IA
L’IA est partout et à écouter certains, l’IA finirait par remplacer une grande partie des métiers IT dont celui de data engineer. Après tout, si un modèle peut écrire du code, orchestrer des workflows et “comprendre” les données, pourquoi maintenir une équipe d’ingénierie coûteuse ?
Pourtant chez Smartpoint, nous constatons que l’IA n’est pas prête à remplacer le data engineering ! Au contraire, elle le rend encore plus indispensable. La nouvelle génération d’architecture data est distribuée et plus les usages IA se multiplient, plus la dépendance au socle data est forte et la mise en production complexe.
L’IA est dépendante du data engineering.
Imaginez un pilote de Formule 1 au volant d’un bolide capable de calculer en temps réel chaque trajectoire, chaque freinage, chaque accélération. Mais supposons que son tableau de bord affiche des données approximatives comme une vitesse retardée de cinq secondes, un niveau de carburant pas fiable ou des voyants d’alertes incohérents. Même si le pilote est équipé du meilleur algorithme au monde, il va terminer dans le décor. L’intelligence artificielle, c’est pareil : sans données fiables, c’est un géant aux pieds d’argile.
60% des projets d’IA dépourvus de données prêtes à l’emploi seront abandonnés. Gartner 2025
Gartner 2025
L’IA n’est pas capable de tout comprendre, de tout prédire ni de tout automatiser. Elle ne crée pas les données, elle les consomme. Et sa performance dépend de la qualité de ce qu’on lui fournit. Fraîcheur, cohérence, traçabilité, historisation, disponibilité à l’échelle… Chaque projet d’IA est un véritable challenge en ingénierie des données. Car le problème n’est pas l’algorithme mais les données.
95 % des projets pilotes d’IA générative en entreprise échouent, en raison de difficultés de développement en interne, d’objectifs flous, de données de mauvaise qualité et d’un engouement excessif
Source
L’épreuve de la mise en production de l’IA face à la réalité brutale du SI.
Prenez le cas d’une IA dite « temps réel », censée prendre des décisions à la volée. Si les données qui l’alimentent arrivent avec un retard de quelques minutes, voire de quelques heures, elle se base sur une réalité qui n’existe plus.
Pire ? Un modèle entraîné sur des données incohérentes ou biaisées ne se contente pas de mal fonctionner, il amplifie les erreurs souvent de manière exponentielle. Et quid des agents autonomes et leurs promesses d’automatisation intelligente ? Branchez-les sur des flux instables, et vous obtiendrez des décisions erronées… mais prises à une vitesse grand V.
En théorie, tout semble simple. En pratique, l’IA se heurte à la réalité des systèmes d’information. Les schémas de données dérivent sans contrôle, les flux événementiels sont incomplets ou corrompus, les duplications s’accumulent, les pipelines se cassent… Les données manquantes, obsolètes ou incohérentes deviennent autant d’écueils pour des algorithmes pourtant conçus pour faire des miracles.
Le Data Engineering, le mécanicien de l’IA
Dans la réalité des projets IA, ce sont les data engineers qui font en sorte que la réalité soit à la hauteur des POCs. Ils construisent les pipelines, mettent en place les contrôles qualité et s’assurent d’une gouvernance des données à l’échelle. Ils s’assurent que l’IA puisse s’appuyer sur un socle data fiable et solide, condition sine qua non pour qu’elle gagne en autonomie.
