L’architecture microservices et orientée événements est devenue une approche privilégiée par les entreprises qui souhaitent améliorer leur agilité et leur réactivité dans la gestion de leurs données. En fragmentant les composants de la gestion des données en services indépendants et en utilisant des événements pour la communication, cette architecture permet de répondre rapidement aux changements et d’intégrer facilement de nouvelles technologies. Cette approche combine les avantages de la granularité et de la flexibilité des microservices avec la réactivité et le découplage des architectures orientées événements.
1. Définition et principes des microservices et de l’architecture orientée événements
Microservices dans les architectures de données : Les microservices en architectures de données sont une approche où les fonctionnalités liées à la gestion des données sont décomposées en services indépendants et autonomes. Chaque microservice est responsable d’une tâche spécifique, telle que l’ingestion des données, la transformation, le stockage, ou l’analyse. Ces microservices communiquent entre eux via des API bien définies, permettant une flexibilité inégalée dans la gestion des flux de données.
Architecture orientée événements : Dans une architecture orientée événements appliquée aux données, les services communiquent par le biais de messages ou d’événements. Lorsqu’un événement lié aux données survient (par exemple, une nouvelle donnée est ingérée, une transformation est terminée), un message est publié sur un bus de messages et les microservices concernés réagissent en conséquence. Cela permet de traiter les données de manière asynchrone et décentralisée, favorisant ainsi une grande réactivité et flexibilité.
Une architecture orientée événements est une approche qui utilise des événements pour modéliser et gérer les flux de données. Les événements sont des unités d’information encapsulées qui décrivent des changements dans l’état du système. Ils sont généralement composés de trois éléments clés :
Un identifiant unique
Un horodatage
Des données d’événement
Les événements sont produits par des sources de données, telles que des capteurs, des applications ou des systèmes transactionnels. Ils sont ensuite transmis à des intermédiaires d’événements, qui les stockent et les distribuent aux consommateurs d’événements. Les consommateurs d’événements peuvent être des applications d’analyse, des tableaux de bord ou des systèmes de traitement de flux.
2. Avantages des microservices et de l’architecture Orientée événements dans la gestion de vos data
Flexibilité et scalabilité : Les microservices permettent de traiter les différentes étapes de la gestion des données (ingestion, transformation, stockage, analyse) de manière indépendante. Cette modularité facilite l’extension et l’amélioration des capacités de traitement des données selon les besoins, sans impact sur l’ensemble du système data. C’est également plus évolutifs car ces architectures peuvent gérer de grands volumes de données en temps réel sans nécessiter de modifications majeures de l’infrastructure.
Déploiement et maintenance simplifiés : Grâce à la nature décentralisée des microservices, les mises à jour et les déploiements peuvent être effectués indépendamment pour chaque service. Cela réduit les risques d’interruption et permet d’implémenter rapidement des améliorations, des correctifs ou encore des nouvelles technologies.
Réactivité et temps réel : Les architectures orientées événements permettent de réagir instantanément aux changements de données. Par exemple, une nouvelle donnée ingérée peut déclencher des processus de transformation et d’analyse immédiatement, alimentant ainsi des insights en temps réel.
3.USAGES
Deux cas d’utilisation des microservices et de l’architecture orientée événements en systèmes Data
E-commerce : Les plateformes e-commerce peuvent utiliser des microservices pour gérer l’ingestion des données clients, le suivi des transactions, la gestion des stocks, et les recommandations de produits. Une architecture orientée événements permet de réagir rapidement aux comportements des clients et aux variations de stock en temps réel.
Finance : Les institutions financières utilisent cette architecture pour surveiller les transactions en temps réel, détecter les fraudes et se conformer aux régulations. Par exemple, chaque transaction est traitée comme un événement, ce qui déclenche des vérifications et des analyses en temps réel.
4. Technologies et outils pour les architectures Microservices et orientées Événements
Conteneurs et orchestration : Les conteneurs comme Docker et les outils d’orchestration comme Kubernetes sont essentiels pour déployer et gérer les microservices de manière efficace. Ils permettent de standardiser l’environnement de déploiement et de gérer les ressources de manière optimale pour les services de données. Citons également Apache Airflow et Prefect pour l’orchestration des workflows ou encore Luigicomme une alternative plus simple pour certaines tâches de traitement des données.
