Architecture

51% des organisations utilisant l’IA déclarent avoir subi au moins un effet négatif et indésirable (mauvaises recommandations, réponses fausses ou hallucinées, erreurs de tarification, etc.). Près d’un tiers des répondants font état de conséquences nuisibles spécifiquement liées à « l’inaccuracy » de l’IA.
Source McKinsey The state of AI in 2025: Agents, innovation, and transformation
L’IA générative n’est pas (encore) un collègue autonome ! Côté propension à halluciner, même sur une tâche cadrée comme le résumé de documents, les écarts entre modèles restent importants. Sur le Hallucination Leaderboard de Vectara (méthodologie HHEM), des modèles se situent autour de ~12% de taux d’hallucination alors que d’autres dépassent 20%. Autrement dit : sans “garde-fous” d’architecture, la dérive n’est pas un bug à la marge, c’est une variable du système.
L’IA en production est loin pour l’instant de « tourner toute seule ». Et l’ « human-on-the-loop », cette revue humaine souvent très coûteuse et difficile à industrialiser, ne suffit pas à rendre le système IA fiable. Tout l’enjeu est de fiabiliser l’IA en production sans exploser les coûts. Et c’est ici que l’architecture RAG (Retrieval-Augmented Generation), pensée en amont du projet, prend tout son sens. Elle permet de limiter les hallucinations, de tracer les sources et d’aligner le comportement du modèle sur les données de l’entreprise plutôt que sur sa seule mémoire statistique. Le principe est de ne pas laisser un LLM « livré à lui-même » mais d’ancrer ses réponses dans une base de connaissance externe.
Mais encore faut-il choisir la bonne architecture RAG pour que l’IA soit exploitable.
Le RAG où comment “ancrer” un LLM dans la réalité
Le RAG consiste à récupérer (retrieve) des éléments pertinents dans une base de connaissance et à les injecter dans le contexte envoyé au LLM pour générer (generate) une réponse plus fiable. Cette approche a été formalisée et nommée “RAG” dans les travaux fondateurs de Lewis et al. (2020), qui décrivent le principe d’une mémoire “non paramétrique” consultable au moment de l’inférence : au lieu d’attendre qu’un modèle “se souvienne” de tout, on lui donne accès à des preuves au moment où il répond.
Dans le cas d’une entreprise, la connaissance « utile » concerne le contexte propre à l’organisation : ses contrats, ses processus, son catalogue de produits et de tarifs, les référentiels métiers, la politique de sécurité, etc.
C’est là que le RAG devient une question d’architecture : derrière un schéma simple se cachent des choix importants sur la segmentation, l’indexation, les modes de recherche et l’évaluation.
Le RAG standard, cet incontournable …. mais insuffisant dans la durée
Le “RAG naïf” est l’architecture de base la plus logique : on découpe les documents en chunks (segments), on calcule leurs embeddings, on les indexe dans une base vectorielle, puis on récupère les top-K les plus proches de la requête avant de générer la réponse à partir de ce contexte. C’est un bon point de départ car il est facile à diagnostiquer : si ça se dégrade, on voit vite si le problème vient de la donnée, du chunking, du retrieval, du prompt ou du modèle.
Le problème, c’est qu’en production, ce schéma montre vite ses limites. D’abord, le bruit : des chunks “presque pertinents” remontent et contaminent la réponse. Ensuite, les questions multi-parties : il faut souvent plusieurs preuves, souvent disséminées dans plusieurs sources. Ajoutons les ambiguïtés conversationnelles (“ça”, “le même”, “comme hier”), les trous de couverture (l’information n’existe tout simplement pas dans la base) et surtout le défaut structurel du RAG standard : si le retrieval se trompe, rien ne l’arrête. Le modèle répond quand même et il le fait avec aplomb, et c’est bien le problème !
Résultat ? On “améliore le prompt”, on “change d’embedding”, on “augmente le top-K”… et l’on finit souvent par augmenter les tokens, les coûts et la confusion, sans traiter le vrai sujet : la qualité du retrieval et le contrôle du contexte fourni au modèle.