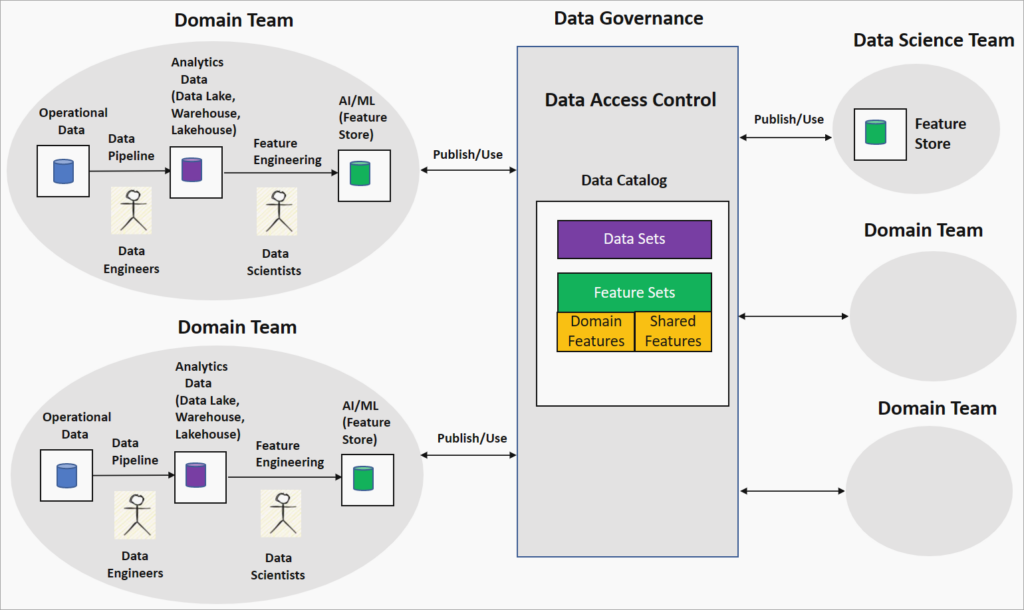
Les nouvelles architectures data consomment davantage de data engineering
Pendant des années les architectures data étaient relativement basiques : un data warehouse, des pipelines batch lancés la nuit, des usages analytiques essentiellement descriptifs. On connaissait le périmètre, les dépendances étaient limitées et la complexité contenue. Ce temps est révolu.
Aujourd’hui, les architectures data se déploient en réseaux distribués, pensés pour l’agilité et la réactivité : Data Mesh et responsabilité par domaine, lakehouses cloud-native, flux événementiels en temps réel, APIs data exposées aux produits, bases vectorielles pour l’IA générative, pipelines hybrides mêlant batch et streaming… Chaque brique est conçue pour répondre à des besoins spécifiques mais ensemble, elles créent une nouvelle complexité. La donnée n’est plus centralisée, elle est partout : chaque domaine en produit, chaque produit en consomme, chaque cas d’usage IA impose ses propres exigences en termes de fraîcheur, de disponibilité et de fiabilité.
Dans ce nouvel écosystème Data éparse et dynamique, le data engineering n’est plus un simple rouage : il est le ciment qui maintient l’ensemble en condition opérationnelle. Son rôle ? Garantir que le socle architectural peut absorber l’hétérogénéité des sources, la distribution des données et la mobilité des environnements. Sans data engineering solide, pas d’IA industrialisable. Plus les architectures se décentralisent, plus le besoin en ingénierie data est fort. Ce qui n’est plus centralisé doit être orchestré, gouverné et observé avec encore plus de rigueur. La complexité ne disparaît pas : elle change de nature et c’est aux data engineers de la maîtriser.
L’IA « supprime » une partie du métier du Data Engineer ?
Oui, si on veut et c’est une bonne nouvelle ! Chez Smartpoint, l’IA commence à nous servir pour automatiser tout un ensemble de tâches particulièrement chronophages et à faible valeur ajoutée pour nos ingénieurs data : génération de pipelines ETL / ELT standards, écriture de transformations SQL ou Spark simples, création de tests de qualité de données, documentation technique automatique, détection de dérives de schémas, génération de DAGs d’orchestration ou encore aide au debugging de pipelines.
Toutes ces tâches ont des points communs et c’est justement pour ces raisons qu’elles sont éligibles à l’automatisation par l’IA : elles sont répétitives, standardisables et fortement outillées. Elles reposent sur des patterns connus, des règles explicites et des chaînes d’exécution prévisibles.
Dans les faits, l’IA prend à sa charge une partie de l’exécution, ce qui permet au data engineer de se concentrer sur les nouvelles tâches que justement les nouvelles architectures data et les nouveaux usages IA attentent de lui : concevoir des architectures cohérentes, arbitrer entre des choix techniques, anticiper les effets de bord et autres dérives, garantir la fiabilité globale d’un système data distribué et maintenir la vision globale dans des environnements en perpétuel mouvement.