Bus de Messages : Les bus de messages tels qu’Apache Kafka, RabbitMQ et AWS SQS sont utilisés pour la communication asynchrone entre les microservices. Ils garantissent que les messages de données sont livrés de manière fiable et que les services peuvent réagir aux événements en temps réel. Citons également Azure Service Bus pour les environnements Azure et Google Pub/Sub pour les environnements GCP.
Frameworks de développement : Des frameworks comme Spring Boot pour Java, Flask pour Python, et Express pour Node.js simplifient la création de microservices de données. Citons également FastAPI pour Python, qui gagne en popularité chez nos développeurs en raison de ses performances et de sa simplicité. Ils fournissent des outils et des bibliothèques pour gérer les API, la sécurité et l’intégration avec d’autres services de données.
5. Bonnes pratiques pour l’implémentation des Microservices et d’une architecture orientée événements
Conception granulaire : Chaque microservice doit être conçu pour une fonctionnalité de données spécifique et autonome, comme l’ingestion, la transformation ou l’analyse. Cette granularité facilite la gestion et l’évolution des services.
Monitoring et Log Management : La surveillance continue et la gestion des journaux sont essentielles pour détecter les problèmes et optimiser les performances des microservices de données. Des outils comme Prometheus, Grafana et la ELK Stack (Elasticsearch, Logstash, Kibana) sont couramment utilisés pour cela. Citons également Jaeger ou Zipkin pour le traçage distribué, ce qui est crucial pour déboguer et surveiller les architectures microservices.
Sécurité et gestion des accès : La sécurité doit être intégrée dès la conception. L’utilisation de protocoles d’authentification et d’autorisation robustes, comme OAuth2, OpenID Connect (OIDC) et JWT (JSON Web Tokens), est recommandée pour protéger les API de données et assurer la confidentialité et l’intégrité des données.
Quelles différences entre une architecture microservices orientée événement et le Data Mesh ?
Il est vrai que les concepts d’architecture microservices, d’architecture orientée événements et de data mesh partagent de fortes similitudes, notamment en termes de décentralisation et de modularité. Cependant, il existe des différences clés entre ces deux approches.
Architecture Microservices et Orientée Événements
Définition : Les microservices sont des composants logiciels autonomes, chacun étant responsable d’une fonctionnalité spécifique. L’architecture orientée événements repose sur la communication asynchrone via des messages ou des événements pour coordonner les microservices.
Modularité : Les microservices décomposent les applications en services indépendants, facilitant la gestion, la mise à l’échelle et le déploiement. Ils sont souvent utilisés pour créer des pipelines de traitement de données flexibles et évolutifs.
Communication : L’architecture orientée événements utilise des bus de messages pour permettre la communication entre les microservices. Cela permet de réagir en temps réel aux événements.
Focus : Cette approche se concentre sur la flexibilité, la scalabilité et la rapidité de déploiement des applications et des services de données.
Data Mesh
Définition : Le data mesh est une approche décentralisée de la gestion des données, où les données sont considérées comme des produits. Chaque domaine métier est responsable de ses propres produits de données et les gère comme une équipe produit.
Décentralisation : Contrairement à une architecture centralisée de données, le data mesh répartit la responsabilité de la gestion des données entre différentes équipes, chacune étant propriétaire de son propre domaine de données.
Propriété des Données : Dans un data mesh, chaque équipe de domaine est responsable de la qualité, de la gouvernance et de la disponibilité de ses données. Cela encourage une approche plus collaborative et responsabilisée.
Interopérabilité : Le data mesh favorise l’interopérabilité entre les domaines grâce à des contrats de données et des interfaces standardisées.
Focus : Cette approche met l’accent sur la décentralisation de la gestion des données pour améliorer l’agilité organisationnelle, la qualité des données et la réactivité aux besoins métiers.
Les architectures microservices et orientées événements offrent une flexibilité et une réactivité sans précédent pour la gestion de vos data. En adoptant cette approche, les entreprises peuvent améliorer leur agilité, leur scalabilité et leur capacité à innover dans le traitement et l’analyse des données.
Chez Smartpoint, nous sommes convaincus que cette architecture représente l’avenir des systèmes de gestion de données, capables de répondre aux défis croissants de la transformation numérique. Challengez-nous !