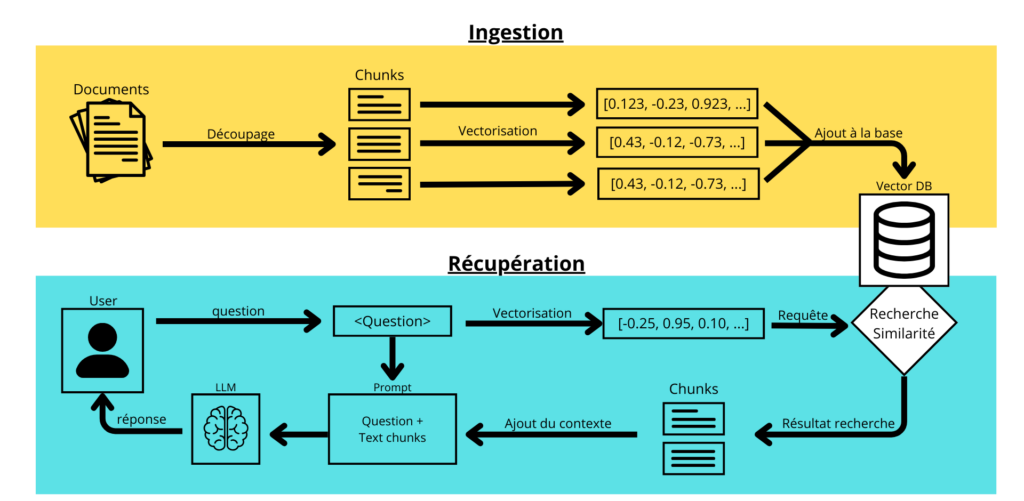
Source : https://datascientist.fr/blog/guide-rag-2025-retrieval-augmented-generation
Architecture RAG « adulte”
Un bon RAG ne cherche pas le bon chunk du premier coup. Il commence par récupérer un ensemble de candidats en masse, puis il prend le temps, au bon endroit, de sélectionner les meilleurs. Cette séparation entre retrieve et rerank est devenue incontournable pour des assistants IA fiables, stables et économiquement tenables.
Concrètement, on “ratisse large” avec une recherche vectorielle, lexicale ou généralement une recherche hybride qui combine mots-clés (type BM25) et similarité sémantique (vecteurs). Dans la pratique, beaucoup de plateformes “enterprise search” généralisent ce couplage : hybrid search, fusion de classements (type RRF), puis reranking sémantique sur une shortlist. C’est un bon compromis entre pertinence, latence et coûts.
Pourquoi ce schéma d’architecture fonctionne ? Parce que le monde réel parle deux langues à la fois. D’un côté, les requêtes “mots-clés” qui doivent matcher exactement : une API, un acronyme, un numéro de ticket, un contrat, un bon de commande. De l’autre, des questions formulées en langage naturel avec synonymes, paraphrases et intention implicite. La recherche hybride évite de manquer le détail qui fait la différence tout en captant l’intention. Et le reranking remet de l’ordre : il re-classe les meilleurs candidats pour remonter les passages réellement exploitables.
Le bénéfice est immédiat : on augmente la pertinence sans faire exploser la latence, car l’étape “coûteuse” n’est exécutée que sur une shortlist. Le piège, lui, reste très classique : activer un reranker “par principe” sans protocole de mesure. Ce qui fait la réelle différence en production repose sur de l’ingénierie : jeux de requêtes représentatifs, métriques de retrieval (precision/recall@k, MRR, nDCG), évaluation bout-en-bout (groundedness, complétude, utilité) et traçabilité des paramètres (chunking, top-k, filtres, modèles, prompts) pour comparer proprement avant/après.
Le RAG conversationnel
Dès qu’on passe en mode assistant, la conversation devient un terrain glissant pour le retrieval. Les utilisateurs parlent en pronoms ou par référence (« çà » , « le même cas », « comme la dernière fois, etc.). Le RAG conversationnel introduit une brique fondamentale, le Query Rewriting, qui permet au LLM de transformer la nouvelle question en requête autonome en s’appuyant sur l’historique récent.
Résultat . une recherche plus stable, moins de contresens, un utilisateur qui n’a plus besoin de répéter. Mais cette mémoire doit être cadrée. Trop d’historique crée de la pollution (memory drift) : un détail d’il y a dix minutes contamine la recherche actuelle. Trop peu provoque l’amnésie. Et la réécriture elle-même doit être évaluée : une “bonne reformulation” peut, parfois, corriger la phrase… en déformant l’intention. Dans un assistant, ce n’est pas un détail : c’est la différence entre une aide et un contresens.
