
Architecture
Quelles architectures de Real-time data processing pour avoir une vision immédiate ?
Dans un monde de plus en plus interconnecté où la rapidité et l’agilité sont facteurs de succès pour les organisations, le traitement des données en temps réel n’est plus un luxe mais une nécessité. Les entreprises ont besoin d’une vision immédiate de leur data pour prendre des décisions éclairées et réagir en temps réel aux événements marché. Le traitement des données en temps réel devient alors un enjeu crucial pour rester compétitif.
Chez Smartpoint, nous concevons des architectures permettant aux entreprises de réagir instantanément aux données entrantes, assurant ainsi un véritable avantage compétitif sur des marchés qui demandent de la réactivité.
1. Fondamentaux des architectures temps réel
Le traitement des données en temps réel se définit comme la capacité à ingérer, traiter et analyser des données au fur et à mesure qu’elles sont générées, sans délai significatif. Cela permet d’obtenir une vue actualisée en permanence de l’activité de l’entreprise et de réagir instantanément aux événements. C’est une réponse directe à l’éphémère « fenêtre d’opportunité » où les données sont les plus précieuses.
Définition et Composants Clés
Des collecteurs de données aux processeurs de streaming, en passant par les bases de données en mémoire, chaque composant est optimisé pour plus de vitesse et d’évolutivité.
La réactivité, la résilience et l’élasticité sont les principes fondamentaux de conception de ce type d’architecture. Cela implique des choix technologiques robustes et une conception architecturale qui peut évoluer dynamiquement en fonction du volume des données. Une architecture de Reel-time data processing a une forte tolérance aux pannes, sans perte de données afin d’être en capacités de reprendre le traitement là où il s’était arrêté, garantissant ainsi l’intégrité et la continuité des opérations.
Plusieurs architectures de données peuvent être utilisées pour le traitement en temps réel, chacune avec ses avantages et ses inconvénients :
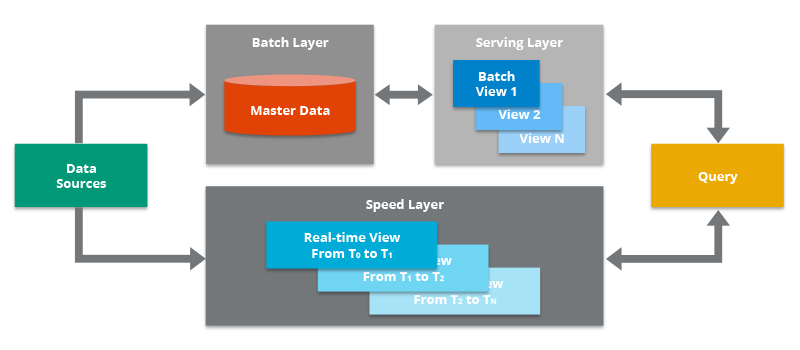
1.1 Lambda Architecture
- Principe : Deux pipelines distinctes traitent les données en temps réel et en batch. La pipeline temps réel offre une faible latence pour les analyses critiques, tandis que le pipeline batch assure la cohérence et la complétude des données pour des analyses plus approfondies.
- Technologies : Apache Kafka, Apache Spark, Apache Hadoop Hive, Apache HBase
- Outils : Apache Beam, Amazon Kinesis, Google Cloud Dataflow
- Avantages : Flexibilité, scalabilité et capacité à gérer des volumes de données importants.
- Inconvénients : Complexité de la mise en œuvre et coûts de maintenance élevés.
- Cas d’utilisation : Détection de fraude en temps réel dans les transactions financières.
- Pipeline temps réel : Apache Kafka ingère les transactions, Apache Spark les analyse pour détecter les anomalies.
- Pipeline batch : Apache Hadoop Hive stocke et analyse les données historiques pour identifier les patterns de fraude.
- Exemple : PayPal utilise une architecture Lambda pour détecter les fraudes en temps réel.
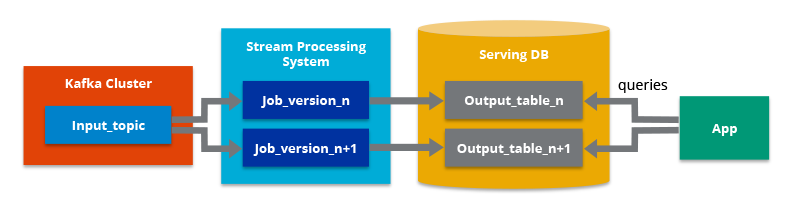
1.2 Kappa Architecture
- Principe : Unification du traitement des données en temps réel et en batch en un seul pipeline. Cette approche simplifie l’architecture et réduit les coûts de maintenance.