Vous vous interrogez sur quelle architecture data adopter ? Challengez-nous !
Les champs obligatoires sont indiqués avec *.
Architecture
Choisir une architecture data modulaire ?
0 commentaires
1. Définition et principes d’architecture
L’agilité la capacité à évoluer très rapidement – voir de « pivoter » – ne sont plus aujourd’hui l’apanage des startups. Toutes les entreprises doivent s’adapter, réagir et innover constamment pour exister sur leurs marchés. On évoque souvent la nécessite d’avoir un système d’information agile, l’architecture de données modulaire est son pendant.
Ce modèle architectural, qui s’oppose à la rigidité des systèmes monolithiques traditionnels, est basé sur la conception de composants autonomes ou modules indépendants qui peuvent interagir entre eux à travers des interfaces prédéfinies. Chacun est dédié à une fonctionnalité data spécifique qui couvre un aspect de la chaine de valeur. Cette approche fragmente le système en sous-ensembles de tâches, ou de modules, qui peuvent être développés, testés et déployés de manière indépendante :
Collecte & ingestion des données, processus dynamique qui prend en charge divers formats, en temps réels ou en lots
Traitement et transformation, exécution d’opération comme le nettoyage, le redressement ou l’enrichissement des données, l’application de règles métiers, la conversion dans d’autres formats
Organisation et stockage selon les performances attendues, en data lake, en base de données opérationnelle, en data warhouse ou solution de stockage hybride
Analyse et restitution, pour le calcul de KPI, l’exécution de requêtes, l’utilisation de l’IA pour obtenir des insights, la génération de rapports, etc.
Sécurité et conformité, pour la gestion de l’authentification et des accès, le chiffrement (…) mais aussi la compliance auditable avec toutes les règlementations en vigueur dont RGPD
Cette architecture modulaire offre aux entreprises la possibilité de mettre à jour, de remplacer ou de dé-commissionner des composants distincts sans impacter le reste du système Data. En d’autres termes, une architecture de données modulaire est semblable à un jeu de legos où l’on peut ajouter, retirer ou modifier des blocs selon les besoins, sans devoir reconstruire l’ensemble de la structure.
La flexibilité en priorité
La quantité de données générées et collectées par les entreprises a explosé littéralement et les volumes sont exponentiels, tout comme la variété des formats et la vitesse de traitement requise. Les systèmes d’information (SI) doivent plus que jamais être en capacités de s’adapter rapidement à ces nouvelles exigences. Hors le poids du legacy reste le frein numéro 1. Lors des chantiers de modernisation des SID (Système d’information décisionnel historiques) ; le choix d’une architecture modulaire est de plus en plus populaire et pour cause.
Les architectures modulaires répondent à ce besoin impérieux de flexibilité sur des marchés très concurrencés, mondiaux et volatiles. C’est un choix qui permet une meilleure réactivité face à l’évolution très rapides des besoins métiers, des innovations technologiques ou des changements stratégiques. Ces architectures sont nativement conçues pour une intégration facile de nouvelles technologies, telles que le traitement en temps réel des données ou l’intelligence artificielle, tout en supportant les besoins croissants en matière de gouvernance et de sécurité des données.
Cette flexibilité est également synonyme de viabilité à long terme pour les systèmes d’information, offrant ainsi aux entreprises un avantage concurrentiel durable. En résumé, l’architecture de données modulaire n’est pas seulement une solution pour aujourd’hui, mais une fondation solide pour l’avenir.
2. Les avantages d’une architecture Data Modulaire
Une architecture Data modulaire répond aux enjeux de notre ère basée sur la prolifération des données mais pas que ! C’est aussi une réponse alignée sur une stratégie d’entreprise pour qui la flexibilité et l’innovation continue sont des impératifs.
2.1. Évolutivité et facilité de maintenance
La maintenance et l’évolution des SI sont des gouffres financiers, fortement consommateurs de ressources et souvent un frein à l’innovation. Une architecture data modulaire facilite grandement la tâche ! Un composant peut être mis à jour ou remplacé sans risquer d’affecter l’intégralité du système, ce qui réduit significativement les temps d’arrêt et les coûts associés. L’évolutivité et l’innovation sont intrinsèques : ajout de nouvelles fonctionnalités, remplacement, montée en charge, intégration de nouvelles sources de données, (…).