Le RAG adaptatif
Le RAG adaptatif, c’est celui qui a compris que toutes les questions ne méritent pas le même traitement. En production, en enchaine sans distinction des bavardages (“super”, “merci”), des FAQ simples (comme où trouver le process X ou Y) et des questions beaucoup plus complexes (preuves multi-sources, filtres sensible, contraintes de droits, outils externes). Traiter tout ça avec le même pipeline, C’est comme lancer un mode ‘enquête’ pour une question de FAQ : beaucoup d’effort pour très peu d’information. Du full RAG pour écraser une mouche !
Le principe du RAG adaptatif est simple, un routeur (classificateur léger ou LLM) évalue l’intention et dose l’effort. Pour certains échanges, on répond sans retrieval. Pour une question factuelle simple, on déclenche un RAG standard rapide. Et pour les cas complexes, on active un parcours “riche” : hybrid search, reranking, multi-requêtes, voire orchestration d’outils. À l’échelle, c’est l’un des leviers les plus rentables, parce qu’il évite de payer du retrieval (et encore plus du reranking) quand cela n’apporte rien, tout en réservant la cavalerie aux questions qui le méritent vraiment.
Mais comme souvent, le diable est dans le détail… Un mauvais routage casse tout. Si une question difficile est classée comme “simple”, on obtient une réponse fragile ; et l’erreur a l’air de venir du modèle alors qu’elle vient du choix d’architecture. D’où la règle : le RAG adaptatif ne se pilote pas au feeling. Il se pilote avec un jeu de requêtes représentatif, des métriques de pertinence et une évaluation continue des décisions du routeur.
Le RAG correctif (CRAG)
Quand les enjeux sont importants, on ne peut pas se satisfaire de “croiser les doigts” en espérant que le retrieval tombe juste. Conformité, finance, opérations critiques, décisions engageantes, (…), il ne s’agit pas de répondre vite mais de s’assurer que ce qu’on a retrouvé est réellement exploitable. CRAG (Corrective Retrieval Augmented Generation) formalise cela : avant de générer, le système évalue la qualité du contexte récupéré, puis adapte son comportement selon un niveau de confiance. Si les passages sont solides, on avance. S’ils sont incomplets, ambigus ou hors sujet, on filtre, on complète, on relance la recherche, et, si nécessaire, on élargit vers d’autres sources quand la base interne ne couvre pas le besoin.
CRAG transforme une habitude artisanale, “on vérifie à la main”, en mécanisme industrialisable. C’est une vraie barrière de sécurité contre les hallucinations qui ne viennent pas du modèle, mais d’un retrieval imparfait. Oui, cela ajoute de la latence et un peu de complexité. Mais en production, c’est un arbitrage à faire : mieux vaut payer quelques centaines de millisecondes de contrôle que le coût d’une réponse fausse, formulée avec assurance… puis recyclée partout. Luc Doladille – Directeur Conseil & Delivery
L’Agentic RAG
L’Agentic RAG c’est encore un cran au-dessus. La recherche n’est plus un “lookup” déclenché une fois, c’est une orchestration. Un agent piloté par LLM raisonne étape par étape, décide quand et comment appeler le retrieval comme un outil parmi d’autres (API, calculs, règles métier). Certaines requêtes demandent de décomposer, croiser, itérer, vérifier. Dans ces cas-là, l’agent choisit quand récupérer et comment le faire pendant l’interaction, puis synthétise à partir d’éléments consolidés.
Mais il y a une règle simple : pas d’agentic sans base solide. Si les fondamentaux RAG ne tiennent pas la route (corpus, chunking, index, retrieval, évaluation), l’agent ne corrige pas le chaos : il l’amplifie.