- Technologies: Apache Flink, Apache Kafka, Apache Pinot
- Outils: Apache Beam, Amazon Kinesis, Google Cloud Dataflow
- Avantages : Simplicité, évolutivité et coûts réduits.
- Inconvénients : Latence plus élevée pour les analyses critiques et complexité du traitement des données historiques.
- Cas d’utilisation : Analyse des clics en temps réel sur un site web e-commerce.
- Pipeline unifiée : Apache Flink ingère et traite les flux de clics en temps réel, Apache Pinot permet des analyses ad-hoc et des tableaux de bord.
- Exemple : Netflix utilise une architecture Kappa pour analyser les clics et les interactions des utilisateurs en temps réel.
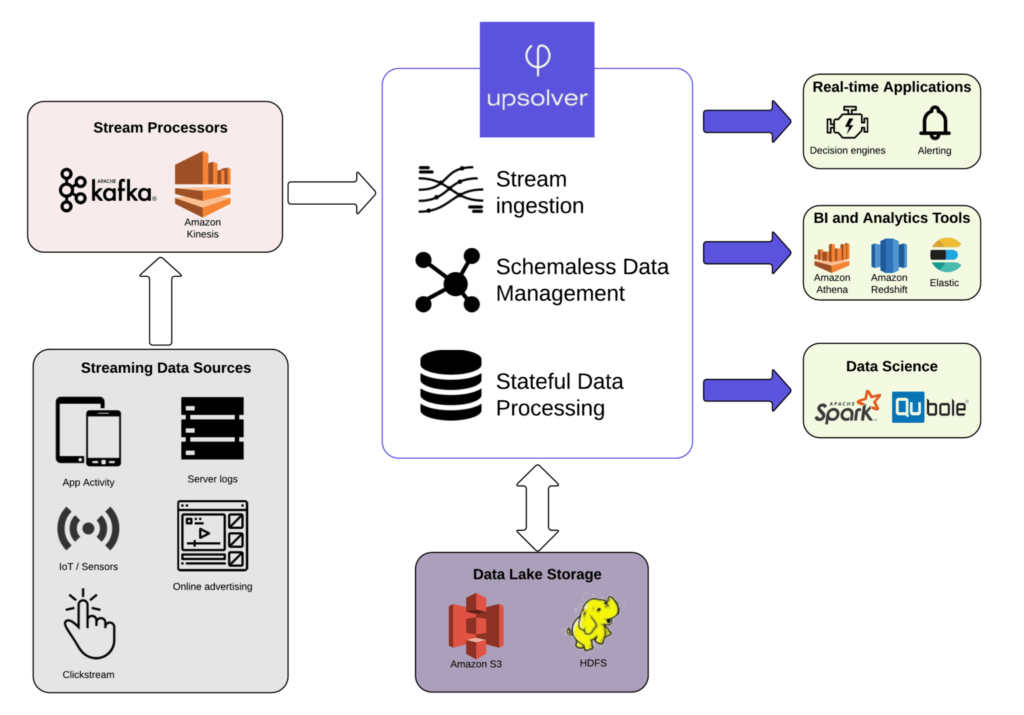
1.3 Architectures basées sur les flux de données
- Principe : Se concentrent sur le traitement des données en temps réel en tant que flux continus. Cette approche offre une grande flexibilité et permet de réagir rapidement aux changements dans les données.
- Technologies
- : Apache Kafka, Apache Storm, Apache Flink
- Outils : Apache Beam, Amazon Kinesis, Google Cloud Dataflow
- Avantages : Flexibilité, scalabilité et adaptabilité aux nouveaux types de données.
- Inconvénients : Complexité de la mise en œuvre et nécessité d’une expertise en streaming de données.
- Cas d’utilisation : Surveillance des performances du réseau informatique en temps réel.
- Technologie : Apache Kafka ingère les données des capteurs réseau, Apache Storm les traite pour détecter les anomalies et les visualiser en temps réel.
- Exemple : Amazon utilise des architectures basées sur les flux de données pour surveiller ses infrastructures en temps réel.
1.4 Architectures hybrides
- Architecture Lambda++ : Combine les avantages des architectures Lambda et Kappa pour une meilleure flexibilité et évolutivité.
- Apache Beam : Plateforme unifiée pour le traitement des données en temps réel et en batch.