2.2. Agilité organisationnelle et adaptabilité
Dans notre écosystème résolument numérique, l’agilité est primordiale. En isolant les différentes fonctions liée la gestion des données dans des modules autonomes, les architecture data modulaire s’adaptent aux demandes et aux besoins par nature évolutifs. Cette structure permet non seulement d’intégrer rapidement de nouvelles sources de données ou des technologies émergentes ; mais aussi de répondre efficacement aux exigences réglementaires spécifiques à la data.
Exemples : Dans le cas des évolutions des normes de protection des données, le module dédié à la sécurité peut être mis à jour ou remplacé sans affecter les mécanismes de traitement ou d’analyse de données. De même, si une entreprise décide de tirer parti de nouvelles sources de données IoT pour améliorer ses services, elle peut développer ou intégrer un module d’ingestion de données spécifique sans perturber le fonctionnement des autres composants.
Cette adaptabilité réduit considérablement la complexité et les délais associés à l’innovation et à la mise en conformité, ce qui est fondamental pour conserver une longueur d’avance dans des marchés data-driven où la capacité à exploiter rapidement et de manière sécurisée de grandes quantités de données est un avantage concurrentiel qui fait clairement la différence.
2.3 Optimisation des investissements et des coûts dans la durée
L’approche « pay-as-you-grow » des architectures data modulaires permet de lisser les dépenses en fonction de l’évolution des besoins, sans donc avoir à engager des investissements massifs et souvent risqués. Cette stratégie budgétaire adaptative est particulièrement pertinente pour les entreprises qui cherchent à maîtriser leurs dépenses tout en les alignant sur leur trajectoire de croissance.
3. Architecture Modulaire vs. Monolithique
En ingénierie de la data, on distingue les architectures modulaires des systèmes monolithiques en raison de l’impact direct que leur structure même a sur l’accessibilité, le traitement et l’analyse des données.
3.1. Distinctions fondamentales
Les monolithiques fonctionnent comme des blocs uniques où la collecte, le stockage, le traitement et l’analyse des données sont intégrés dans une structure compacte ce qui rend l’ensemble très rigide. Ainsi, une modification mineure peut nécessiter une refonte complète ou de vastes tests pour s’assurer qu’aucune autre partie du système ne connait de régression.
Les architectures de données modulaires, quant à elles, séparent ces fonctions en composants distincts qui communiquent entre eux via des interfaces, permettant des mises à jour agiles et des modifications sans perturber l’ensemble du système.
3.2. Maintenance & évolution
Faire évoluer et maintenir un SID monolithique peut être très fastidieux car chaque modification peut impacter l’ensemble. En revanche, dans le cas d’une architecture de données modulaire, l’évolution se fait composant par composant. La maintenance est facilitée et surtout moins risquées.
Exemple : Le changement ou l’évolution du module Data Visualisation ne perturbe en rien le module de traitement des données, et vice versa.
3.3. Intégration des innovations technologiques
L’ingénierie de la data est foisonnante de changements technologique, les architectures modulaires offrent une meilleure adaptabilité. Elles permettent d’intégrer rapidement de nouveaux outils ou technologies telles que l’Internet des Objets (IoT), les data cloud platforms, les solutions d’IA, de machine Learning ou encore d’analyse prédictive ; alors qu’un système monolithique nécessite une refonte significative pour intégrer de telles solutions. Elles permettent l’intégration de technologies avancées telles avec plus de facilité et moins de contraintes.
Les architectures modulaires encouragent l’innovation grâce à leur flexibilité intrinsèque. Les équipes peuvent expérimenter, tester et déployer de nouvelles idées rapidement, contrairement au SID monolithique plus lourd et complexe à manipuler. Cette capacité d’adaptation est cruciale pour exploiter de nouvelles données, telles que les flux en temps réel ou les grands volumes de données non structurées.
Exemple : l’introduction d’un module d’apprentissage automatique pour l’analyse prédictive peut se faire en parallèle du fonctionnement normal des opérations, sans perturbation.
3.4. Évolutivité & performances
Les architectures de données modulaires peuvent être optimisées de manière granulaire au niveau des charges pour dimensionner les performances au plus juste des besoins ; et ce sans impacter les autres fonctions du système. Dans un système monolithique, augmenter la performance implique souvent de redimensionner l’ensemble du système, ce qui est moins efficace et surtout plus coûteux.