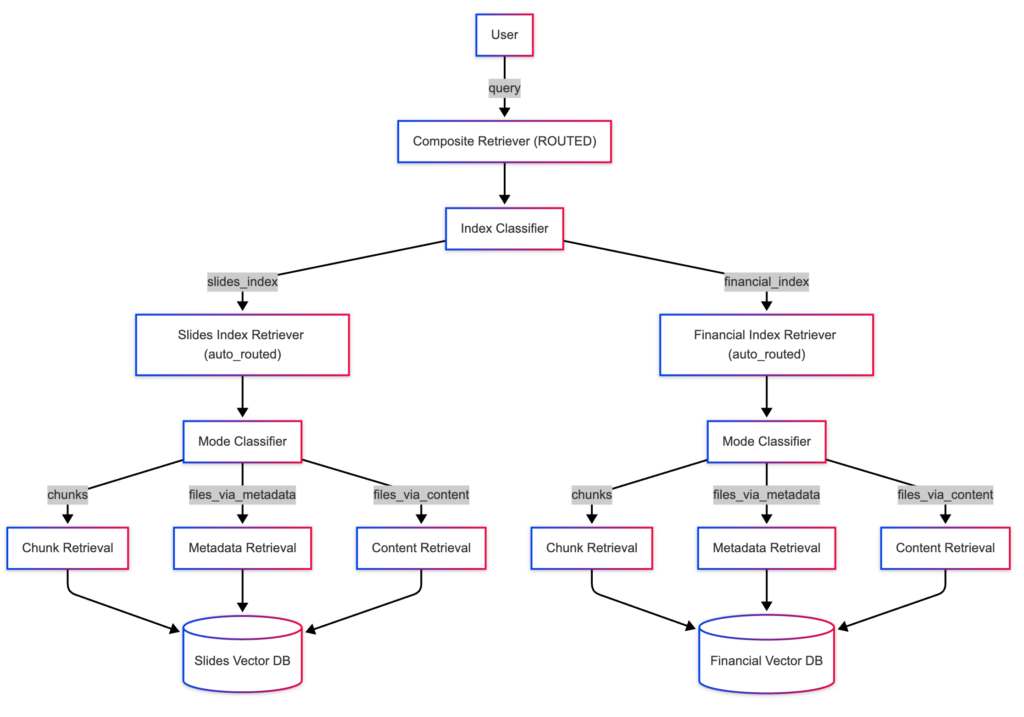
Source https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
Graph RAG
GraphRAG s’attaque à la limite du RAG “tout vectoriel” : la similarité sémantique retrouve des passages qui “ressemblent” mais elle ne garantit pas de reconstruire un raisonnement. En effet, dans de nombreuses entreprises, ce qui compte n’est pas uniquement ce qui est dit, mais ce qui est lié à quoi : dépendances applicatives, chaîne de responsabilité, impacts réglementaires, relations client-fournisseur, causes et effets.
Le principe de GraphRAG est de raisonner en relations plutôt qu’en ressemblances. Au lieu de demander “quel texte ressemble à ma question ?”, le système structure une partie de la connaissance en graphe. Les entités deviennent des nœuds (personnes, applications, services, contrats, politiques, concepts), les relations deviennent des « arête »s (“dépend_de”, “affecte”, “autorise”, “interdit”, “régulé_par”, etc.). À la requête, GraphRAG identifie les entités clés, puis parcourt les chemins les plus pertinents pour reconstituer une chaîne explicable (qui dépend de quoi, quel changement impacte quoi, quelles règles s’appliquent, où sont les exceptions).
GraphRAG est particulièrement efficace dès que l’utilisateur pose des questions multi-hop : “si je change ce paramètre, quelles équipes et quels services sont impactés ?”, “quelles obligations s’appliquent à ce traitement dans ce pays et pour ce type de client ?”. En revanche, GraphRAG nécessite un effort de modélisation, d’extraction d’entités, de gouvernance et de maintien dans le temps. C’est une architecture à privilégier quand la valeurattendue est dans les liens et où l’explicabilité compte autant que la précision.
À quoi ressemble un RAG “industrialisable” ?
Un RAG est une chaîne complète conçue comme un système : on prépare la connaissance, on l’indexe, on organise la récupération et le classement, on contraint la génération puis on mesure et on itère. C’est cette continuité, du document source jusqu’au comportement observé, qui fait la différence entre un assistant “impressionnant” et un assistant “exploitable”.