Le data engineering « artisanal » avec ses processus répétitifs et peu industrialisés, tend à disparaitre selon nous. La valeur ajoutée de notre métier se concentre désormais sur la conception d’architectures, la résilience opérationnelle et l’industrialisation du SI Data ; des domaines où l’IA agit comme un accélérateur et non comme une solution de remplacement.

Data engineer en 2026 ? le bon profil smartpoint
Le data engineer n’est plus un “producteur de pipelines” mais un expert data polyvalent en charge de la transformation SI Data :
- Architecte de flux distribués : il conçoit des infrastructures scalables, capables de gérer la complexité des données en temps réel et en batch.
- Garant de la cohérence des données : il assure l’intégrité, la traçabilité et la fiabilité des données, du producteur au consommateur.
- Concepteur de plateformes data : il construit des environnements unifiés, optimisés pour l’analyse, le machine learning et l’IA.
- Facilitateur de l’industrialisation IA : il rend possible le déploiement massif et fiable des modèles d’IA en alimentant les LLM et les agents intelligents.
Ses responsabilités :
- Conception de flux d’événements (gestion du temps, des retards, des duplications).
- Alignement batch / streaming pour une cohérence globale.
- Mise en place de l’observabilité data end-to-end pour une transparence totale.
- Gestion des backfills et des replays essentielle à la résilience des systèmes.
- Gouvernance proactive de la qualité et de la sécurité des données.
- Alimentation fiable et optimisée des LLM et des agents IA, pour des applications performantes.
La stack IA du data engineer en 2026
Chez Smartpoint, ESN spécialisée en Data & IA, la bonne stack IA de nos data engineer est celle leur permet d’améliorer et de fiabiliser leur travail au quotidien.
1. Copilotes IA pour le développement data
- Copilot Github : Génération et complétion de code SQL, Python, Spark, dbt, Airflow.
- ChatGPT Enterprise / Azure OpenAI : Assistance à la conception de pipelines, aide au debugging, refactoring Transformation, génération de tests et de la documentation technique.
2. Transformation et modélisation data augmentées par l’IA
- dbt (Cloud) ; Génération de modèles, documentation automatisée, suggestions de tests de qualité.
- Databricks (Lakehouse + Assistant / Genie) : Aide à l’écriture de notebooks, compréhension des jeux de données, optimisation des jobs Spark et SQL.
- Snowflake (Cortex AI) : Génération de requêtes, enrichissement sémantique et exploration guidée des données.
3. Qualité et observabilité data pilotées par l’IA
- Great Expectations : Tests de qualité data, de plus en plus enrichis par des suggestions automatiques.
- Monte Carlo : Détection d’incidents data, l’analyse d’impact et l’alerting intelligent.
- Soda : Qualité et l’observabilité des pipelines.
4. Gouvernance Data et catalogage assistés par l’IA
- Collibra pour le catalogage, la gouvernance et le lineage enrichi.
- DataGalaxy : le catalogage, la documentation et l’appropriation métier.
- Microsoft Purview : Gouvernance et classification automatisée dans Azure.
5. RAG et capitalisation de la connaissance data
- LangChain / LlamaIndex : Construction d’assistants internes (documentation, support data, recherche sémantique).
- Qdrant (open source) : Base vectorielle pour moteurs RAG internes.
Besoin d’un data engineer IA ready ?
L’IA ne permet pas réduire vos équipes data, ni aujourd’hui ni demain. En revanche, c’est clairement un vecteur de réallocation intelligente des ressources.
En automatisant les tâches répétitives du quotidien de l’ingénierie data, elle permet aux data engineers de se concentrer sur ce qui fait réellement la différence : l’architecture, la fiabilité, la gouvernance et l’industrialisation des cas d’usage de l’IA à l’échelle.
À périmètre et budget constants, la promesse n’est pas de “faire moins”, mais de faire mieux en plus effiace. C’est cette capacité à déplacer la valeur, plutôt qu’à chercher des gains « artificiels », qui conditionne le succès durable des stratégies data et IA.
Pour aller plus loin :
- Les raison de l’échec des projets IA analysées
- Will Data engineering be replaced by AI ?
- Data engineers have never been more important, as businesses are starting to find out
Architecture Data IA, modernisation plateforme data, gouvernance des données, analytics avancés ou renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels,
Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.