Contrairement aux systèmes monolithiques, où l’intégration de nouvelles technologies peut être un processus long et coûteux, les architectures modulaires sont conçues pour être évolutives et extensibles.
4. Architecture modulaire vs. microservices
4.1 différences entre une architecture data modulaire et une architecture microservices
Les deux termes peuvent en effet porter à confusion car ces deux types d’architecture sont basés sur la décomposition en modules autonomes mais l’un est orienté services, l’autre composants. Leurs pratiques de développement et de mise en opérations sont bien distincts.
Dans l’architecture data modulaire, chaque module représente une certaine capacité du système et peut être développé, testé, déployé et mis à jour indépendamment des autres.
Les microservices, en revanche, sont un type spécifique d’architecture modulaire qui applique les principes de modularité aux services eux-mêmes. Un système basé sur des microservices est composé de petits services autonomes qui communiquent via des API. Chaque microservice est dédié à une seule fonctionnalité ou un seul domaine métier et peut être déployé, mis à jour, développé et mise à l’échelle indépendamment des autres services.
4.2 Comment choisir entre architecture modulaire et microservices ?
Taille et complexité du projet : Les microservices, par leur nature granulaire, peuvent introduire une complexité inutile dans la gestion des petits entrepôts de données ; ou pour des équipes d’analyse de données limitées. Ils sont surdimensionnés pour les petits projets. Une architecture modulaire, avec des composants bien définis pour la collecte, le traitement et l’analyse, suffit largement.
Expertises des équipes data : Une architecture microservices nécessite des connaissances spécialisées sur l’ensemble de la chaine de création de valeur de la data, de la collecte à l’analyse, ce qui n’est pas forcément transposable sur des petites équipes ou composées de consultants spécialisés par type d’outils.
Dépendance et intégration : L’architecture modulaire gère mieux les dépendances fortes et intégrées, tandis que les microservices exigent une décomposition fine et des interfaces claires entre les services. Les architectures modulaires se comportent donc mieux quand les données sont fortement interdépendantes et lorsque des modèles intégrés sont nécessaires. Les microservices, quant-à-eux, sont plus adaptés quand on cherche une séparation claire et des flux de données autonomes, permettant ainsi des mises à jour très ciblées sans affecter l’ensemble du pipeline de données.
Performances et scalabilité : Les microservices peuvent être recommandés dans le cas de traitements à grande échelle qui nécessitent une scalabilité et des performances individualisées. En revanche, cela vient complexifier la gestion du réseau de données et la synchronisation entre les services.
Maintenance des systèmes de données : Bien que ces deux types d’architectures soient par natures évolutifs, les microservices facilitent encore davantage la maintenance et les mises à jour en isolant les changements à des services de données spécifiques. Cela peut réduire les interruptions et les risques d’erreurs en chaîne lors des mises à jour dans des systèmes de données plus vastes.
5. Cas d’usages et applications pratiques
Une architecture de données modulaire, avec sa capacité à s’adapter et à évoluer, est particulièrement recommandée dans des cas où la flexibilité et la rapidité d’intégration de nouvelles technologies sont essentielles. Elle est devenu est must-have pour les entreprises qui cherchent à maximiser l’efficacité de leurs systèmes d’information décisionnels.
Voici quelques exemples concrets et études de cas où ce choix s’impose.
Télécoms : Dans ce secteur, où les volumes de données sont gigantesques et les besoins de traitement en temps réel sont critiques, l’architecture modulaire permet d’isoler les fonctions de traitement et d’analyse de flux de données, facilitant une analyse et une prise de décision rapides sans perturber les autres systèmes.
Secteur de la santé – Gestion des dossiers patients : Une architecture modulaire est particulièrement efficace pour gérer les dossiers de santé électroniques dans les hôpitaux. Des modules autonomes traitent les entrées en laboratoires d’analyse, les mises à jour des dossiers médicaux et les ordonnances, permettant des mises à jour régulières du module de gestion des prescriptions sans perturber l’accès aux dossiers historiques des patients.