On commence classiquemenyt par l’ingestion et la préparation de la connaissance. Une base RAG n’est utile que si elle est propre, gouvernée et maintenable : nettoyage, dédoublonnage, versioning, métadonnées exploitables (source, date, périmètre, confidentialité, BU, produit, pays). La segmentation n’est pas un détail technique, elle conditionne la pertinence du retrieval, la capacité à citer correctement et la stabilité des réponses quand le corpus évolue.
Vient ensuite l’indexation (double). Les utilisateurs cherchent enn effet à la fois des mots exacts et des formulations naturelles. C’est pourquoi on retrouve fréquemment un index lexical de type BM25 et un index vectoriel basé sur des embeddings, parfois réunis dans un même moteur via une recherche hybride. L’objectif n’est pas de choisir entre “keyword” et “sémantique”, mais d’éviter de perdre l’un ou l’autre.
La troisième brique, c’est le retrieval et le ranking : hybrid search, fusion de classements, reranking sur shortlist, filtres par métadonnées, gestion stricte des droits. Un RAG industrialisable sait récupérer… mais il sait surtout récupérer juste, et le prouver.
La génération, enfin, doit être cadrée : style, prudence, règles de non-invention, formats utiles (étapes, procédures, décisions argumentées, tableaux) et capacité à dire “je ne sais pas” quand le corpus ne couvre pas l’information. Et surtout un RAG industrialisable est observable. Sans traces, sans métriques et sans boucle de pilotage, on navigue à l’instinct — et l’instinct ne scale pas. On suit la latence, les coûts, la qualité, les dérives, les échecs de recherche, les prompts effectifs, et les variations liées aux changements de corpus ou de modèles. C’est le socle LLMOps du système : ce qui permet d’améliorer sans casser, de corriger sans régresser, et de tenir dans la durée.
En 2026, le vrai sujet n’est plus “faire du RAG” mais “opérer un RAG”
le RAG n’est pas un gadget, ni un bonus “prompt + vecteurs” qu’on ajoute en fin de projet. C’est une architecture de mise en production de l’IA générative avec des choix structurants, des arbitrages et des responsabilités. Et les systèmes qui tiennent dans la durée ne sont pas ceux qui empilent des briques, mais ceux qui savent concevoir puis piloter : choisir l’architecture adaptée au besoin, mesurer la pertinence et la dérive, corriger ce qui doit l’être, sécuriser ce qui doit l’être, et organiser l’exploitation au quotidien (cadence, qualité, coûts, conformité, traçabilité).
Il ne s’agit pas d’avoir un RAG “plus intelligent”, il doit être gouverné, mesuré et opéré pour transformer la promesse de l’IA en capacité industrielle.
Si vous voulez passer de la démo / POC à un dispositif fiable, stable et économiquement tenable, Smartpoint peut vous aider à cadrer la trajectoire : diagnostic de maturité, choix d’architecture, protocole d’évaluation, mise en place de l’observabilité et du run. Parce qu’au fond, la vraie question n’est plus “Est-ce que ça marche ?”, mais “Est-ce que ça marche encore… quand tout le monde l’utilise ?”.
Architecture Data, outils BI / IA, modernisation BI, renfort projet : que vous cherchiez un partenaire conseil ou des experts opérationnels,
Smartpoint vous accompagne, en mission comme en expertise.
Les champs obligatoires sont indiqués avec *.
Sources :
Questions fréquentes
Quelles architectures RAG sont les plus courantes en entreprise ?
RAG standard + retrieve & rerank (souvent hybride), RAG conversationnel pour les assistants, et RAG adaptatif pour optimiser coûts/latence.
Quand faut-il ajouter un mécanisme correctif (CRAG) ?
Dès que l’enjeu est élevé (conformité, finance, opérations critiques) ou que la base de connaissance est incomplète/volatile.
GraphRAG remplace le RAG classique ?
Non. C’est une option pour les cas relationnels/multi-hop, mais plus coûteuse à construire et maintenir.
Pourquoi le hybrid search est-il si important ?
Parce qu’en entreprise, les requêtes mélangent vocabulaire naturel et termes exacts (codes, références) ; l’hybride combine les deux signaux.
Le RAG supprime-t-il les hallucinations ?
Il les réduit fortement, mais ne les “supprime” pas : la qualité du retrieval, l’évaluation et les garde-fous restent indispensables.