Phénomène

On constate que la taille des équipes Data au sein des organisations ne cesse de croitre, comme si elle était proportionnelle à la complexité et au volume croissant des données à exploiter.
Sur le papier, cela peut sembler cohérent car, à l’échelle, les données sont en effet plus complexes. Affecter plus de ressources dédiées, c’est plus d’informations collectées, plus d’analyses, plus de modèles de ML, plus de données restituées pour mieux piloter ou enrichir vos applicatifs.
Mais cela génère aussi plus de complexité, de dépendances, d’exigences mais aussi d’incohérences et de nouveaux problèmes !
L’impact de la taille des équipes data sur l’efficacité
- Une petite équipe, c’est des ressources plus limitées mais cela a l’avantage de faciliter les choses ! Tout le monde se connait et appréhende les compétences de chacun. Il est plus facile de mettre en place une méthode de travail et de l’appliquer. Chacun maîtrise la data stack utilisée et si il y a un dysfonctionnement quelque part, c’est relativement rapide de l’identifier et de le régler.
- Au-delà de 10 personnes au sein de l’équipe data, cela se complique ! On commence à avoir des doutes sur la fiabilité des données qu’on utilise, le data lineage (traçabilité des données / data catalog) commence à être trop important pour avoir encore du sens … et les sources d’insatisfactions chez les utilisateurs métiers se multiplient.
- Sur des très grosses équipes, cela devient critique ! Nous voyons cela chez nos clients où on dépasse désormais souvent 50 collaborateurs ! Personne ne se connait vraiment, il y a eu du turn-over inéluctable, on ne maîtrise plus vraiment la data stack car chacun y a contribué sans vraiment prendre le temps de documenter quoi que ce soit ni de comprendre l’historique. Les initiatives individuelles se sont multipliées pour satisfaire ponctuellement des besoins utilisateurs plus critiques que d’autres. Cela a généré du coding spécifique, difficile à maintenir et encore moins à faire évoluer dans la durée. Le Daily pipeline se termine beaucoup trop tard pour avoir encore du sens.
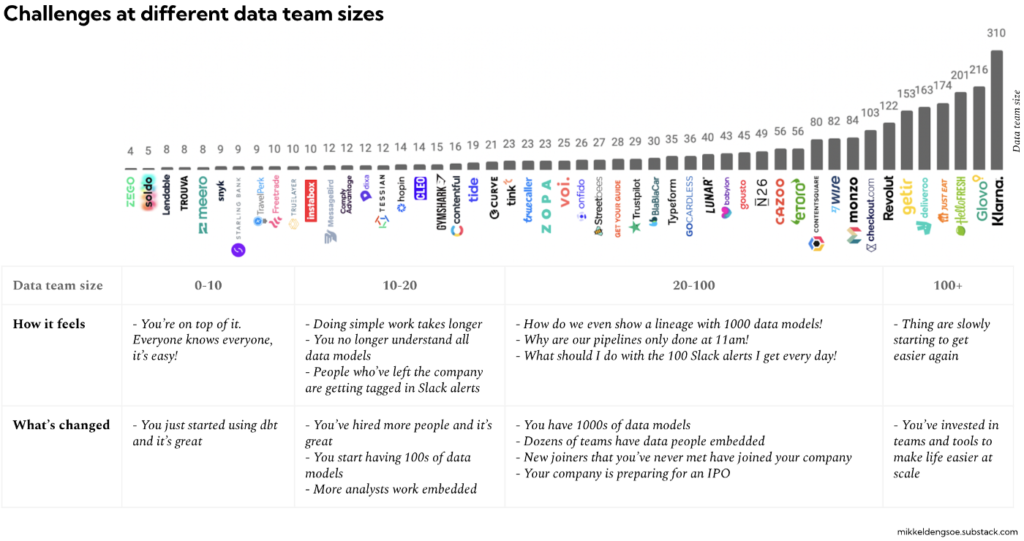
On arrive à un résultat exactement à l’opposé des attentes. Et cela s’explique :
- Le processus permettant la traçabilité des données (data lineage) qui consiste à créer une sorte de cartographie pour recenser l’origine des données, les différentes étapes de transformation et pourquoi elles ont été mis en place ainsi que les différentes évolutions dans la durée … devient ingérable. Pourtant, la visualisation de toute cette arborescence est indispensable pour comprendre toutes les dépendances entre les données et comment elles circulent effectivement. Dès lors qu’on franchit des centaines de modèles de données, le data lineage perd toute son utilité. A cette échelle, il devient impossible de comprendre la logique ni de localiser les goulots d’étranglement.
- Résultat, le pipeline de données fonctionne de plus en plus lentement, il se dégrade inexorablement car il y a trop de dépendances sans compter qu’il y a forcément quelqu’un qui a essayé de colmater des joints quelque part 😉 Et cela a des conséquences : le fameux retour du plat de spaghettis ! Résultats : les données ne sont jamais prêtes dans les temps.
- Les Data Alerts deviennent votre quotidien et vous passez désormais votre temps à essayer de les résoudre sans compter qu’il est difficile de savoir à qui incombe la résolution du problème à la base !
En conclusion.
Votre capacité à exploiter vos données convenablement, même si elles sont de plus en plus volumineuses et complexes, se résume finalement à des enjeux d’ordre davantage organisationnels que techniques. Même si, à ce stade, une véritable solution de Data Catalog s’impose tout de même !
A l’échelle, vous devez composer avec des équipes hybrides qui ont du mal à intégrer comment votre data stack fonctionne. C’est un état de fait contre lequel il est difficile de lutter. Une des solutions consiste à diviser votre team data en plusieurs petites équipes qui seront en charge d’une pile technologique en particulier qu’ils devront pour le coup bien maîtriser, documenter et transmettre lors de l’onboarding de nouvelles équipes : ceux en charge de l’exploration ou de la collecte, ceux en charge de l’analyse, ceux en charge d’optimiser les performances du pipeline, ceux en charge de l’amélioration de l’architecture globale, etc.
C’est notamment pour ces raisons que chez Smartpoint, nous vous proposons d’intervenir en apportant des compétences très pointues : Architectes data, ingénieurs data, data analysts, etc. Nous sommes également une ESN spécialisée en Data avec les capacités de mobiliser en volume des équipes Data qui ont l’habitude de travailler ensemble, selon une méthodologie de travail commune et cela change tout.
Source https://mikkeldengsoe.substack.com/p/data-team-size