Banque et finance – Analyse de la fraude : Un de nos clients utilise un module d’analyse de fraude en temps réel sur son système de gestion des transactions financières. Ce module s’adapte aux nouvelles menaces sans nécessiter de refonte du système transactionnel entier, ce qui renforce la sécurité et réduit les failles de vulnérabilité.
Plateformes de streaming vidéo : Ces services utilisent des architectures modulaires pour séparer le traitement des données de recommandation d’utilisateurs des systèmes de gestion de contenu, permettant ainsi d’améliorer l’expérience utilisateur en continu et sans interrompre le service de streaming principal.
Fournisseurs de services cloud : Ils tirent parti de modules dédiés à la gestion des ressources, à la facturation et à la surveillance en temps réel pour offrir des services évolutifs et fiables, enrichis en solutions d’IA notamment innovations pour l’analyse prédictive de la charge serveur.
Études de cas sur les bénéfices des architectures modulaires vs. monolithiques :
E-commerce – Personnalisation de l’expérience client : Un de nos clients, plateforme de vente en ligne, a implémenté un module d’intelligence artificielle pour la recommandation de produits. Cette modularité a permis d’innover en incorporant l’apprentissage automatique sans avoir à reconstruire leur plateforme existante, augmentant ainsi les ventes croisées et additionnelles.
Smart Cities – Gestion du trafic : Une métropole a installé un système modulaire de gestion du trafic qui utilise des capteurs IoT pour adapter les signaux de circulation en temps réel. L’introduction de nouveaux modules pour intégrer des données de différentes sources se fait sans interruption du service, améliorant ainsi la fluidité du trafic et les prédictions.
Avantages et inconvénients de l’architecture modulaire en ingénierie des données :
Avantages
Agilité : Permet une intégration rapide de nouvelles sources de données, d’algorithmes d’analyse, etc.
Maintenabilité : Les mises à jour peuvent être opérées sur des modules spécifiques sans interruption de services.
Inconvénients
Complexité de l’intégration : L’implémentation peut demander des charges supplémentaires pour assurer l’intégration entre les modules.
Gestion des dépendances : Une planification rigoureuse est nécessaire pour éviter les conflits entre modules interdépendants.
5. Conception d’une Architecture de Données Modulaire
En ingénierie data, la conception d’une architecture modulaire nécessite une segmentation du pipeline de données en modules distincts et indépendants, chacun est dédié à une tâche précise dans la chaîne de valeur des données.
Les prérequis d’une architecture data modulaire :
Interopérabilité : Les modules doivent s’intégrer et communiquer entre eux facilement via des formats de données standardisés et des API bien définies. Cette étape est cruciale pour garantir la fluidité des échanges de données entre les étapes de collecte, d’ingestion, de traitement et d’analyse.
Gouvernance des données : Chaque module doit être conçu avec des mécanismes de gouvernance (governance by design) pour assurer l’intégrité, la qualité et la conformité des données à chaque étape : gestion des métadonnées, contrôle des versions, audit, …
Sécurité : Vous devez intégrer un système de contrôle de sécurité adapté à la nature des données traitées dans chaque module. Par exemple, les modules de collecte de données ont besoin de sécurisation des données en transit, tandis que ceux impliqués dans le stockage se concentrent sur chiffrement des données froides.
Les meilleures pratiques pour la conception de systèmes modulaires
Conception granulaire : Vous devez penser vos modules autour des fonctionnalités de données spécifiques attendues, en veillant à ce qu’ils soient suffisamment indépendants pour être mis à jour ou remplacés sans perturber le pipeline global.
Flexibilité et évolutivité : Vous devez concevoir des modules qui peuvent être facilement mis à l’échelle ou modifiés pour s’adapter à l’évolution des données, comme l’ajout de nouveau formats de données ou l’extension des capacités d’analyse sur des volumes étendus.
Cohérence et normalisation : Vous devez tendre vers des standards pour la conception des interfaces des modules et la structuration des données, ce qui simplifiera l’ajout et l’harmonisation de modules additionnels et l’adoption de nouvelles technologies dans le futur.
6. Tendances Futures et Prédictions
À l’heure où l’IA et l’apprentissage automatique redessine notre monde et nourrisse l’ingénierie de la Data, l’architecture de données modulaire vraisemblablement connaitre aussi des transformations majeures à court terme.