2. Comment choisir la bonne architecture ?
Le choix de l’architecture de données pour le traitement en temps réel dépend de plusieurs facteurs :
- Nature des données: Volume, variété, vélocité et format des données à traiter.
- Cas d’utilisation : Besoins spécifiques en termes de latence, de performance et de complexité des analyses.
- Compétences et ressources disponibles : Expertises en interne ou recourt à une cabinet spécialisé comme Smartpoint et budget alloué à la mise en œuvre et à la maintenance de l’architecture.
| Architecture | Latence | Performance | Scalabilité | Coût |
| Lambda | Haute | Bonne | Bonne | Élevé |
| Kappa | Faible | Bonne | Bonne | Moyen |
| Streaming data architecture | Faible | Excellente | Excellente | Variable |

Cas d’usages
Amélioration de l’expérience client
Par exemple, la capacité à réagir en temps réel aux comportements peut transformer l’expérience utilisateur, rendant les services plus réactifs et les offres plus personnalisées.
Optimisation opérationnelle
La maintenance prédictive, la détection des fraudes, et l’ajustement des inventaires en temps réel sont d’autres exemples d’opérations améliorées par cette architecture.
3. Technologies et outils pour le traitement en temps réel
Kafka et Stream Processing
Apache Kafka est une référence pour la gestion des flux de données en temps réel, souvent associé à des outils comme Apache Storm ou Apache Flink pour le traitement de ces flux.
Base de données en mémoire
Des technologies comme Redis exploitent la mémoire vive pour le traitement et des accès ultra-rapides aux données.
Frameworks d’Intelligence Artificielle
Des frameworks comme TensorFlow ou PyTorch sont employés pour inférer en temps réel des données en mouvement, pour des résultats immédiats.
4. Cas Pratiques par Secteur
- Finance : Détection de fraude en millisecondes pour les transactions de marché.
- E-commerce : Mise à jour en temps réel des stocks et recommandation de produits personnalisés.
- Télécommunications : Surveillance de réseau et allocation dynamique des ressources pour optimiser la bande passante.
- Santé : Surveillance en temps réel des signes vitaux pour une intervention rapide en cas d’urgence.

La complexité de l’ingénierie, la nécessité d’une gouvernance des données en temps réel, la gestion de la cohérence, la sécurité et les règlementations sont des défis de taille à intégrer. Smartpoint, à travers ses conseils et son expertise technologique, accompagne les CIO pour transformer ces défis en opportunités.
— Yazid Nechi, Président, Smartpointt
Et demain ?
Les architectures de Reel-time data processing sont amenées a évoluer rapidement, alimentées par l’innovation technologique et les besoins accrus des entreprise pour du traitement temps réel des données. Avec l’avènement de l’IoT, l’importance de la cybersécurité devient centrale, nous amenant à adopter des protocoles plus solides et à intégrer l’IA pour une surveillance proactive. L’informatique quantique, bien que encore balbutiante, promet des avancées considérables dans le traitement de volumes massifs de données, tandis que l’apprentissage fédéré (federeted learning) met l’accent sur la confidentialité et l’efficacité de l’apprentissage automatique.
Des outils comme DataDog et BigPanda soulignent la pertinence de l’observabilité en temps réel et de l’analyse prédictive, et des plateformes telles qu’Airbyte montrent l’évolution vers des solutions de gestion de données sans code.
À mesure que ces tendances gagnent en importance, Smartpoint se prépare à un data world où l’agilité, la sécurité et la personnalisation seront les clés de voûte des infrastructures de données temps réel de demain, redéfinissant la réactivité et l’efficacité opérationnelle de tous les secteurs d’activité.
Sources et pour aller plus loin :
- Apache Lambda: https://www.databricks.com/glossary/lambda-architecture
- Apache Kafka: https://kafka.apache.org/21/documentation/streams/architecture.html
- Apache Spark: https://www.interviewbit.com/blog/apache-spark-architecture/
- « Real-Time Data Processing Architectures »: https://www.tinybird.co/blog-posts/real-time-streaming-data-architectures-that-scale
- « Kappa Architecture »: https://hazelcast.com/glossary/kappa-architecture/
- « Lambda Architecture »: https://www.databricks.com/glossary/lambda-architecture
Livres:
- « Real-Time Data Analytics: The Next Frontier for Business Intelligence » by Thomas Erl, Zaigham Mahmood, and Ricardo Puttini
- « Building Real-Time Data Applications with Azure » by Steve D. Wood
Vous vous interrogez sur quelle architecture data adopter ? Challengez-nous !
Les champs obligatoires sont indiqués avec *.