse permet d’éviter la multiplication des moteurs de requêtes en exécutant des analyses directement dans le data lake lui-même.
À suivre ? les solutions proposées par Databricks …
Data Lake, Data Lakehouse et Lake Data : des architectures au service de la valorisation des données
Les entreprises collectent aujourd’hui des volumes croissants de données hétérogènes. Face à cette complexité, plusieurs modèles d’architecture coexistent et se complètent : data warehouse cloud, data lake, data lakehouse et ce que certains acteurs désignent sous le terme de lake data.
Le data lake est conçu pour stocker des données brutes, structurées et non structurées, à faible coût et en grande quantité. Il constitue une base flexible, mais nécessite des mécanismes de gouvernance et de qualité pour rester exploitable.
Le data lakehouse combine les avantages du data lake (souplesse, scalabilité) et du data warehouse (structuration, performance analytique). Il permet de réduire la duplication des données et d’accélérer les projets de machine learning et d’analytique avancée.
Le concept de lake data désigne une approche centrée sur l’accessibilité et la disponibilité de la donnée dans un écosystème unifié, mettant en avant la capacité à interroger et exploiter directement les données stockées dans un lac.
Quels avantages pour les entreprises ?
Réduction des coûts : grâce au stockage optimisé et à la scalabilité des solutions cloud-native,
Agilité analytique : possibilité de combiner exploration des données brutes et analyses BI structurées,
Accélération de l’IA et du machine learning : accès direct à des données diversifiées et mieux gouvernées,
Souveraineté et conformité : alignement avec les réglementations (RGPD, Data Governance Act) grâce à des architectures hybrides ou souveraines.
Vers une convergence des architectures
Au-delà du débat entre architecture data warehouse, data lake et data lakehouse, les entreprises doivent surtout bâtir une stratégie de gestion des données qui assure la prise en charge de l’ensemble des types de données, qu’elles soient structurées ou non structurées, tout en garantissant la qualité des données sur toute la chaîne de valeur.
Le data lake (ou lac de données) se distingue par sa capacité de stockage de données massives et hétérogènes, mais il exige une gouvernance solide pour rester exploitable dans les projets d’analyse des données et de data science. Le data warehouse, de son côté, continue de jouer un rôle central pour la business intelligence (BI) et le reporting opérationnel.
Le data lakehouse émerge comme une réponse hybride : il combine la souplesse du lac de données avec la puissance analytique du warehouse, tout en supportant des fonctionnalités avancées comme les transactions ACID, essentielles pour fiabiliser les traitements et sécuriser la cohérence des informations.
Pour les DSI et responsables data, le véritable enjeu n’est plus de choisir une approche unique, mais de créer une architecture data unifiée qui intègre la scalabilité du data lake, la robustesse analytique du data warehouse et l’innovation du data lakehouse. Ce modèle hybride permet de maximiser la valeur des données, de fiabiliser la prise de décision et de soutenir les nouveaux usages liés à l’IA et à la transformation numérique.
Évaluation Smartpoint sur les architectures Data Lake et Lakehouse
Note : 4.6 / 5
Les architectures data lake et data lakehouse permettent de traiter de grands volumes de données dans des environnements flexibles et scalables. Le data lakehouse, en particulier, combine la puissance analytique du data warehouse avec la flexibilité du data lake. Chez Smartpoint, nous considérons ces approches comme essentielles pour moderniser les plateformes de données et gagner en agilité analytique.
Architecture
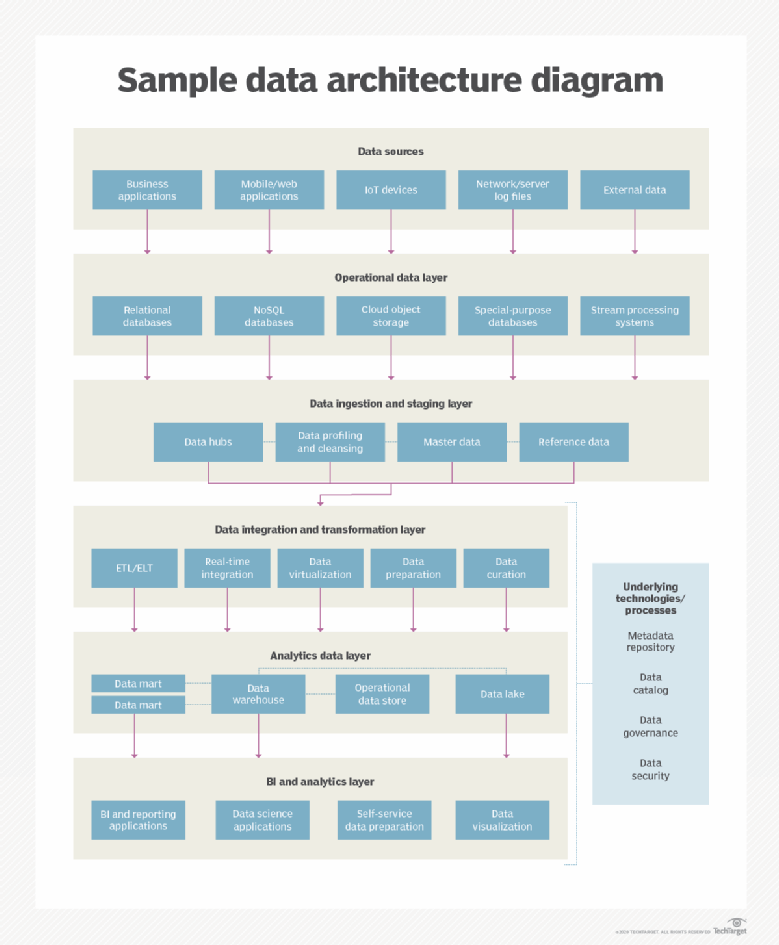
Zoom sur l’architecture de données et son corolaire, la modélisation des données
0 commentaires
L’objectif est de documenter tous les data assets de l’organisation, de les cartographier afin de voir comment ils circulent dans vos systèmes afin d’obtenir un schéma directeur.
La schéma directeur va donner le cadre sous-jacent aux plateformes de données qui alimentent également les outils de gestion de données. Il va permettre aussi de spécifier les normes pour la collecte, l’intégration, la transformation et le stockage de données. Aujourd’hui, on utilise de plus en plus des systèmes de streaming de données en temps réel et on prend en charge désormais les applications d’IA/ML en plus de la BI traditionnelle.
Le développement du cloud a encore apporté une couche de complexité aux architectures de données. Autre concept émergeant, la Datafabric ! Enfin, l’architecture de données doit prendre en considération la conformité règlementaire et la gouvernance des données.
Une bonne conception doit être :
Orientée métier pour être alignée sur l’organisation et les besoins
Flexible et évolutive
Fortement sécurisée pour interdire les accès non autorisés et les utilisations abusives
Ses composants ? Des modèles de données avec des référentiels communs, des diagrammes et des flux de données pour comprendre comment circulent les données dans les systèmes et les applications qui les consomment, des documents qui normalisent comment les données sont collectées, intégrées et stockées.