Intégration approfondie de l’IA : Les modules d’IA seront de plus en plus élaborés, capables d’effectuer non seulement des analyses de données, mais aussi de prendre des décisions autonomes sur la manière de les traiter et de les stocker. L’auto-optimisation des pipelines de données basée sur des modèles prédictifs pourra augmenter l’efficacité et réduire les coûts opérationnels. Ils pourront identifier des modèles complexes indétectables par des analyses traditionnelles.
Apprentissage automatique en tant que service : L’architecture de données modulaire incorporera surement des modules d’apprentissage automatique en tant que service (MLaaS), permettant une scalabilité et une personnalisation accrues. Ces services seront mis à jour régulièrement avec les derniers algorithmes sans redéploiement lourd du système. Ces modules incluront des composants capables d’auto-évaluation et de recalibrage pour s’adapter aux changements de données sans intervention humaine. Par exemple, un module pourra ajuster ses propres algorithmes de traitement de données en fonction de la variabilité des schémas de données entrantes.
Auto-réparation et évolutivité : Les modules seront conçus pour détecter et réparer leurs propres défaillances en temps réel, réduisant ainsi les temps d’arrêt. Avec l’apprentissage continu, ils anticiperont les problèmes avant qu’ils ne surviennent et adapteront leur capacité de traitement selon les besoins.
Interopérabilité avancée : Les futures architectures de données modulaires seront probablement conçues pour interagir sans effort avec une variété encore plus large de systèmes et de technologies, y compris des algorithmes d’IA très élaborés, des modèles de données évolutifs et des nouveaux standards d’interface.
Automatisation de la gouvernance des données : Les modules dédiés à la gouvernance utiliseront l’IA pour automatiser la conformité, la qualité des données et les politiques, rendant la gouvernance des données plus proactive et moins sujette à erreur.
L’architecture de données modulaire va devenir plus dynamique, adaptative et intelligente, tirant parti de l’IA et de l’apprentissage automatique non seulement pour la gestion des données mais pour continuellement s’améliorer et innover dans le traitement et l’analyse des données.
Une architecture de donnée modulaire, en bref.
Une architecture de données modulaire offre aux entreprises une flexibilité sans précédent. Elle permet de gagner en agilité opérationnelle car elle a la capacité de se dimensionner et de s’ajuster aux changements qu’ils soient métiers ou technologique sans impact négatif sur le système existant. Cette approche par composants autonomes permet une meilleure gestion du pipeline de données et une évolutivité des systèmes inégalées. Les coûts et les interruptions liés à l’évolution technologique s’en trouvent drastiquement réduits. En outre, l’architecture modulaire est conçue pour intégrer facilement les dernières innovations comme l’intelligence artificielle et le machine learning. Des bases solides en sommes pour soutenir votre transformation digitale et votre croissance sur vos marchés.
Quelques solutions pour vous accompagner dans cette transition technologique
Databricks – Pour une plateforme unifiée, offrant une analyse de données et une IA avec une architecture de données modulaire au cœur de sa conception.
Snowflake – Offre une architecture de données dans le cloud conçue nativement pour être flexible et l’évolute, permettant aux entreprises de s’adapter rapidement aux besoins et aux demandes changeantes des métiers et des marchés.
GoogleCloudPlatform – Avec BigQuery, une solution puissante pour une gestion de données modulaire, permettant une analyse rapide et à grande échelle.
Recrutement
Quel est l’arsenal d’un spécialiste Data ?
0 commentaires
Un couteau suisse … de compétences.
Alors que les data sont devenues les nouveaux gisements de pétrole de notre ère numérique, les entreprises ont besoin crucial de professionnels capables de les extraire, les interpréter, les gérer et les sécuriser.
Chez Smartpoint, nous savons que l’excellence dans le domaine de la data ne repose pas sur une compétence unique mais sur un large spectre de talents diversifiés. C’est notre richesse et ce qui fait de nous un pure-player reconnus dans le domaine de la data depuis près de 20 ans.
La polyvalence, c’est la clé.
Nos consultants en Business Intelligence, ingénieurs data, analystes de données, business analystes, architectes data et data scientists – tous doivent maîtriser de larges domaines de compétences en constante évolution.
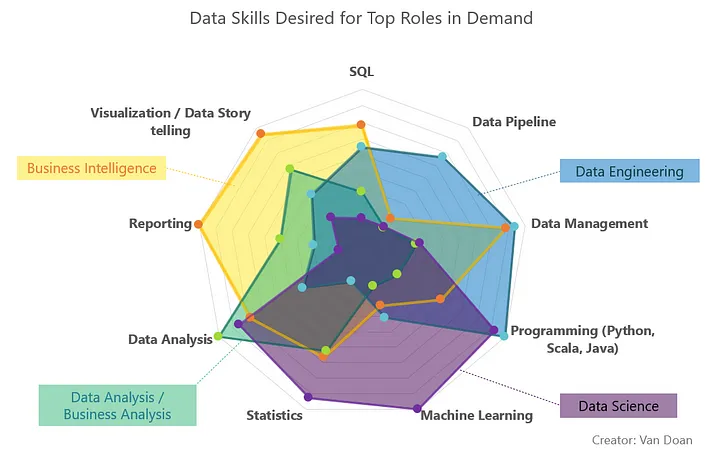
Leur dénominateur commun ? Ils ont tous des bases solides en programmation car c’est essentiel. Qu’il s’agisse de maîtriser le SQL pour les requêtes de bases de données, de programmer en Python pour développer des algorithmes, ou de posséder un sens de lecture aiguisé pour la visualisation de données et le storytelling, la variété des tâches est notre quotidien.
Un large de spectre de compétences data en réponses à de fortes exigences.
L’infographie ci-dessus démontre qu’aucun rôle dans l’univers de la data n’est à l’abri de la diversité des savoir-faire. SQL, pipelines de données, engineering, management, analyse, statistiques, machine learning : Il ne s’agit que d’outils de notre arsenal chez Smartpoint.
Nous ne nous contentons pas de collecter les données ; nous les façonnons en histoires, nous les traduisons en décisions stratégiques, et nous les sécurisons comme les actifs les plus précieux de nos clients.
L’approche Smartpoint, la valorisation de la diversité d’expertises.
Chez Smartpoint, chaque professionnel est reconnu pour sa capacité à jongler avec une gamme étendue de compétences tout en approfondissant son expertise dans des domaines spécifiques. Cette richesse d’expertises contribue non seulement à notre propre valeur ajoutée parmi nos comparables ESN mais renforce aussi la qualité des solutions que nous apportons à nos clients. C’est cette diversité qui fait de notre équipe une communauté unique déchiffreur de problèmes, d’innovateurs et même de conteurs.
Vers une ère data, plus responsable et l’éthique
Chez Smartpoint, nous connaissons l’importance capitale d’une exploitation data qui est de plus intelligente et … autonome d’où la nécessité d’intégrer des fondements éthiques — C’est une responsabilité que nous assumons avec la plus grande rigueur.
Lorsqu’il s’agit de conseiller nos clients, nous mettons un point d’honneur à allier éthique, innovation et recherche de leviers d’économie. Nous prônons des stratégies data et des technologies qui vont au-delà de la conformité et s’inscrivent dans une logique de gestion optimisée des ressources.
Nous recommandons notamment des architectures de données qui permettent l’optimisation des ressources et la sobriété énergétique avec des processus rationalisés, incarnés par des systèmes agiles fondés sur les microservices. Ces systèmes, par leur design, visent à réduire l’empreinte énergétique et offrent une gestion simplifiée ainsi qu’une réutilisation stratégique des composants, entraînant une diminution significative des dépenses.
Adoptant le principe de « Sustainability by design », nous accompagnons nos clients dans leurs choix technologiques afin de capitaliser sur leur stack actuelle ou en choisissant des produits dont la valeur ajoutée est éprouvée. Chaque solution que nous mettons en œuvre est analysée sous l’angle de son rendement à long terme, son coût opérationnel et son Total Cost of Ownership (TCO), en mettant un accent particulier sur la fiabilité opérationnelle et la constance des performances sur la durée.
Smartpoint est plus qu’une entreprise ; c’est un écosystème où la diversité des compétences et des personnes crée une synergie qui propulse la valeur des données mais aussi celles des individus ! Nous vous invitons à rejoindre notre mission : ensemble, façonnons un monde orienté data qui a du sens, plus éthique et plus responsable. Rejoignez Smartpoint, là où votre polyvalence et votre passion pour les données deviennent les moteurs du changement.